
15 Years building AI and Cloud @microsoft @google @intel | #1 Visual Storyteller in Tech | TED Speaker | DM for Collabs | Opinions = mine





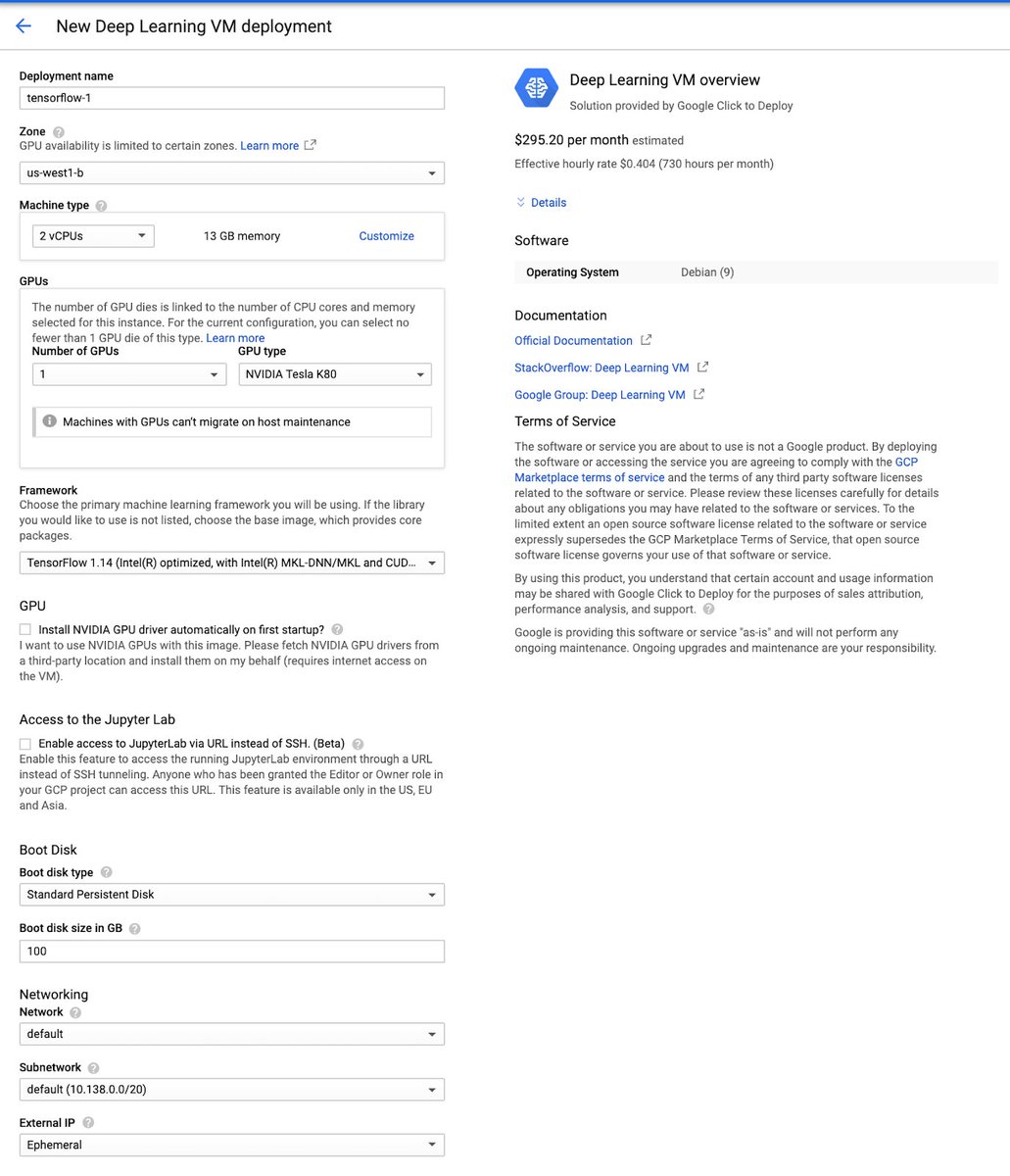
 ✅ Simple VM app
✅ Simple VM app


 @kweinmeister 1️⃣ You aren't solving the right problem
@kweinmeister 1️⃣ You aren't solving the right problem  Calculating loss for every value of W isn't efficient: most common way is called gradient descent
Calculating loss for every value of W isn't efficient: most common way is called gradient descent

