
К новым технологиям в Японии (да и не только): 1 лайк - как минимум 1 твит про такую область “искусственного интеллекта” как обработку естественных языков - пытаемся сделать из тупой железки что-то понимающую людей и их речь.
0. И получается это пока что не очень хорошо, хотя какой-то прогресс есть. Вон гуглопереводчик стал переводить сильно лучше, чем несколько лет назад. Появились всякие умные колонки, да и вообще голосовой ввод текста стал куда более вменяемым. Но ещё есть куда рости.
Ах да, наша область по английски называется NLP - Natural Language Processing. Со всякими другими нлп-товарищами попрошу не путать, так как нам с ними совсем не по пути.
00. Я уже 5 лет как живу в Японии и говорю 97% времени на японском, так что моё построение фраз и правописание на русском может страдать время от времени, так что вы сильно не обижайтесь.
1. Во-первых кто мы (NLP-шники) такие:
В основном компьютерщики и математики, а не лингвисты. Лингвистическое тут есть, но его не так много, особенно по сравнению с количеством математики и программирования для создания и использования новых методов
В основном компьютерщики и математики, а не лингвисты. Лингвистическое тут есть, но его не так много, особенно по сравнению с количеством математики и программирования для создания и использования новых методов
2. Точнее есть и лингвисты, использующие наши методы для решения своих лингвистических задач (исследование структуры языка), мы же больше занимаемся прикладными вещами, например автоматически определяем полярность текстов (хвалит ли текст кого-то или обсирает, анализ отзывов)
Если я использую непонятные термины или жаргон, спрашивайте пожалуйста, я постараюсь объяснить.
К русским нлп-шникам: я не знаю русского жаргона, так как начал заниматься этой сферой здесь, так что расскажите если что
К русским нлп-шникам: я не знаю русского жаргона, так как начал заниматься этой сферой здесь, так что расскажите если что
3. Сфера получила очень сильный толчок во времена холодной войны, когда с ростом возможностей компьютеров появились мысли что можно пытаться автоматически переводить тексты с одного языка на другой.
4. Первые подходы к машинному переводу были по сути дела лингвистическими: мы попытаемся вручную создать набор правил, по которым будем превращать текст на одном языке в текст на другом.
5. Этот подход невероятно фейлит в ситуациях когда ничто не ограничивает возможное использования языка (по сути в обычном использовании). Это потому что одно и то же можно сказать по сути бесконечным количеством способов и нельзя нафигачить правил, которые бы это всё покрыли
6. Однако он может неплохо работать для перевода однотипных вещей, например инструкций.
7. Люди из корпорации IBM в 90-х придумали использовать статистические методы для машинного перевода. То есть берёшь набор одинаковых предложений на двух языках и компьютер сам вычисляет эти правила (ну в теории), лингвисты больше не нужны!11один
8. Это первый пример борьбы сторонников линвистически-обоснованных подходов и людей, которым лишь бы что бы всё работало (и без разницы как). Сейчас с этим стало ещё веселее, но об этом потом.
9. Есть одна байка про IBM в то время: “Каждый раз когда я увольняю лингвиста из нашей команды, точность перевода растёт на 3 процента” (приписывается лидеру проекта машинного перевода)
10. В 2014 году предложили первую нейросетевую модель машинного перевода: она использует нейросети и глубинное обучение вместо кучи сложных и хитрых алгоритмов, используемых в статичтическом машинном переводе…
11. …и нейросети просто порвали предыдущие подходы как тузик грелку. Большинство современных систем машинного перевода используют хоть какие-то нейросетевые компоненты (хотя и имеют и “обычные” части тоже)
12. То есть в машинном переводе “работники на результат” по сути практически не оставили места для жизни лингвистам.
13. Что бы понять почему это страшно: вы кормите компьютеру набор предложений на двух языках (и всё!) и на выходе получаете модель, которая производит перевод не понимая структуры этих двух языков в принципе (!), причём перевод вполне вменяемы.
14. Статистические модели хотя бы использовали алгоритмы, придуманные людьми, понимающими что такое язык и использующие этот факт. Нейросетевые модели вообще не имеют никаких начальных знаний о структуре языка.
15. Проблема у нейросетевого перевода - это стабильность. Заметьте разницу первого варианта и второго, хотя я всего лишь удалил один знак вопроса! Разговорных вариантов похоже у в гугло-корпусе (данных для обучения модели) тоже похоже очень мало.
Линк: translate.google.com/#ru/en/%D0%9D%…
Линк: translate.google.com/#ru/en/%D0%9D%…
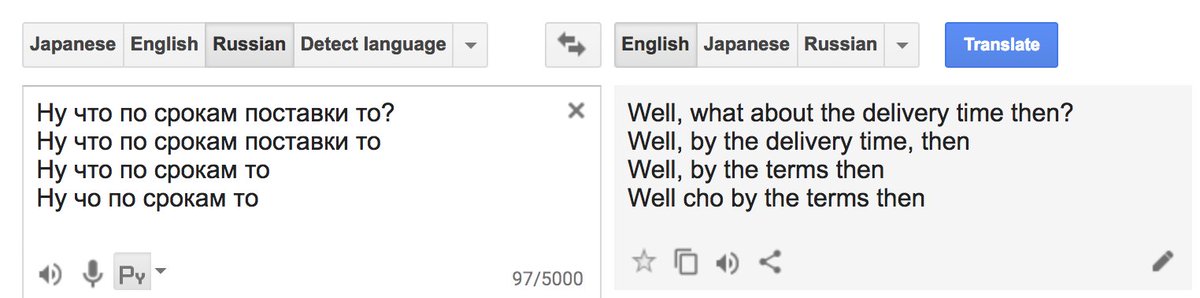
16. Хотя первый вариант тут просто идеален имхо. Но стабильность, ака робастность, ака устойчивость - это общая проблема нейросетевых моделей и особенно с ней работают сейчас в обработке изображений, привет им.
17. Из баек, мне тут @__sattva напомнил: Я лично репортил баг (знакомому в гугл-транслейт) когда инструкции команд из руководства установки генту (типа mkfs.ext4 /dev/sda1) переводились как “скачать порно бесплатно без регистрации и смс"
18. Ах да, нейросети. Мне этот термин не нравится. По сути это просто умножение матриц и градиентный спуск с некоторыми (впрочем весьма важными) добавками. Метод хорошо работает потому что мы накопили большое количество данных и компьютеры стали быстрыми.
19. Точнее потому что игровая индустрия профинансировала производителей видеокарт чтобы они сделали (сравнительно) дешёвый процессор который умеет быстро умножать матрицы и работать с более-менее произвольными данными, а не только с графикой. 100% сеток используют видяхи NVidia.
20. Почему NVidia? Потому что они тупо начали предоставлять библиотеки для машинного обучения на их видяхах раньше всех. Всё, привет монополии. Ну ладно, хватит про видяхи.
21. Вернёмся к основам. Мы обычно работаем с текстом. В смысле на вход получаем текст в “натуральном компьютерном” виде, где каждый символ (обычно буква, но не факт: 日本 вот не буквы, а идеограммы) представляется в виде числа.
22. То есть эти символы ещё как-то надо ввести. Для большинства языков в мире это легко - 1 (или чуть больше для символов с диакритиками) нажатие клавиши на клавиатуре превращается в 1 символ внутри компьютере, это не интересно.
23. Есть три более интересных направления: распознавание речи (по звуковому сигналу выдать эти символы), оптическое распознавание символов (с картинки) и хитрые системы ввода для языков, которым не повезло с системами письменности (привет, Японский)
24. На самом деле первые два направления хоть и близки к нам, но мы ими не занимаемся. Оптическое распознавание гораздо ближе к обработке изображений, а распознавание речи и генерация речи выделена в отдельную под-область со своими порядками (обработка сигналов не к нам)
25. А вот всякие альтернативные системы ввода штука очень хитрая и по ней информации на японском в разы большем, чем на английском. Например основная задача японского IME это по вводу watashihabakagaijinn выдать именно последовательность 私はバカ外人, а не 和足し幅課外維持ん
26. Input Method Editor (IME) - говорит что мы не просто вводим, а производим какие-то хитрые преобразования над этим вводом. Оба японских “варианта” могут быть прочитаны одинаково.
Японский я оставлю без перевода, пользуйтесь гугл-транслейтом в лучших традициях этого треда.
Японский я оставлю без перевода, пользуйтесь гугл-транслейтом в лучших традициях этого треда.
27. То есть ввод по сути дела полу-фонетический: по произношению (в какой-то транскрипции) мы пытаемся правильно угадать нормальную запись этого дела. Распознавание речи на самом деле просто работает с другим входом, но там свои особые фонетические тараканы.
28. Частью решения обычно служить нечто под названием “языковая модель”, очень часто используемый инструмент вычислительной лингвистики. Основная идея: пусть мы можем определить вероятность каждого предложения языка. Дак сделаем чтобы вменяемые предложения были вероятнее плохих.
29. Тогда для ввода мы можем, например, посмотреть все предложения, которые могут породить данную транскрипцию и выбрать самое вероятное. Оно обычно не будет плохим вариантом.
30. Однако вероятных предложений очень (экспоненциально) много, да и языковую модель надо как-то хранить в компьютере.
31. Простым вариантом языковой модели является н-грамная модель. Слово - это 1(уни)-грам, два соседних слова - 2(би)-грам, итд
Тогда бы можем посчитать нграмы (до определённого порядка) на большом объеме текстов и использовать полученные величины для вычисления вероятностей
Тогда бы можем посчитать нграмы (до определённого порядка) на большом объеме текстов и использовать полученные величины для вычисления вероятностей
32. Так вот даже биграмная языковая модель даёт вменяемую точность для японского ввода.
33. Современные модные языковые модели правда нейросетевые. Даже нейросетевой машинный перевод на самом деле это такая языковая модель, только специфическая.
34. Языковая модель - понятие важное. Каждый из нас её имеет для всех языков которые мы знаем. Мы можем легко определить какие предложения “правильные”, а какие нет, хотя вроде бы грамматически всё вроде ок. Вот эта штука как раз про языковую модель. pikabu.ru/story/yetot_sl…
35. Да и в изучении иностранных языков самое важное и сложное это на моей взгляд не лексика, грамматика и прочее, а как раз выработка этой самой языковой модели.
36. Ну хорошо, я вот тут говорю “слово”, “слово”, а что такое слово? В большинстве языков есть пробелы и они спасают, но не всегда. Бывают ситуации что хочется считать “Нижний Новгород” самостоятельной и целой единицей, чтобы например не оказаться в Великом.
37. Ну или как разбить текст на предложения? Точки, запятые и восклицательные знаки, ага! Ну и чтобы следующее слово начиналось с большой буквы.
Хорошо ув. г-н. Иванов, мы вас запомним.
Хорошо ув. г-н. Иванов, мы вас запомним.
38. Поэтому даже для таких казалось бы простых задач требуется использовать что-то более хитрое. Разбиение текста на предложения вообще штука сложная, если хочется чтобы было вообще всё правильно.
особенно в веб-речи где нет пунктуации и больших букв всё очень сложно такие дела
особенно в веб-речи где нет пунктуации и больших букв всё очень сложно такие дела
39. В языках без пробелов всё ещё веселее, потому что... нет пробелов! И начинаются ОЧЕНЬ БОЛЬШИЕ проблемы с определением что же такое слово в принципе.
40. Японскому ещё относительно повезло в этом плане так как плавают по большей части сложные глаголы и составные существительные, остальное более-менее понятно из-за сложной системы письменности. В китайском всё гораздо хуже, ад и погибель.
41. Возьмём к примеру фразу 焼肉定食を食べ始めたくなかった (якинику-тёйсёку о табэ-хадзимэ-та-ку-на-катта, не хотел начинать есть обед с жареным мясом). Считать ли 焼肉定食 - обед с жареным мясом одним словом? А остальную глагольную конструкцию?
42. Собственно поэтому японская практика игнорирует понятие “слово” целиком и работает исключительно с морфемами. Это тоже самое, если бы мы слово “не до пере дела нн ый” писали именно с таким разбиением. (Я могу ошибаться, лингвисты, простите)
43. Это потому что другая единица разбиения - бунсэцу (пример в 41 состоит из целых двух их) будет слишком крупной. Правда в некоторых случаях (например при автоматической расстановке произношения) лучше работать с большими единицами.
44. Ах да, стандартов разбиения на морфемы сейчас я знаю как минимум 3.5 штуки и три из них несовместимые (остальные полтора идут парой). Самое что смешное что тяжело сказать какой из них правильный, а какой нет. У всех есть свои плюсы и минусы.
45. Одной из базовых утилит в японском NLP является морфологический анализатор, разбивающий предложения на морфемы, проставляющий части речи и прочие ништяки. Я тут написал один в прошлом году, он должен быть всё ещё самым точным в нашем стандарте github.com/ku-nlp/jumanpp
46. Морфологический анализ - это один из примеров промежуточных задач, где мы решаем задачу чтобы использовать её результат для вычисления чего-то последующего. Машинный перевод к примеру конечная задача, где вывод будет показан пользователю.
47. Научный прогресс в нашей области обычно движется как улучшение метрик задачи на каком-то стандартизированном наборе данных. Для морфологического анализа к примеру у нас есть корпус (набор текста), где все морфемы размечены вручную специальными людьми.
48. Метрикой в морфологическом анализе обычно является точность (для педантов F1-measure) разбиения и угадывания частей речи. Для японского эти цифры составляют 99.5/99% для газет и 98.6/98% для веба. У китайского для газет эти цифры 97.7 и 93.4. В 4 раза больше ошибок!
Вам может показаться что это очень высокие цифры, но это не так. Даже 99.5% это по сути 80% на предложение из 40 “слов”. Те ошибка в каждом пятом предложении в среднем. 98% это ошибка в каждом втором таком предложении.
49. Это всё к теме что китайский гораздо сложнее автоматически обрабатывать автоматически чем японский. После разбивки на слова уже проще потому что одни и те же методы более-менее работают на всех языках.
50. Ах да, стандартными наборами данных очень часто выступают газеты так как это обычно самый простой способ набрать “нормального” и не супер формального текста. Правда есть всякие приколы с авторскими правами.
51. Например наш корпус построен на Asahi Shinbun 1995 года и в нём встречаются слова типа “Чечня”, “Дудаев” и прочее такого плана. Но бесплатно распространяется только аннотации (разметка в виде частей речи и сегментации). Тексты надо купить (у газеты), что может быть не просто.
52. Немного о других внутренних задачах: из лингвистически мотивированных можно выделить синтаксический анализ или парсинг. Это поиск структуры в тексте.
52. В школе нас всех должны были заставлять чертить стрелочки зависимостей в предложениях. Такая структура называется деревом зависимостей и удобна для анализа.
53. Другой вид парсинга строит деревья из constituent-ов (я не знаю как они будут в русской традиции). Эти штуки удобнее для генерации текста.

54. Общая проблема всех этих структур — они всё таки не более чем лингвистические формализмы и некоторые явления языка они описывают убого. Хотя и упрощают (или делают возможным) анализ в других ситуациях
55. Вторая проблема это неоднозначность. Некоторые предложения можно трактовать не только одним способом. Например тут вот либо телескоп будет инструментом, либо же он просто будет у девочки. Структура же будет разная.

56. Ещё одна известная внутренняя задача (особенно характерная для английского) это снятие полисемии (или word sense disambigutation). В общем слова могут иметь больше одного смысла и мы хотим определить в каком именно смысле они были употреблены.

57. Что это всё вместе даёт? Например мы можем пытаться искать события в тексте (кто, что, где и когда сделал) и связывать их в цепочки. По сути, это первый шаг к пониманию текста.
58. Такие события иногда называются предикатно-аргументной структурой. В смысле мы хотим сначала определить действия (предикаты), а потом связать их с аргументами. Этот формализм уже начинает игнорировать информацию из текста, но удобен для конструирования языковых интерфейсов.
59. Например: Сири, включи будильник в 8 утра. Включи тут будет предикатом, будильник будет аргументом-объектом, Сири-аргументом-субъектом, 8 утра тоже аргументом, тип уже будет плавать в зависимости от конкретной типизации, но это не суть важно.
60. Правда для такой команды не обязательно проводить всю цепочку анализа, хватит чего-то более костыльного (то есть простого). Но иногда нужна и вся цепочка. Или нейросети.
61. Доброе утро. Вот вам xkcd про нашу область. Это даже правда.

62. На самом деле тут проблема в том что вообще непонятно что такое язык и как оно работает. Традиционные лингвисты придумывают теории, которые работают большее количество времени, но те теории бывают бесполезны для практики. Поэтому и выкручиваемся как можем.
63. Вернёмся к нашим структурам. Разбор предложения на дерево зависимостей на самом деле бывает ещё и типизированный: на каждую “стрелочку” мы подписываем тип зависимости.

64. Такое дерево будет содержать почти предикатно-аргументные структуры (есть и действия и их аргументы и даже их типы!), но есть одно важное отличие: ПАС всегда будет с разрешёнными ссылками.
65. “Петя купил пирожок и съел его идя домой”. Тут например нужно разрулить, что “его” это на самом деле пирожок, а действие “идя" будет относиться к Пете, а не пирожку. Первая подзадача называется coreference resolution, вторая anaphora resolution.
66. В японском есть ещё более противная вещь в этом плане: подлежащее в предложении очень часто опускается. Просто “Съел завтрак”. А кто съел - я, ты, Петя или неопределённая личность опускается. То есть нужно ещё разрулить и эту ситуацию.
67. Я вот так в красках расписываю про эти подзадачи, но проблема в том, что современные методы нифига не могут их решить нормально (точность около 80% в лучшем случае, а для японских анафор в районе 60%!). То есть вообще всё тухло.
68. Так что (какой-то) машинный перевод на самом деле ПРОЩЕ понимания языка. С пониманием вообще угар и содомия.
69. С другой стороны если начинать вводить предложения с такими вот проблематичными штуками, то можно ломать и системы машинного перевода. Они же не делают глубокого анализа (потому что если бы делали то ошибались бы ещё больше).
70. Давайте поговорим про алгоритмы, которые мы тут используем.
71. Для программистов алгоритм будет чем-то написанным людьми выдающим всегда правильный ответ. Ближайшим тут будет система основаная на правилах: обычно толпа лингвистов пишет правила как обрабатывать те или иные ситуации и такие системы всё ещё есть.
72. Одна из таких штук насколько я знаю - wolfram alpha. По слухам это гигантское месиво из регулярных выражений, но как-то работает (хотя померять высоту Фудзи в попугаях у меня не получилось)
wolframalpha.com/input/?i=heigh…
wolframalpha.com/input/?i=heigh…
73. Для языкового анализа основная проблема это то, что одно и то же можно сказать безумным количеством способов. Например “хочу проснуться в 8”, “разбуди меня в 8”, “поставь будильник на 8”, “хочу встать в 8” - по сути одно и то же, но слова разные.
74. (Это к примеру если мы делаем языковой интерфейс будильника) Кстати, попробуйте поставить будильник на своём телефоне через сири/гугл помошник наибольшим количеством способов. Ребята реально решают вот эту проблему.
75. Ну ладно, если не писать правила руками, то как ещё быть? Попытаться заставить тупую железку выучить их из каких-то размеченных данных, конечно! Машинное обучение форева!
76. Что такое машинное обучение? По сути дела особый сорт чёрной (или белой) математической магии. Компьютеры тут выступают исключительно в роли тупой железки, которая умеет дробить числа.
77. Если сильно упрощать, то мы строим математическую модель, которая может предсказывать какие-то данные на основе исходного текста. Затем считаем разницу между предсказанными данными и правильным ответом, подготовленным специально обученными людьми (аннотаторы - лучшие друзья)
78. Обычно модель подбирается такого вида, чтобы можно было посчитать производную от этой разницы по отношению к параметрам. Тогда мы можем минимизировать эту функцию потерь. (← математическая белиберда)
79. Собственно, наша работа это придумывать такие модели и реализовывать их в виде компьютерных программ.
80. Я не буду особо углубляться в дебри этого всего, интересующиеся могут попытаться почитать (ну или второе издание в бумажном или электронном виде) web.stanford.edu/~jurafsky/slp3/
81. Нейросети по сути дела одно из семейств таких вот моделей, правда при их использовании слова представляются интересным и весьма специфичным образом. Давайте поговорим про представлении слов в компьютере.
82. Почему нам надо как-то представлять слова? Компьютер же не понимает что такое слово! Он понимает только циферки. Тупая железка же, не забывайте. Обычно программисты представляют текст как последовательность цифр, которые соответствуют символам.
83. Но символы это слишком низкий уровень и неудобно. Оговорюсь, правда, что иногда используется именно такое представление. Но обычно хочется работать по крайней мере со словами (в широком определении слова).
84. Так что допустим мы разбили наш текст на слова (последовательность символов) (пробелами, токенизацией или морфологическим анализом). Теперь мы можем назначить каждому слову номер и использовать это представление.
85. Ну и какой максимальный номер будет у такого представления? Правильный ответ - а чёрт его знает. Если вы думаете, что можно это количество ограничить сверху, то это в общем случае неправда.
86. В основном проблема это всякие очепятки (привет новое слово) и бредовые названия. Разработчики поисковых систем обычно должны поддерживать ВСЕ такие слова что есть в интернете, давайте будем их уважать в том числе и за это.
87. Мы же не такие крутые и нам хватает ограничиваться некоторым количеством самых часто употребимых (высоко-частотных на нашем жаргоне) слов.
88. Либо можно просто не париться и считать хэш-функцию от каждого слова, используя полученное значение в качестве числового значения слова (← программистская белиберда)
89. Хорошо, мы представили слова числами и что? Ну по крайней мере это уже неплохое представление само по себе. Можно сделать самый простой NLP: посчитать частоты слов в тексте.
90. Допустим у нас есть какой-то набор документов, мы считаем частоты для каждого документа отдельно. Затем мы считаем количество документов в которых это слово встречалось. Ура, мы почти получили удачную и простую метрику важности слова в документе.
91. Пусть частота слова в документе будет tf (term frequency), n - общее количество документов, df (document frequency) - количество документов, в которых встречается слово.
Наша метрика будет tf.idf = log(tf + 1) * log(n / df), она используется в том числе и для поиска
Наша метрика будет tf.idf = log(tf + 1) * log(n / df), она используется в том числе и для поиска
92. Ещё представление документа в виде значений этой метрики даёт неплохую точность для автоматического определения жанра документа и построения всяких визуализаций типа облаков слов. Вот эта штука например использует только частоты, вот и результат так себе.

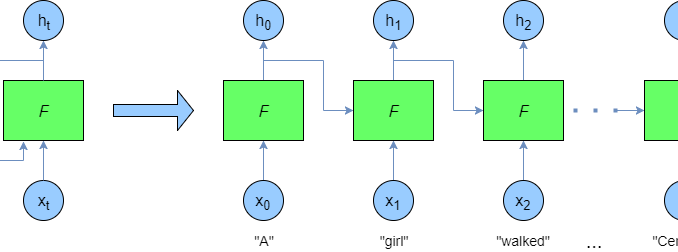
Если что, это неправильная подветка. Нажимайте туда, где начинается с 0.
93. А вообще мы можем рассмотреть это всё как таблицу, где строчки это слова в документах. Но можно на это посмотреть и наоборот - что столбцы это документы в которых используется слово.

94. И разные слова можно ВНЕЗАПНО сравнивать, получая степень их схожести (если значения метрики для одинаковых документов схожи). Можно использовать например стандартную формулу для расстояния на (гипер-)плоскости: квадратный корень из суммы квадратов разницы.
95. То есть мы получили метрику похожести слов, просто посчитав их частоты в документах! Эта штука называется vector space model, если будете гуглить.
96. На самом деле лучше использовать вместо расстояния на плоскости формулу угла между векторами: нормализуем векторы до единичной длины и считаем скалярное произведение между ними (← математическая блаблабла)
97. Вообще достаточно давно лингвисты говорили: “можно узнать слово по его компании”, то есть в принципе можно более-менее угадать смысл слова по его контексту.
98. Вычисление всяких таких представлений для слов, чтобы можно было искать семантические отношения между ними называется distributional semantics: мы считаем семантику по (вероятностному) распределению вокруг слова.
99. На самом деле что-то на подобии этой векторной модели, только используя сумму всех контекстов (например 10 слов влево + 10 слов вправо) как документ и функцию PMI en.wikipedia.org/wiki/Pointwise… можно (было до 2013 года) считать вполне неплохие векторные представления слов
В 2013 году парень с фамилией Миколов выпустил работу, которая очень сильно поменяла всё это направление. Нейросетки могут вычислять гораздо лучшие векторные представления слов и не просто представления! Над векторами можно делать семантические операции!

101. Да, мы берём вектор для слова “король”, вычитаем из него “мужчина”, прибавляем “женщина” и самый близкий вектор к получившемуся будет “королева”. Эта работа очень сильно повлияла на всё поле NLP и общий переход к нейросетям.
102. Ну я немного приукрасил, что PMI работало только до 2013 года, работу Миколова естественно разобрали по косточкам, и даже показали связь его функций с PMI и предложили некоторые улучшения, но все равно можно делить историю NLP до word2vec и после, я считаю.
103. Как word2vec работает? Каждому слову в нашем словаре ставим в соответствие два вектора.
Обходим весь корпус.
Для каждого слова из корпуса рассматриваем контекст (например 5 слов влево и вправо)
Берём слово, контекстное слово и штук 10 случайных “мусорных” слов
Обходим весь корпус.
Для каждого слова из корпуса рассматриваем контекст (например 5 слов влево и вправо)
Берём слово, контекстное слово и штук 10 случайных “мусорных” слов
104. Пытаемся модифицировать векторы таким образом, чтобы контекст был похож на слово, а “мусорные” слова не похожи. Повторяем долго и упорно.
105. Это всё. Честно. github.com/tmikolov/word2… (код правда не супер) И векторные представления после выполнения этих операций можно действительно вычитать образом как я чуть выше писал.
106. Ну хорошо, у нас есть два типа представлений слов: символьные (когда 1 слово - 1 номер) и векторные (1 слово - 1 точка в общем многомерном пространстве). Чем они отличаются?
107. По сути символьное представление мы не можем сравнивать более чем одинаковое ли это слово или нет. Ну плюс-минус всякие штуки на общность символов, но никто же не скажет, что стол и стал - похожие по смыслу слова.
108. Векторное представление же по умолчанию можно сравнивать. Это даёт нам гибкость мы можем сказать что “собака” и “кошка” должны быть более похожи друг на друга, чем “собака” и “падать”.
109. Это даёт возможность алгоритмам начинать абстрагироваться от конкретных слов и начинать оперировать… векторным представлением. Проблема в том, что это векторное представление не похоже на человеческие абстракции, которыми мы мыслим.
110. Такие алгоритмы начинает быть очень тяжело трактовать (в смысле понять почему именно они сделали именно это решение, а не какое-то другое) и это их минус. Дебаг очень фиговый. Не понятно либо у тебя баг в программе (реализации), либо сам алгоритм глючит.
111. В этом плане алгоритмы, работающие с символьным представлением проще трактовать (или использовать для лингвистических целей).
112. Ведро дёгтя в сторону word2vec и distributional similarity вообще: да, оно хорошо находит синонимы только по неразмеченному корпусу. Но оно ещё и путает антонимы с синонимами. (Антонимы очень часто используются в тех же контекстах, что и синонимы)
113. Для некоторых задач это норм, что холодно и жарко для твоего алгоритма примерно одно и то же (температура ведь). Для некоторых это смертельно плохо.
114. Вернёмся к языковым моделям. Хотя базовое определение состоит в том, что они задают вероятность каждого предложения в языке, с некоторыми оговорками можно это число разбить на кусочки
115. Мы попытаемся заставить модель угадывать слова, одно за другим, или по сути дела просто продолжать предложение.
116. н-грамные модели умеют делать такие вещи, но мы же знаем что для таких вещей символьное представление слов не кошерно и хотим использовать векторное!
117. Поэтому мы сделаем так: мы будем иметь какое-то начальное векторное состояние, будем его как-то преобразовывать и пытаться с помощью преобразованного состояния угадывать следующее слово. Повторять пока есть вход.
118. Поздравляю, мы получили рекуррентную нейросетевую языковую модель. Рекуррентная она потому что преобразование каждый раз одно и то же, только входы разные. Это уже вполне себе современный инструмент.
119. Если преобразование будет специфического вида (LSTM: colah.github.io/posts/2015-08-…), то мы получаем одну из самых часто-используемых нейросетевых архитектур для работы с языком. Есть и другие преобразования, но суть не в этом.
120. Чем такая архитектура ещё примечательна? Мы можем её кормить вот таким вот макаром: то есть сначала кормим вход, затем специальный символ что вход закончился и после этого зацикливаем варианты, предложенные моделью, на её же вход.

121. Это, господа, базовая модель нейросетевого машинного перевода, предложенная в 2014. Больше в ней нет движущихся частей. Совсем.
122. То есть мы просто тупо кормим вход, затем ждём пока нейросетка что-то нам выдаст и считаем это переводом. И это работало СРАВНИМО ПО КАЧЕСТВУ с суперсложными методами, которые я ни за что не объясню даже в общих деталях за 30 твитов.
123. Маленькими буквами: вам только нужен параллельный корпус на 200-300 тысяч пар предложений, а так всё хорошо.
Эта штука вызвала большое волнение в под-сообществе, занимающимся машинным переводом.
Эта штука вызвала большое волнение в под-сообществе, занимающимся машинным переводом.
124. После того как эту модель вылечили от детских болячек (например чтобы использовала информацию со всего входа, а не только последнее состояние), эпоха предыдущих моделей (в случае если у вас много данных) можно сказать что кончилась.
125. Какие же болячки всё же у нейросетевого перевода остались? Во-первых, это цифры. Для нейросети все цифры одинаковы (ну почти). Так что вам могут в переводе нарисовать совсем другую сумму денег, например.
126. Имена собственные и прочее названия. Тут проблема с их большим количеством.
127. Скорость работы. Нужно быстро и упорно перемножать много-много матриц. Гугл даже сделал специальные процессоры для нейросетей (ну не только для рекуррентных правда).
128. Вылазит всякая фигня, если входных данных не было в корпусе в момент тренировки нейросети (привет скачать порно бесплатно).
129. На самом деле такие модели плохо работают с большим количеством слов. И исследователи машинного перевода положили огурец на все эти слова! И стали разбивать текст на БЕССМЫСЛЕННЫЕ часто встречающиеся единицы (обычно это части слов).
130. Гугл-транслейт на этот феномен: translate.google.com/#ru/en/%D0%9F%….
Заметьте пробелы, которые не меняют смысл. Можно даже поиграться с порядком букв в слове, результат тот же.
Заметьте пробелы, которые не меняют смысл. Можно даже поиграться с порядком букв в слове, результат тот же.
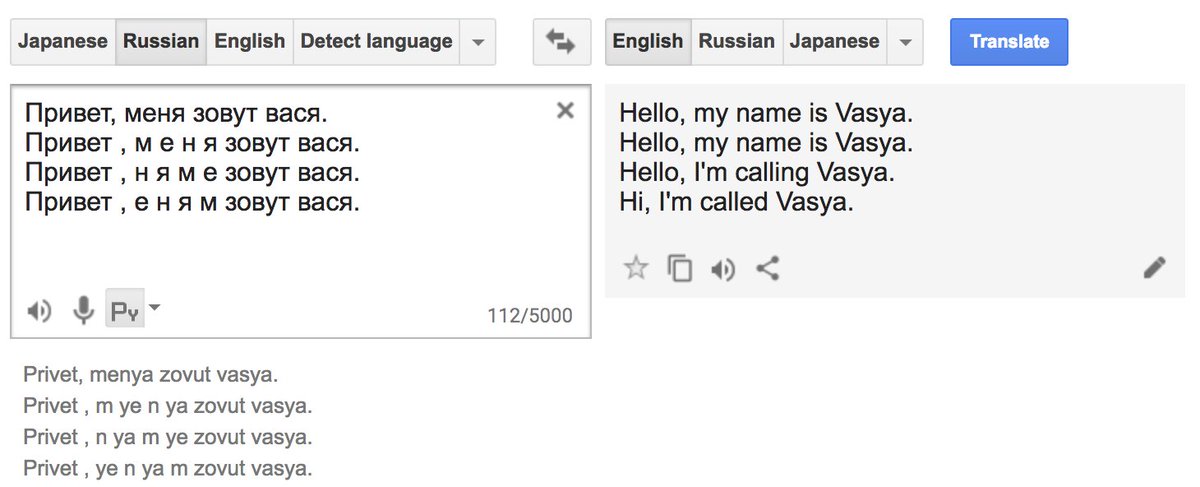
131. На самом деле сейчас гугл-тренслейт использует немного другую нейросетевую модель с более явным указанием порядка недо-слов внутри предложения. Раньше (когда была рекуррентная модель) можно было полностью переставлять слоги внутри предложения и получать тот же вывод
Я сломал тред, хахаха







