
132. Так что вот такие пироги. Современный машинный перевод полностью положил огурец на лингвистику, человеческое представление языка (нафиг слова) во имя того, чтобы был нормальный результат. И им это ок.
133. Я ещё раз повторюсь, по сути прогресс за три года (2014-2017) похоронил результаты тридцатилетней работы кучи учёных, с 80-х работающих над статистическим машинным переводом.
134. Но нельзя сказать, что машинный перевод решили как задачу. До этого ещё очень далеко. А вот задачу “перевести одно предложение автоматически” можно сказать, что решили где-то на 85% как минимум.
135. С точки зрения методов по крайней мере. Были бы данные для обучения...
136. А вот чтобы связно перевести текст - с этим очень большие проблемы (вспомним что я писал хотя бы про анафоры и разрешение ссылок). А машинный перевод должен ещё решать как минимум и это в том числе, чтобы корректно переводить.
137. Так что переводчики могут пока что вздохнуть спокойно, я считаю. Но лучше как-то пробовать использовать машинный перевод для перевода “неинтересных” предложений, особенно если это не худлит.
138. Ах да, почему я использую гугл-транслейт для примеров машинного перевода? Почти все видные японские исследователи перевода сейчас там работают просто.
139. Поэтому направление JP-EN у гугла весьма крутое на самом деле, может одно из самых крутых. Про русский вот ничего не скажу.
140. А сам я машинным переводом, кстати, вообще не занимаюсь и особо даже не хочу. Просто знаю по долгу службы, потому что методы оттуда бывают применимы и для других областей.
141. Использование непонятных недослов в машинном переводе, кстати тоже породило некоторое количество дискуссий в NLP-сообществе, особенно в японском. У нас же проблема тут как разбивать текст на “слова”. Иначе ничего не сделать, пробелов то нет же.
142. А тут приходят МТ-шники и говорят, что а нам не надо ваше разбиение, мы порежем как-нибудь (главное чтобы одинаковые места резались одинаково), а дальше хоть трава не расти.
143. Но тут вот возникает некоторая незадачка: выходом машинного перевода является по сути текст, готовый к употреблению на конечном языке. А как быть в случае если это не так? Например если это у нас поиск и нам нужно бить на “слова”, соответствующие людскому представлению о них
144. Но это наши местные разборки по-сути. Где у людей есть пробелы, там таких проблем особо нет.
145. С другой точки зрения правда похожая проблема висит сейчас надо всеми НЛП-шными задачками. А зачем нам вообще решать промежуточные задачи, если можно всё запихать в нейросеть, и ждать что она выдаст хороший выход сразу, безо всякой токенизации, расстановки частей речи.
146. Однако данный подход сейчас более-менее успешен только в машинном переводе и распознавании и синтезе речи. Основная проблема тут в количестве данных для обучения. Они не бесконечные, а даже весьма ограниченные.
147. Ещё нейросети плохо кодируют структуры (там графы и прочие деревья). Правда тут же возникает вопрос: а нужны ли они для решения прикладных задач вообще? Или таки лингвисты правы и структуры помогают.
148. У меня кончаются идеи. Ну ладно, попробуем подумать про чатботы, хоть я их не люблю, представление знаний и commonsense knowledge, а так же про ИИ вообще и как это всё соотносится с обработкой языка, другими сферами ИИ и нейросеточками. Или задавайте вопросы.
149. Зависит от определения “обычного компа” и задач. Если надо именно разрабатывать новые нейросетевые модели таки нужно некоторое количество вычислительных ресурсов. Но куда больше проблемы будут с данными. Открытых ресурсов мало и они мелкие.
150. Продолжим! Я писал в первом посте что-то про “железки понимать людей”, но почти не развивал эту тему.
151. Что такое понимать вообще? Уметь структурировать текстовый ввод? Уметь дать какой-то ответ на вопрос? Помигать зелёной лампочкой в ответ на ввод? Переспросить “А почему вы спрашиваете?”?
152. В общем это понятие растяжимое. Можно конечно начинать думать про обобщённый искусственный интеллект (ОИИ-GAI), по сути то, что фантасты называют искусственным интеллектом, там возникают понятия осознания и создание новых знаний самим ОИИ.
153. Для “понимания” в более узком плане это всё не требуется - чтобы помигать лампочкой достаточно научиться распознавать факт, что вам кто-то что-то говорит, а содержимое можно проигнорировать. Но это не интересно.
154. Как нечто среднее можно рассмотреть такую сферу NLP как ответы на вопросы (гугл какая высота эвереста в слонах). Со слонами увы не работает. 

155. С более хитрыми запросами тоже работает плохо :(

156. А вот wolfram alpha тут справился.

157. По сути что надо уметь сделать чтобы отвечать на такие вопросы
1) Как-то структурировать информацию, доступную в текстовом виде
2) Понять запрос -> представить его в виде, чтобы он совпадал с информацией
3) Каким-то образом исполнить этот запрос
1) Как-то структурировать информацию, доступную в текстовом виде
2) Понять запрос -> представить его в виде, чтобы он совпадал с информацией
3) Каким-то образом исполнить этот запрос
158. Часто информацию пытаются представить в виде таблиц-отношений (кто тут любит реляционные БД).
В математической записи что-то типа:
Президент(Путин, РФ)
Президент(Трамп, США)
В математической записи что-то типа:
Президент(Путин, РФ)
Президент(Трамп, США)
159. После этого мы пытаемся трансформировать запрос с человеческого языка в какой-то язык запросов для БД, выполняем его и формируем ответ. Нашей работой тут зачастую является автоматическое наполнение баз данных и преобразование человеческого языка в язык запросов.
160. Вот такое нельзя полностью зафигачить на нейросетях (так как базы данных очень плохо на них ложатся). Подзадачи, конечно, народ пытается решать в том числе и нейросетями.
161. Немного похожей задачей является попытка понять небольшие тексты и ответить на вопросы по ним. Очень простой штукой является bAbI (даже не спрашивайте почему оно так называется)
research.fb.com/downloads/babi/
research.fb.com/downloads/babi/
162. То есть у нас есть текст вроде
1 Mary moved to the bathroom.
2 John went to the hallway.
3 Where is Mary? bathroom 1
4 Daniel went back to the hallway.
5 Sandra moved to the garden.
6 Where is Daniel? hallway 4
И нам нужно отвечать на вопросы в нём
1 Mary moved to the bathroom.
2 John went to the hallway.
3 Where is Mary? bathroom 1
4 Daniel went back to the hallway.
5 Sandra moved to the garden.
6 Where is Daniel? hallway 4
И нам нужно отвечать на вопросы в нём
163. Это простой набор данных для тестирования “систем понимания текста”, хотя тут для человека и понимать то нечего по сути. Проблема в том что для компьютера это просто набор циферок.
164. Он не знает что Мэри будет человеком, скорее всего женского пола, а раз человеком то могущим передвигаться, и что для передвижения можно использовать много разных слов, но значат то они по сути дела одинаковые действия (по сути).
165. Народ использует всякие бредовые нейросетевые архитектуры чтобы решать такие задачки. И простые наборы данных как bAbI решаются почти со 100% точностью.
166. Однако тут есть подвох: компьютеры все равно не начинают “понимать” что же такое “ходить”, “сад” и прочие понятия. Они запоминают некоторые превращения (и фиг знает какие) над состояниями (которые непонятно что из себя представляют), чтобы ответ был “правильным".
167. То есть правильной последовательностью символов. Они не могут объяснить почему была выбрана именно эта последовательность символов (правда есть какие-то подвижки на этот счёт, но там тоже не всё понятно).
168. Окей, мы хотим чтобы компьютеры нас понимали, так давайте проверять такую штуку как “здравый смысл” (commonsence knowledge).
169. В повседневной жизни мы сталкиваемся с безумным количеством явлений, которые для нас естественны и не требуют объяснений. Например если нажать на кнопку выключателя в комнате, то (обычно) включится свет. Или что трава обычно зелёная. Или что арбуз сладкий.
170. Количество таких знаний просто неимоверно большое, и самое противное в том, что мы их почти не замечаем.
171. Была предложена такая штука как Winograd Schema Challenge:
[1]John took the water bottle out of the backpack so that it would be lighter.
[2]John took the water bottle out of the backpack so that it would be handy.
Надо разрешить it, то есть понять на что оно указывает
[1]John took the water bottle out of the backpack so that it would be lighter.
[2]John took the water bottle out of the backpack so that it would be handy.
Надо разрешить it, то есть понять на что оно указывает
172. Фишка в том, что предложения сделаны таким образом, что правильно можно это сделать только в случае, если есть правильный запас “повседневных знаний”.
173. Люди отвечают правильно в более чем 90% случаев (ну мало ли что случается). Лучший компьютерный результат в 2016 был 58.3%! На целых 8% лучше чем случайный выбор!
174. Почему так происходит? Дак в текстах люди почти не пишут то, что и так все знают. Но проблема в том, что компьютеры этого-то не знают! То есть такие знания почти нереально получить из текстов!
175. bAbI вот специально сконструирован так, чтобы таких знаний не было нужно. Ну как начальный шаг это нормально. Но как решать эту проблему не очень понятно вообще.
176. Автоматический машинный перевод работает с текстом, где всё должно быть написано, поэтому обходит эту проблему стороной. Но как только она появляется, всё, приехали.
177. Особенная веселуха будет в случае если этот “здравый смысл” будет отличаться от культуре к культуре (хинт: а он отличается в мелких, но иногда очень значительных деталях).
178. Так что для ОИИ нам надо решить эту вот проблему, которая просто невероятно сложная. Когда-нибудь и её решат, я думаю (в теории, например, можно заставить всех людей описывать все вот такие вещи, нам надо создать эту базу один раз по сути)
179. Хорошо, полностью собрать “повседневные знания” невозможно, как собрать из текстов хоть что-то?
180. Одна из областей тут - определение естественности некоторых действий. Например: купил обед - съел обед, но не купил обед - обед съел тебя.
181. Тут каждое такое действие можно представить как событие (в первом приближении глагол-предикат с аргументами-зависимостями) и естественность цепочки событий.
182. Мы допускаем, что если у нас есть достаточно большой корпус (например пара десятков миллиардов предложений), то мы можем посчитать зависимости из предложений типа “он купил обед, а потом съел его”.
183. То есть мы хотим чтобы в тексте явно была прописана причинно-следственная связь. Тогда можно собрать статитстику по таким вещам с гигантских корпусов, которые можно собрать... например скачав себе интернет (ну его текстовую часть).
184. У нас лаба занимается в том числе и такими вещами (таких фриков правда не так много в этом мире). Такие цепочки событий можно например потом пытаться использовать для всякой логики.
185. Ещё одно из использований - это автоматической поиск причин жалоб или отзывов.
186. Но все равно этого не хватает для получения действительно повседневных знаний, которые просто не пишут в текстах.
187. Возможно, одна из проблем в том, что мы пытаемся решать наши задачи по большей части находясь только в уютном мирке из текстов, а нужно делать что-то более совместное. Например обрабатывать текст, звук, видео, тактильность и вкус одновременно.
188. Ну вы понимаете, к чему я клоню. Кстати, при использовании нейросетей гораздо проще работать со входом, имеющим разную природу (текст и картинки одновременно), чем в традиционных подходах.
189. Вот вам японского хайтека: компания Preferred Networks занимается управлением робота по звуку.
pfnet.github.io/interactive-ro…
Смотрите ещё это видео, на японском правда. На английском меньше объектов:
pfnet.github.io/interactive-ro…
Смотрите ещё это видео, на японском правда. На английском меньше объектов:
190. Это по сути распознавание речи - обработка команд - обработка изображений - управление. Всё нейросетями. Поиск объектов в такой куче это очень очень круто.
191. Давайте сделаем небольшое отвлечение насчёт японского образования (ну по крайней мере в нашей области).
192. Я сейчас PhD студент в Kyoto University, одной из лаб тут, что занимается NLP. Мы занимаемся им “чистым”, то есть работаем почти только с текстом.
193. У лабы забавная история - по сути её основал монстр по имени Nagao Makoto, имеющий свою страницу в википедии. Он даже был одно время президентом (что-то типа ректора Киотского Университета)
en.wikipedia.org/wiki/Makoto_Na…
en.wikipedia.org/wiki/Makoto_Na…
194. Он первый предложил полностью автоматический подход к машинному переводу (правда не тот, что потом использовали в IBM). В общем это мужик, который создал по сути японское NLP.
195. Нынешнее поколение японских профессоров в нашей теме по большей части его ученики.
196. Я что-то отвлёкся. В лабах живут 4 курс бакалавров, магистры и PhD (ну и ещё исследовательский стафф по проектам). Бакалавры по сути делают небольшой ресёч и пишут диплом, магистры фигачат средне, PhD фигачат много и пытаются двигать науку в сторону и немного вперёд.
197. Из-за странной истории нашей лабы, бакалавры нам попадают со специальностью electrical engineering, а не informatics, что немного затрудняет им жизнь на первых порах. Программировать же они особо не умеют, а надо.
198. Поэтому курс “молодого бойца” они проходят в лабе: по сути дела это линукс, питон, простенькое машинное обучение, нейросетки, гит, книга по NLP (лингвистики нет, как видите).
199. Для поступления на магистратуру надо сдать экзамен (довольно сложный). У внутреннего народа приоритета нет, есть только большой набор вопросов прошлых лет (на сайте доступны только 3 года, внутри последние 15 лет есть).
200. Но несмотря на это, бывают годы когда ни один бакалавр не прошёл в нашу лабу на магистратуру - весь новый народ поступил из других универов (ну или с других факультетов). Всё честно и закон джунглей на экзаменах. Сражаться то потом придётся со всем миром по сути.
201. А, экзамен состоит из математики и computer science (8 вопросов в сумме), психологии (4) и биологии-биоинформатики (4). Надо решить 4 на выбор. Лингвистики нет. Один из людей, что сейчас в лабе решал частично биоинформатику, так как занимался этим бакалавром.
202. К вопросу почему японцы идут на такую специальность - очень много говорят про дораэмона. Это такой персонаж детского аниме, робот-в-форме-кота. Он умеет говорить и имеет кучу разных девайсов-гаджетов. Вот и воздействие медиа на массы. Больше робото-мультиков детям!

203. По сути, образование внутри лабы, кроме учебников это совместный разбор научных статей (статья в неделю, рассказывают студенты и стафф), и выступление по поводу своей работы перед всеми (каждый выступает раз в 3-4 месяца).
204. Кроме этого конечно встречи с профессором/ответственным стаффом по мере необходимости.
205. Временами это разбор материалов новых конференций. Выделяется день, 5-6 часов; все съездившие и сочувствующие разбирают по 3-5 работ с этой конференции.
206. Японские студенты обычно получают свою тему исследования следующим образом: либо придумывают сами (с одобрением профессора), либо стафф предлагает некоторое количество тем, а студенты за них голосуют (типа приоритет от 1 до 5). Стафф потом распределяет темы по приоритету.
207. Международно наша область движется вперёд почти только конференциями. Журналов по сути нет. Возможно поэтому в России она не очень и взлетает (требуют журналы всякие индексируемые же). На наших топовых конференциях правда попадание 25-35%. Те две трети работ отсеиваются.
208. Как живут русские ребята в Machine Learning / Computer Vision / NLP в академических структурах интересно. Если кто знает скиньте ссылку, напишите. Эти все области в основном движутся вперёд на конференциях. Журнальных статей почти нет, насколько я знаю.
209. Если бы мне, поступающему в УГТУ-УПИ (ныне УрФУ) в 2005 году кто-то сказал, что ты парень будешь заниматься вычислительной лингвистикой в Японии, ещё и в основном японским языком к тому же, я бы ни за что ему не поверил.
210. Потому что к выпуску у меня уже был N1 Nihongo Noryoku Shiken (самый высокий уровень) и желание заниматься вычислительной лингвистикой (хотя я занимался решением линейных уравнений на кластерах в то время).
211. Но непосредственно самой темой я начал заниматься здесь, в 2013. Так что удачно (наверное) попал на нейросетевую революцию в нашей области и общий хайп.
212. Правительство Японии имеет очень хорошую программу для обучения тут, если кто-то заинтересуется. Правда нужно быть весьма упорным в обучении: топ (если у вас не супер крутой универ) или очень хорошего левела, если топовый универ типа МГУ.
213. Ну и без японского жизни нет. В смысле можно выживать, но вы не получите такого фана от Японии как страны, если бы могли в японский. Я не буду зацикливаться на этой теме, задавайте вопросы если будут.
214. Доброе утро. Раз вчера закончили про образование, давайте сегодня пройдёмся по тому как NLP к этому образованию применимо.
215. Основные направления, которыми занимается относительно много народа тут это автоматическая проверка эссе (мини-сочинений), упрощение текста и починка неправильного использования языка (дайте последнее мне и побольше, я аж во втором твите этого треда сильно налажал).
216. Автоматическая проверка эссе. Вы сдавали TOEFL iBT? А его пробник? Пробник полностью проверяется автоматически, в том числе и его эссешная часть. Более слабая версия TOEFL - TOEIC в форме сочинение/говорение проверяется в формате программа плюс человек.
217. Методы там достаточно простые: нужно проверять “вменяемость” предложений - это у нас языковая модель умеет. Содержание сравнивается по сути дела с большим количеством “хороших” сочинений, собранных во время настоящего TOEFL (с помощью машинного обучения).
218. Насколько я знаю, обычно строится одна модель на одну тему и эти модели не могут оценивать сочинения других тем. Так что это всё не очень хорошо масштабируется пока что.
219. Японцы тоже хотят ввести сочинение в своём ЕГЭ и может быть проверять его автоматически (по крайней мере частично). Подобная тема витает в воздухе. Но как всё выйдет я не знаю.
220. Упрощение текста. Это что-то типа машинного перевода, только мы пытаемся перевести на тот же язык, просто заменив “сложные” конструкции простыми.
221. Поэтому народ иногда тупо использует техники машинного перевода для решения этой задачи. Можно же попытаться искать синонимичные выражения и потом заменять сложные на более простые в тексте.
222. Упрощение из-за своей сути не применимо ко всякому тексту, где не только наполнение, но и форма тоже важна. Мне такое “отсутствие души” немного не нравится на самом деле. Но всякие там инструкции и официальные документы пусть будут понятные. Им это к лицу.
223. Проверка грамматики и прочее. Системы проверки правописания находятся в ходу уже довольно давно. Но они по сути просто проверяют, есть ли каждое слово в словаре. И если нет, то предлагают какое-нибудь близкое слово из словаря. Часто такого хватает.
224. Но можно ошибиться так, что твоя ошибка будет другим словарным словом. Например “я съел обет” вместо обеда. Такое словарным системам уже не по зубам.
225. Однако, такое по зубам языковой модели! Можно смотреть на слова, у которых больно уж низкая вероятность появления в предложении и показывать их пользователю. Некоторые системы помощи коррекции в газетах так работают кстати.
226. Если вы временами пишете что-то на английском, то я очень рекомендую попробовать сервис grammarly: grammarly.com
Исправляет много детских и не очень ошибок, которые стыдно показывать другим людям. А в своём глазу бревна не видно (кому видно тем повезло)
Исправляет много детских и не очень ошибок, которые стыдно показывать другим людям. А в своём глазу бревна не видно (кому видно тем повезло)
227. Если исправлять не только слова, а более сложные вещи, то нужно производить глубокий анализ текста и нас там ждёт очередной маленький белый зверёк: обычно такие системы делаются для анализа ПРАВИЛЬНОГО текста, а мы хотим анализировать неправильный
228. Глубокий анализ: ну хотя бы определить части речи, и разобрать предложение на структуру (какую-нибудь). Там начинается много весёлых подробностей и плясок с бубном вокруг жертвенных алтарей (с видеокартами и не только).
229. Чем исправление грамматики отличается от автоматической оценки сочинений? (За грамматические и не только ошибки нужно же тоже снижать баллы обычно)
230. При автоматической оценке обычно требуется только выдать баллы. Иногда по категориям (содержание, соответствие теме, ошибки, итд), иногда просто итоговый балл.
231. При исправлении грамматики надо выдать всё-таки что именно неправильно, а ещё лучше предложить правильный вариант. Это гораздо сложнее.
232. Я сам тоже пытаюсь заниматься применением NLP к образованию: автоматически добываю примеры использования слов для изучения иностранных языков (а именно японского по большей части).
233. Во-первых, если в предложении есть какое-то слово, то далеко не факт, что такое предложение будет хорошим примером употребления этого слова.
234. Кроме этого мы хотим достать разнообразные примеры: то если чтобы они показывали спектр использования слова как можно лучше. Чтобы в предложении были разные контексты, чтобы слово было использовано в разных смыслах.
235. Сами примеры я пытаюсь выбирать из интернета. Возникает проблема отсеивания всего того мусора, что получается, если вы попробуете использовать интернет в качестве исходных данных.
236. Почему примеры хочется собирать автоматически? Потому что наборов примеров мало. Для японского есть tatoeba.org, там всего 150 тыс примеров. И сложные слова тоже плохо покрыты. Правда есть переводы :/
237. Хотелось получить хорошие примеры и покрыть хорошие слова, чтобы учить язык на уровнях выше N3 было проще. На этом уровне материалов уже мало. Надо тренировать свою языковую модель японского и хочется делать это эффективно. Поэтому и родилась такая идея.
238. Результатом этого всего получилась kotonoha.ws - система изучения японских слов через карточки с одной фишкой. Я пытаюсь показывать слова в контексте (внутри примеров), когда это можно.
239. Ещё используются примеры из tatoeba.org, но как вопросы карточек используются автоматически полученные примеры. На скрине нужно вспомнить подчёркнутое слово.

240. Ещё мне нужны будут участники эксперимента по оценке качества “новых примеров”, которые будут пытаться лучше работать с “начинкой” примеров, чтобы целевое слово можно было более-менее понять из контекста. Это то над чем я работаю сейчас.
241. Вообще имхо проблема почти всего софта для обучения языкам: они настроены на новичков (потому что всё бабло там и это всё сравнительно просто делать). Продвинутым сложно и софта имхо почти нет.
242. Можно самостоятельно фигачить в чём-то типа анки, но это
а) для хардкорщиков (правда менее хардкорщиков, что пишут свой софт)
б) очень сложно засунуть туда свой контекст к словам, который ОБЯЗАТЕЛЬНО нужно иметь
в) он заваливает новыми карточками
а) для хардкорщиков (правда менее хардкорщиков, что пишут свой софт)
б) очень сложно засунуть туда свой контекст к словам, который ОБЯЗАТЕЛЬНО нужно иметь
в) он заваливает новыми карточками
243. Читать книжки и всякий материал это очень хорошо! Но новые слова оттуда забываются и нужно как-то пытаться держать их в памяти. А тут уже не подходит софт с готовыми уроками.
244. Но это всё мои мысли по поводу изучения языков. У вас могут быть свои мысли и свои методы по этому поводу. У каждого есть свой собственный путь ниндзя. Моя цель лишь предоставить инструменты.
245. Я слышал про ещё одно интересное необычное применение NLP к обучению: создание тематических задач по математике. Типа “у Васи 5 яблок, он отдал Маше и Оле одинаковое количество яблок. Теперь у Васи только 1 яблоко. Сколько яблок получила каждая девочка”.
246. Только мы например заменяем сеттинг и тропы в такой задаче, что она становится в мире Гарри Поттера или Звёздных войн. Задача по сути заинтересовать детей на решение математических задач, используя интересных им персонажей.
247. Тут мы плавно подошли к генерации текста, то есть железка должна выдать из себя текст, желательно новый. Предыдущие задачи в основном были анализом, где по тексту мы вычисляли какую-то информацию.
248. В примере с генерацией математических задач это делается по сути алгоритмически, без супер умных алгоритмов. У нас есть “скелет” задачи, то есть например нужно заставить детей составить уравнение.
249. На это навешиваются “сеттинги”, то есть миры: персонажи и возможные глаголы действий, затем всё дело уточняется “тропами”, то есть выбираются глаголы и объекты. Для звёздных войн это могут быть империя/повстанцы, планеты и из захват например. Военнизировенько так.
250. Но по сути дела это всё должно создаваться людьми и весьма затратно по времени.
251. Языковые модели, которые пытаются “угадывать” следующее слово можно пытаться считать генерацией. Они показывают весьма интересные результаты. Вот например нечто, что выдаёт нейросетевая языковая модель, обученная на исходниках линукса:
karpathy.github.io/2015/05/21/rnn…
karpathy.github.io/2015/05/21/rnn…
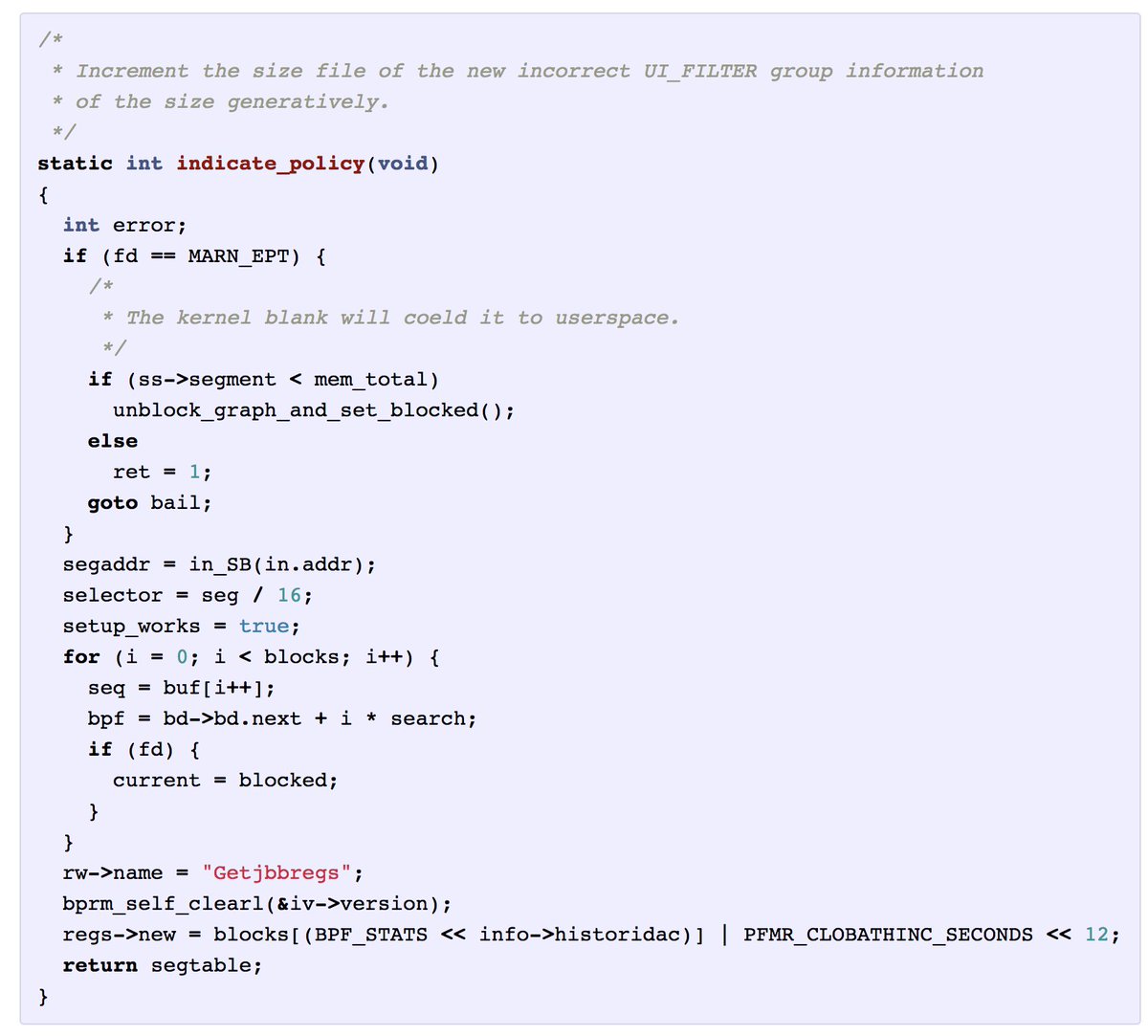
252. Эта модель была обучена на символах, не на словах. Несмотря на это она выдаёт нечто, по форме похоже на C код. Заметьте отступы и человеко-подобный язык в комментах.
253. Однако, языковые модели не могут производить новые знания. Они могут производить бред, либо могут производить нечто, очень напоминающее “средние” предложения в языке. В смысле без особенностей и интересностей.
254. У нейросетевого машинного перевода тоже есть некоторая склонность к убиранию всяких “интересных” особенностей языка.
255. Одна из областей, где больше всего пытаются использовать геренацию - это создание чатботов. Особенно попытка создания чатботов, которые могут поддержать беседу на различные и рандомные темы, аки классический тюринг-тест.
256. Классический тюринг-тест это по сути дела когда человек, используя только текстовый интерфейс, пытается 15 минут пообщаться с собеседником и по этому опыту должен выдать вердикт: железка ли собеседник или не очень.
257. Такие штуки иногда пытаются тренировать на интернет-данных и социальных сетях. Все вспомним Tay от американского Microsoft Research и её любви к Гитлеру.
258. Попытка создать такие штуки началась ещё очень давно: один из самых старых чатботов - ELIZA, аж в 1962-1964 годах. Можно сейчас пощупать в емаксе как M-x doctor. (Как выходить из емакса гуглите сами)
259. Современные подходы к чат-ботам, что могут в болтание на рандомные используют много разных подходов. Например можно использовать что-то похожее на модель нейромашинного перевода, но добавить ещё одно измерение - пара диалога.
260. Правда зачастую такие системы считают, что диалог происходит по одной реплике с каждой стороны. Что не есть правда весьма часто, посмотрите свои чаты в любой программе.
@ms_rinna 262. Лайн в России не работает, так как заблокирован ркн из-за шифрования, так что вам ринну не пощупать безо всяких ухищрений.
263. Одно странно пахнущее место в диалоговых системах это то, что часто их оценивают количеством от пользователя пока продолжается диалог, чем дольше тем лучше.
264. То есть по сути дела количеством времени, которое пользователи проводят с диалоговой системой: чем больше тем лучше.
265. Сами решайте хорошо это или плохо в общем.
266. Другой тип чатботов - это задаче-ориентированные создания: сири, гугл-помощник, умные колонки все в основном попадают в эту категорию (со смесью рандомных диалогов).
267. В задаче-ориентированных диалогах часто нужно понимать большое количество названий (всяких мест, групп, песен и прочего). Это бывает очень сложно.
268. В диалогах и генерации нас зачастую останавливает отсутствие повседневных знаний. Потому почти невозможно выдавать что-то новое (особенно принципиально новое).
269. Системы будут либо попытаться выбрать ответ из вариантов (как-то ранжировав их и выбрав лучший к примеру), или научиться генерировать из уже имеющихся диалогов.
270. Выйти из этого цикла - для этого уже нужен ОИИ.
271. В обработке картинок сейчас весьма хайпится тема adversarial generation: внутри нейросети есть генератор и дискриминатор; мы пытаемся обучить дискриминатор различать картинки из нейросети и настоящие; одновременно генератор пытается обмануть дискриминатор.
272. Это позволяет получить нейросетки, которые могут генерировать из небытия картинки, которые выглядят реалистично! Но у текста меньше проблем с реалистичностью чем у картинок. Можно писать всякую фигню и оно все равно будет текстоподобным.
273. Ещё “скрытое пространство” картинок по сути дела непрерывно. Можно поменять пару пикселей на картинке и она почти не изменится. С текстом так вот не получится. Нужно сильно менять результат. То есть скрытое пространство текста дискретно.
274. И на этом месте у меня кончились большие идеи и темы. Я надеюсь что вы стали меньше бояться компьютеров, которые выдают из себя текст. Или больше. Есть конечно разные мелочи, но это уже получится универская лекция и не будет всем интересно. Задавайте вопросы.







