Сегодня вечером обсудим: Почему я перестал доверять/верить микросервисам.
Про микросервисы у меня был отдельный большой доклад после более года участия в разработке большого проекта.
Пока его можно глянуть, а вечером пройдусь по тезисам из доклада.
Про микросервисы у меня был отдельный большой доклад после более года участия в разработке большого проекта.
Пока его можно глянуть, а вечером пройдусь по тезисам из доклада.
Начнем с плюсов и минусов:
Когда говорят про микросервисы подразумевают:
- Независимую разработку / легкость масштабирования команд
- Технологическую гетерогенность (технологии под сервис)
- Независимый деплой (выпустил patch релиз, шли его отдельно в прод)
Когда говорят про микросервисы подразумевают:
- Независимую разработку / легкость масштабирования команд
- Технологическую гетерогенность (технологии под сервис)
- Независимый деплой (выпустил patch релиз, шли его отдельно в прод)
- Переиспользуемость (написав один раз сервис нотификаций, используй в каждом проекте его)
- Продуктовая составляющая (можно продать клиентам микросервисы как разные части проекта)
- Изолированность (может быть решающим звеном для прохождения различных регуляторных compliance-ов)
- Продуктовая составляющая (можно продать клиентам микросервисы как разные части проекта)
- Изолированность (может быть решающим звеном для прохождения различных регуляторных compliance-ов)
Но даже эти плюсы не так однозначны, допустим про независимый деплой:
Представьте что ваш проект состоит из 10 микросервисов, чтобы сделать релиз, вам нужно собрать целый поезд из версий который помчится на production.
Такой поезд должен быть хорошо оттестирован.
Представьте что ваш проект состоит из 10 микросервисов, чтобы сделать релиз, вам нужно собрать целый поезд из версий который помчится на production.
Такой поезд должен быть хорошо оттестирован.
Про технологическую гетерогенность:
Иногда это реально круто работает, но зачастую у вас в штате команда людей с определённым стэком и давать ей писать на чем-то другом не имеет смысла.
Иногда это реально круто работает, но зачастую у вас в штате команда людей с определённым стэком и давать ей писать на чем-то другом не имеет смысла.
Про переиспользуемость:
Каждый проект имеет свою инфраструктуру, иногда инфраструктуры между проектами могут не совпадать и все равно придётся допиливать, но это в любом случаи лучше чем писать каждый раз один и тот же сервис :)
Каждый проект имеет свою инфраструктуру, иногда инфраструктуры между проектами могут не совпадать и все равно придётся допиливать, но это в любом случаи лучше чем писать каждый раз один и тот же сервис :)
Так как микросервисная архитектура это распределенная система, то мы получаем минусы распределенных систем.
1. На уровне БД
Когда каждый сервис имеет свою БД, и вы ходите между микросервисами используя RPC, то быть транзакционными не представляется возможным.
1. На уровне БД
Когда каждый сервис имеет свою БД, и вы ходите между микросервисами используя RPC, то быть транзакционными не представляется возможным.
Начинается изобретения своих механизмов, так называемых "state machine"/"saga" которые умеют проводить распределенные операции по сервисам и самое главное делать возврат этих действий для отмены (для консистентности бд).
Я занимался разработкой центральной системы (кошелька) внутри платежки, и для проведения транзакций мне нужно было сходить во все места. Теоретически каждый RPC может застрять, значит нужно его иметь возможность повторить или же откатить. 

И сам сервис может упасть, а другой сервис может выполнить действий и не успеть ответить за timeout. Все эти вопросы нужно как-то решать и изобретать космический корабль.
Иногда нужно сделать фильтр по данным в таблице, а поле для запроса находиться в другом микросервисе. Что делать? Денормализовывать! В итоге получаем миграции которые уже работают на уровне кода, а не простые запросы.



А миграции могут тоже упасть, значит механизм миграций должен уметь восстанавливаться или пропускать данные. А потом к вам придут с задачами про аналитику или про статику, ну вы поняли )))
2. На уровне разработки
Если у вас комплексная система, где реально много RPC, разрабатывать без тестов не возможно.
Unit/mocks RPC не самая лучшая идея, уже больно мало покрывают реально мира. В итоге для функциональных тестов нужно держать актуальную инфраструктуру на локале
Если у вас комплексная система, где реально много RPC, разрабатывать без тестов не возможно.
Unit/mocks RPC не самая лучшая идея, уже больно мало покрывают реально мира. В итоге для функциональных тестов нужно держать актуальную инфраструктуру на локале

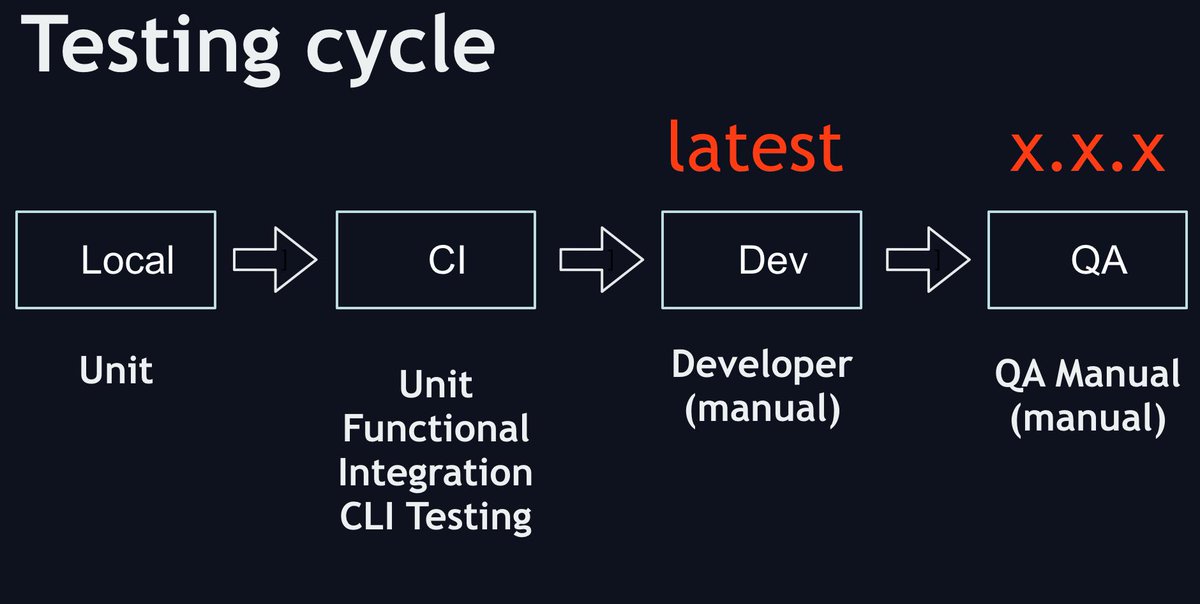
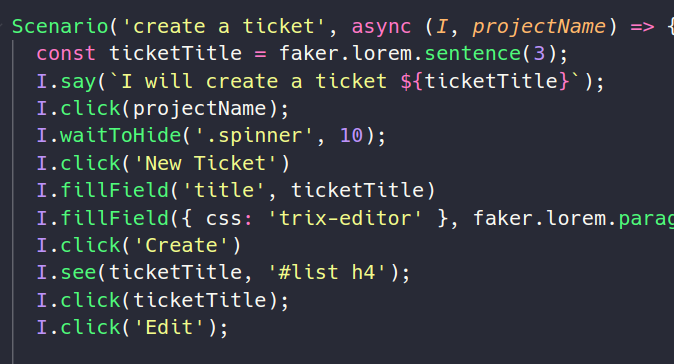
В один момент я просто перестал тестировать руками на локальной машине, начал делал unit тесты, а руками уже тестировал только на dev env. Не возможно держать все микросервисы на локале, особенно в момент старта проекта.
3. На уровне инфраструктуры:
- Нужен нормальный CI
- Без docker и k8s я вообще представить не могу микросервисы
Обо всем надо читать, все это нужно уметь, боль :(
- Нужен нормальный CI
- Без docker и k8s я вообще представить не могу микросервисы
Обо всем надо читать, все это нужно уметь, боль :(
Нужно уметь в отказоустойчивость
Падение одного сервиса не должно взорвать все, а без сетевого экрана не представляется возможным зачастую реально понять какой сервис общается с какими сервисами.
Падение одного сервиса не должно взорвать все, а без сетевого экрана не представляется возможным зачастую реально понять какой сервис общается с какими сервисами.


Чтобы понимать, что происходит, нужно уметь в distributed tracing
opentracing.io/docs/overview/…
А теперь представьте, что есть целая цепочка последовательных RPC от сервиса к сервису, и вам нужно понять, где ошибка.
opentracing.io/docs/overview/…
А теперь представьте, что есть целая цепочка последовательных RPC от сервиса к сервису, и вам нужно понять, где ошибка.
Также нужно постоянно бороться с шаблонным кодом между сервисами, а это бывает крайне сложно. А теперь представьте, что копи-пасте нашлась ошибка и вам нужно пробежаться и поправить какую-то строчку во всех 20 микросервисах.
4. Нужно уметь в организацию, если разработчики между сервисами не умеют общаться друг с другом. То вы получите реально разные системы и разные подходы, хорошие практики могут не переходить от одного разработчика к другому.

Как итог, для себя я заметил корреляции:
1. Первые 1...N микросервисов крайне сложно, дальше уже проще. (нужно много опыта)
2. Поддерживать N+1 микросервис, всегда сложнее чем N. (не старайтесь постоянно делать новые когда этого не нужно)
1. Первые 1...N микросервисов крайне сложно, дальше уже проще. (нужно много опыта)
2. Поддерживать N+1 микросервис, всегда сложнее чем N. (не старайтесь постоянно делать новые когда этого не нужно)