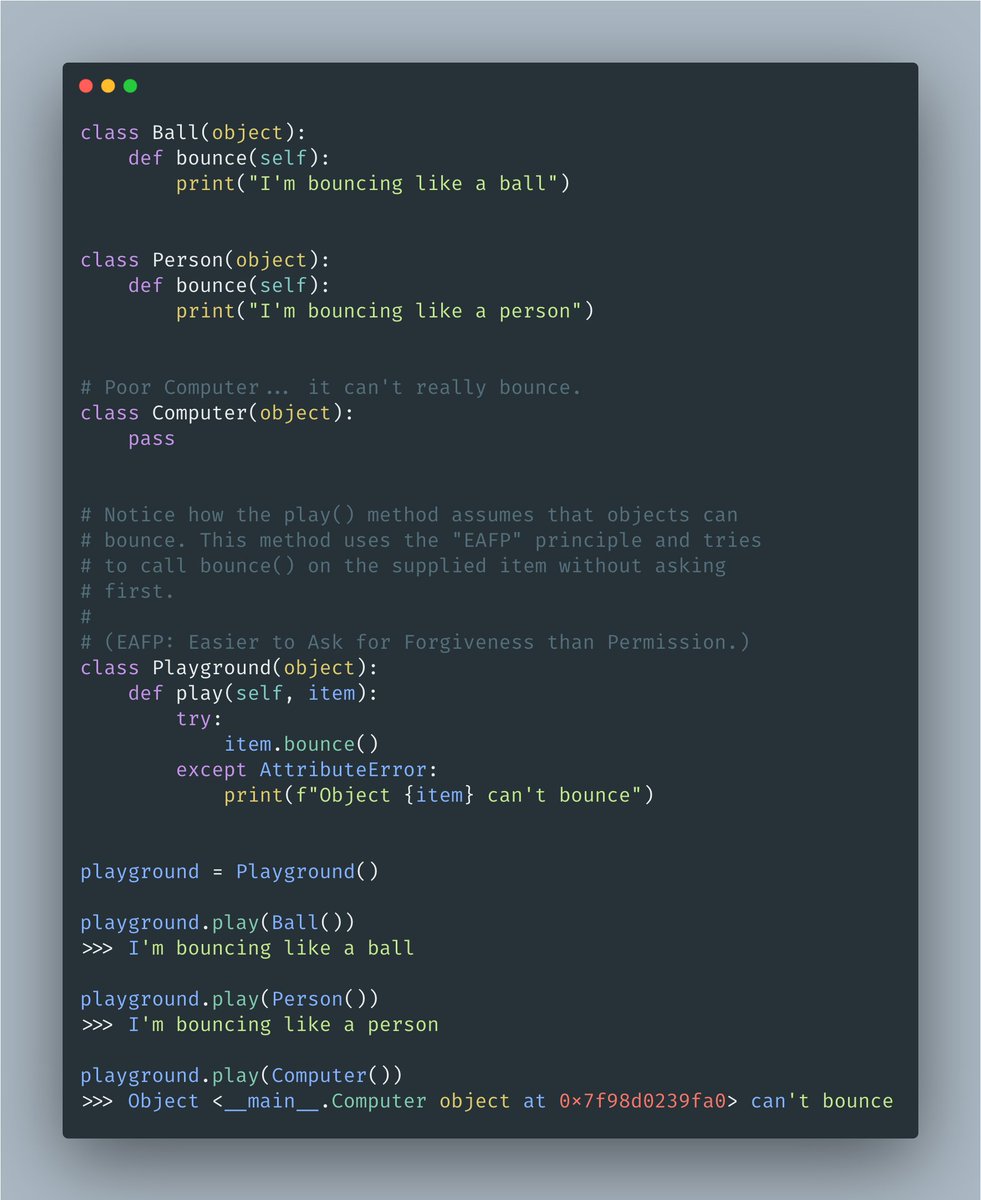
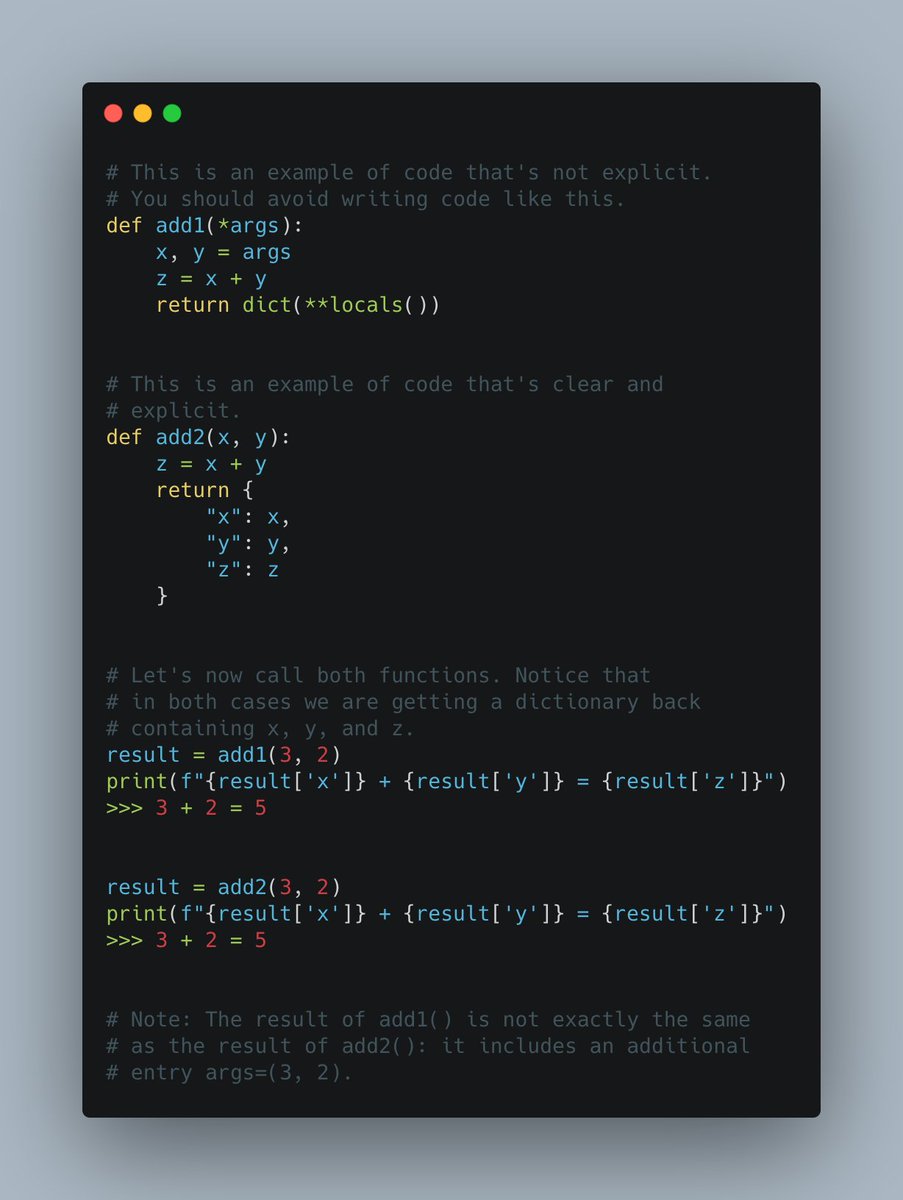
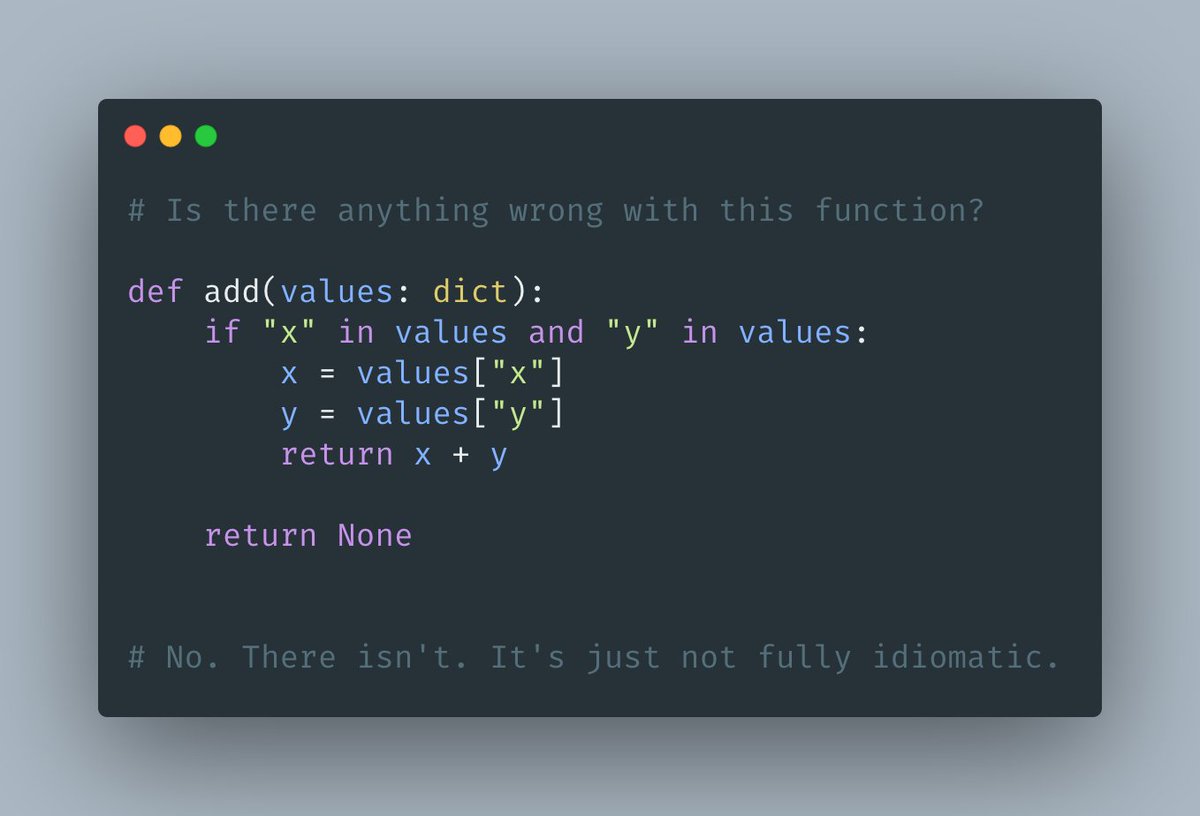
Wanna maximize the potential reward of every hour you spend?
Here is a tangible way to do this when building real-life Machine Learning solutions.
🧵👇
Here is a tangible way to do this when building real-life Machine Learning solutions.
🧵👇

Complex systems usually depend on multiple components working together to produce a solution.
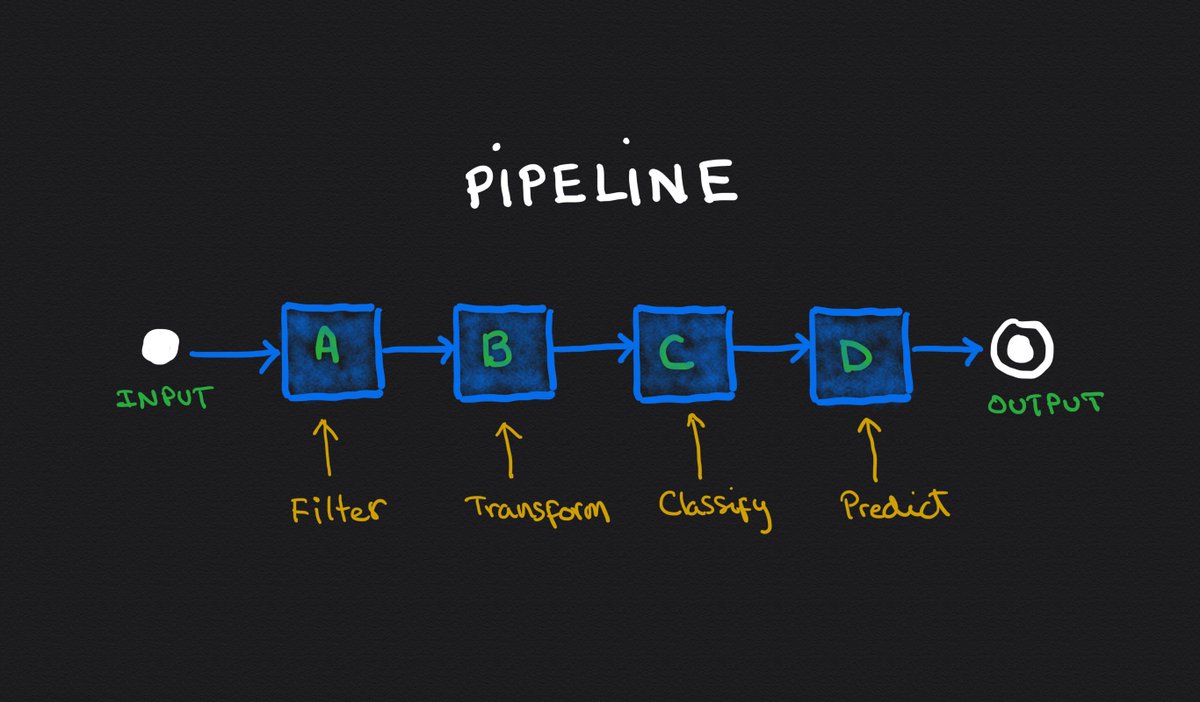
Imagine a pipeline like this, where the input goes through 4 different components before getting to the appropriate output.
👇
Imagine a pipeline like this, where the input goes through 4 different components before getting to the appropriate output.
👇
After everything is said and done, let's imagine this system is correct 60% of the time.
That sucks. We need to improve it.
Unfortunately, we tend to prioritize work in those areas where we *think* there's value. Even worse, areas that are easy or fun to change.
👇
That sucks. We need to improve it.
Unfortunately, we tend to prioritize work in those areas where we *think* there's value. Even worse, areas that are easy or fun to change.
👇
This leads to suboptimal decisions that end up wasting a ton of time.
We are scientists. We can do better than that. 😎
Let's talk about Ceiling Analysis and how it gives us a platform to decide where to zero-in and make a difference.
👇
We are scientists. We can do better than that. 😎
Let's talk about Ceiling Analysis and how it gives us a platform to decide where to zero-in and make a difference.
👇
This is what we are going to do:
1⃣Replace a component with a mocked solution that provides 100% accurate results.
2⃣Measure the overall impact.
3⃣Repeat with another component.
This will help us find the ceiling of potential improvements.
👇
1⃣Replace a component with a mocked solution that provides 100% accurate results.
2⃣Measure the overall impact.
3⃣Repeat with another component.
This will help us find the ceiling of potential improvements.
👇
Let's start with "Filter".
We are going to override it with a pre-defined 100% correct answer.
(We are basically cheating so we can determine the impact of improving this individual component.)
Then measure the overall solution and write down the result (63% in this case)
👇
We are going to override it with a pre-defined 100% correct answer.
(We are basically cheating so we can determine the impact of improving this individual component.)
Then measure the overall solution and write down the result (63% in this case)
👇

We do the same for all the components in our solution.
Remember: each iteration progressively overrides one component at a time.
1. A
2. A + B
3. A + B + C
4. A + B + C + D
Obviously, the last iteration gives you 100% correct results.
👇
Remember: each iteration progressively overrides one component at a time.
1. A
2. A + B
3. A + B + C
4. A + B + C + D
Obviously, the last iteration gives you 100% correct results.
👇

Now, it's time to determine where do we want to focus our time.
Here is the maximum increase we'd get from improving each component:
A. 3% increase
B. 2% increase
C. 16% increase
D. 19% increase
Pretty clear that we want to focus on either D or C, right?
Here is the maximum increase we'd get from improving each component:
A. 3% increase
B. 2% increase
C. 16% increase
D. 19% increase
Pretty clear that we want to focus on either D or C, right?

Ceiling analysis is extremely powerful and informative. It has been my go-to compass to shine a light on the road ahead.
Every time you find yourself needing to determine what should come next, think about this.
Every time you find yourself needing to determine what should come next, think about this.
• • •
Missing some Tweet in this thread? You can try to
force a refresh