
ZK/Web3转Web2/Agent
正在开发的框架:
https://t.co/xi9lk5Xrk4
coding-agent :
npm i @continue-reasoning/coding
上个版本的框架:
npm i @continue-reasoning/core
 2/5
2/5


 最后还是很喜欢 @KyeGomezB 对待被指责代码不好时的态度
最后还是很喜欢 @KyeGomezB 对待被指责代码不好时的态度 2/4
2/4



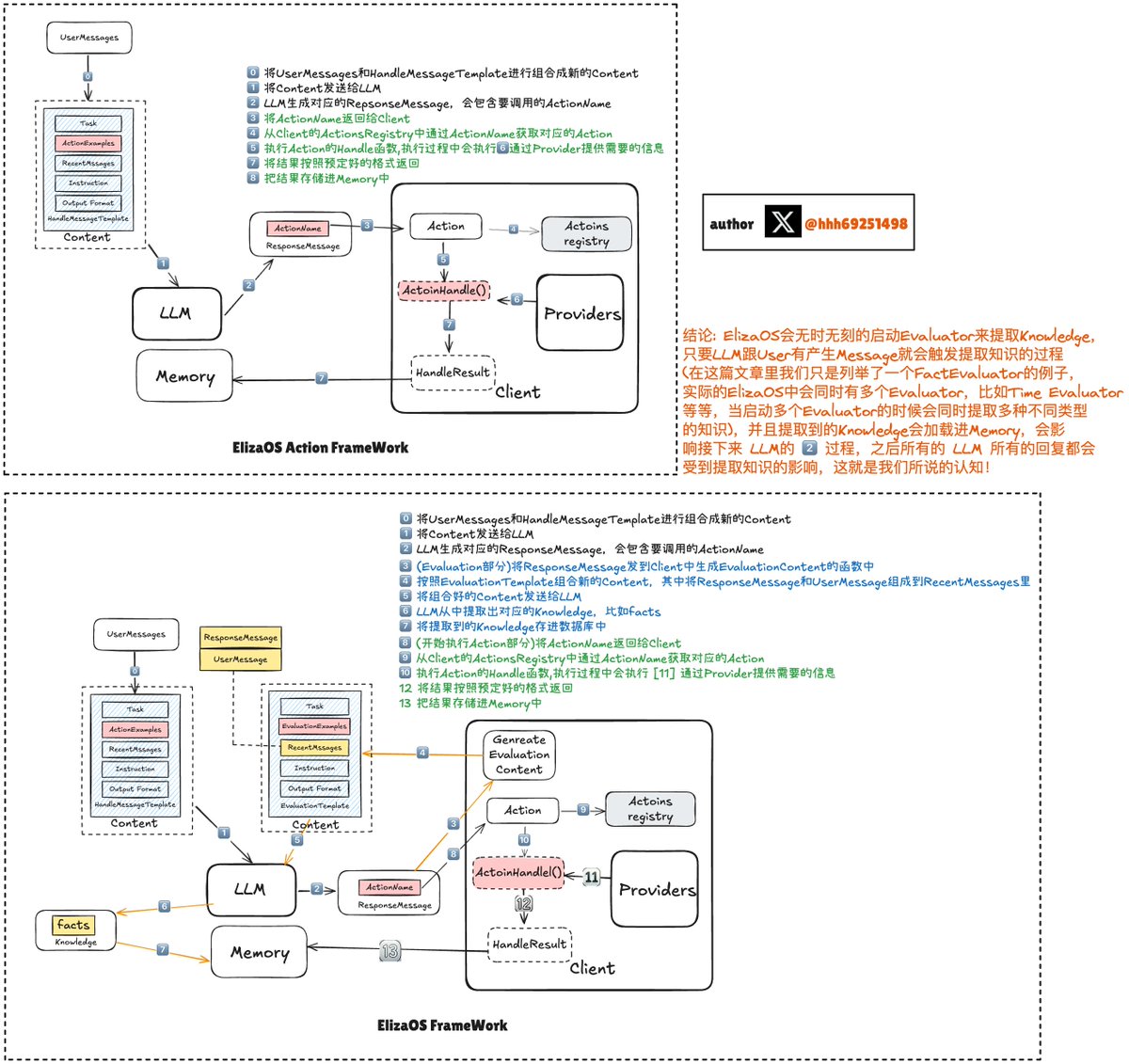 2/3
2/3


 2/5
2/5





