Overfitting sucks.
Here are 7 ways you can deal with overfitting in Deep Learning neural networks.
🧵👇
Here are 7 ways you can deal with overfitting in Deep Learning neural networks.
🧵👇

A quick reminder:
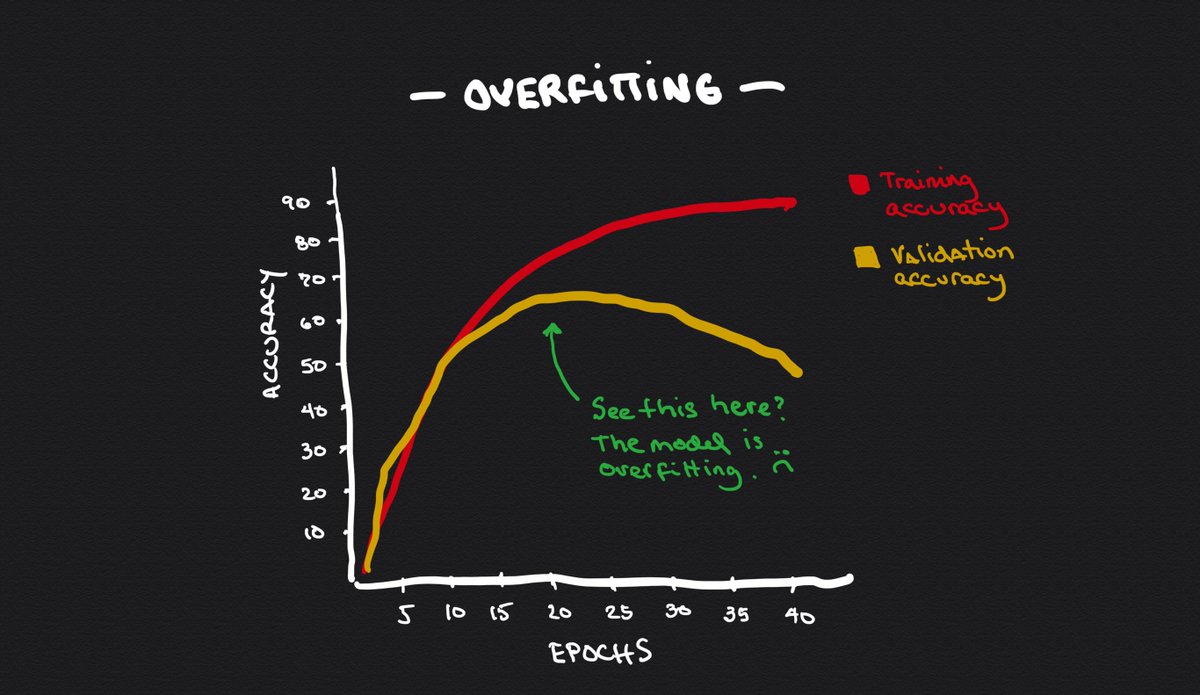
When your model makes good predictions on the same data that was used to train it but shows poor results with data that hasn't seen before, we say that the model is overfitting.
The model in the picture is overfitting.
👇
When your model makes good predictions on the same data that was used to train it but shows poor results with data that hasn't seen before, we say that the model is overfitting.
The model in the picture is overfitting.
👇
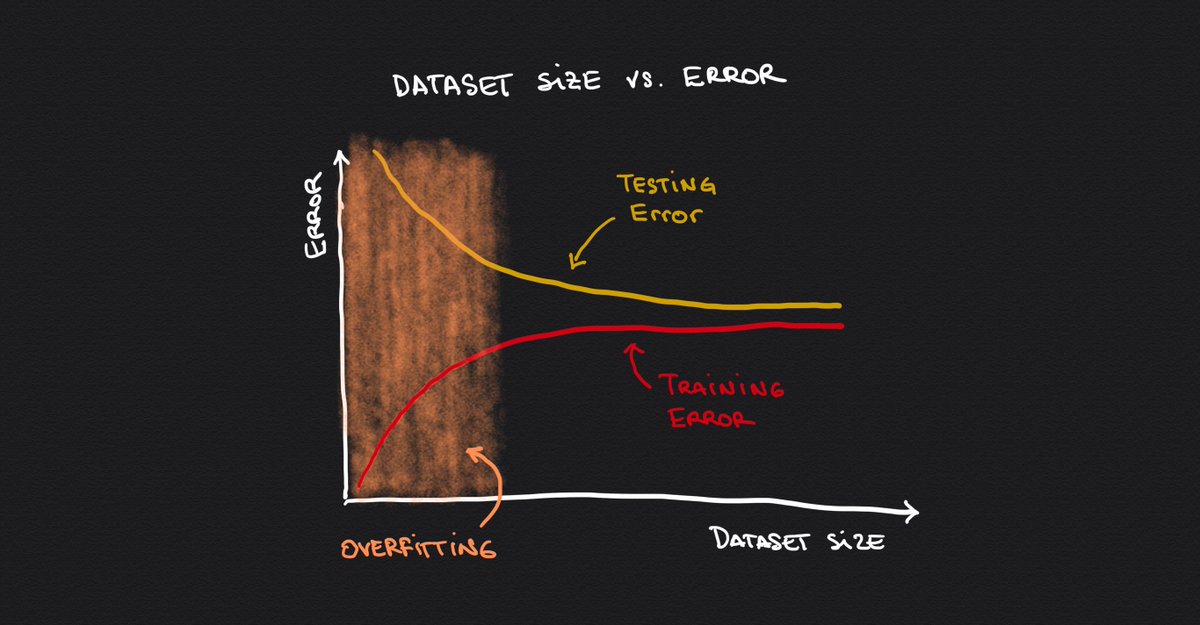
1⃣ Train your model on more data
The more data you feed the model, the more likely it will start generalizing (instead of memorizing the training set.)
Look at the relationship between dataset size and error.
(Unfortunately, sometimes there's no more data.)
👇
The more data you feed the model, the more likely it will start generalizing (instead of memorizing the training set.)
Look at the relationship between dataset size and error.
(Unfortunately, sometimes there's no more data.)
👇
2⃣ Augment your dataset
You can automatically augment your dataset by transforming existing images in different ways to make the data more diverse.
Some examples:
▫️Zoom in/out
▫️Contrast changes
▫️Horizontal/vertical flips
▫️Noise addition
👇
You can automatically augment your dataset by transforming existing images in different ways to make the data more diverse.
Some examples:
▫️Zoom in/out
▫️Contrast changes
▫️Horizontal/vertical flips
▫️Noise addition
👇
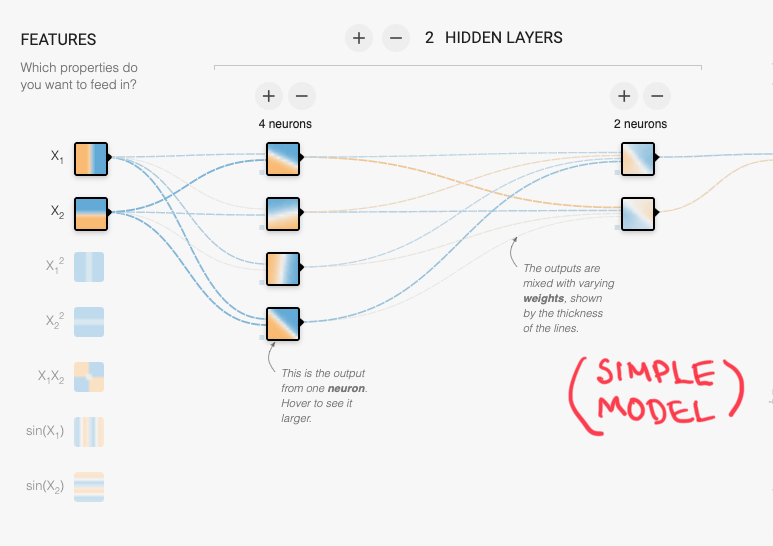
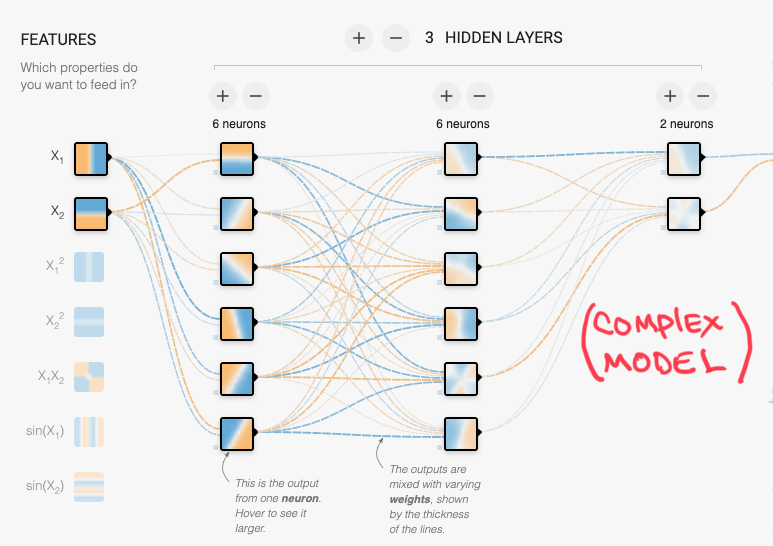
3⃣ Make your model simpler
You can:
▫️Reduce the number of layers
▫️Reduce the number of weights
The more complex your model is, the more capacity it has to memorize the dataset (hence, the easier it will overfit.)
Simplifying the model will force it to generalize.
👇
You can:
▫️Reduce the number of layers
▫️Reduce the number of weights
The more complex your model is, the more capacity it has to memorize the dataset (hence, the easier it will overfit.)
Simplifying the model will force it to generalize.
👇
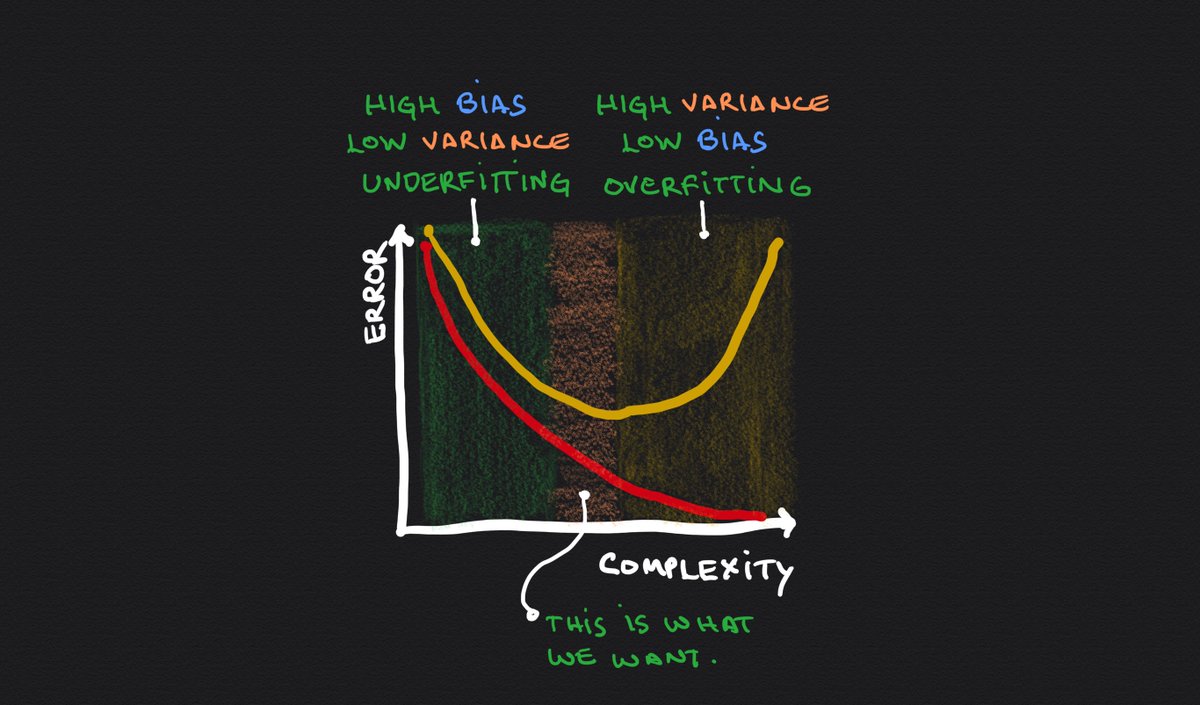
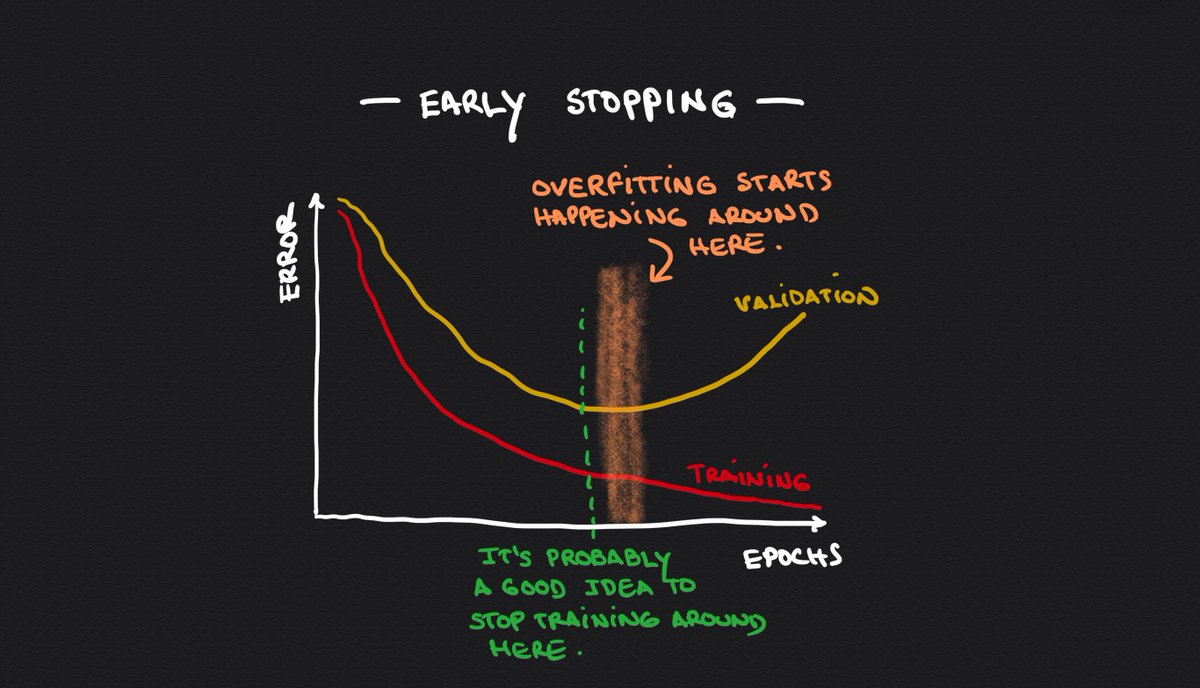
4⃣ Stop the learning process before overfitting
This is known as "Early Stopping."
Identify when overfitting starts happening and stop the learning process before it does.
Plotting the training and validation errors will give you what you need for this.
👇
This is known as "Early Stopping."
Identify when overfitting starts happening and stop the learning process before it does.
Plotting the training and validation errors will give you what you need for this.
👇
5⃣ Standardize input data
Smaller weights can result in a model less prone to overfit.
Rescaling input data is a way to constraint these weights and keep them from increasing disproportionally.
👇
Smaller weights can result in a model less prone to overfit.
Rescaling input data is a way to constraint these weights and keep them from increasing disproportionally.
👇
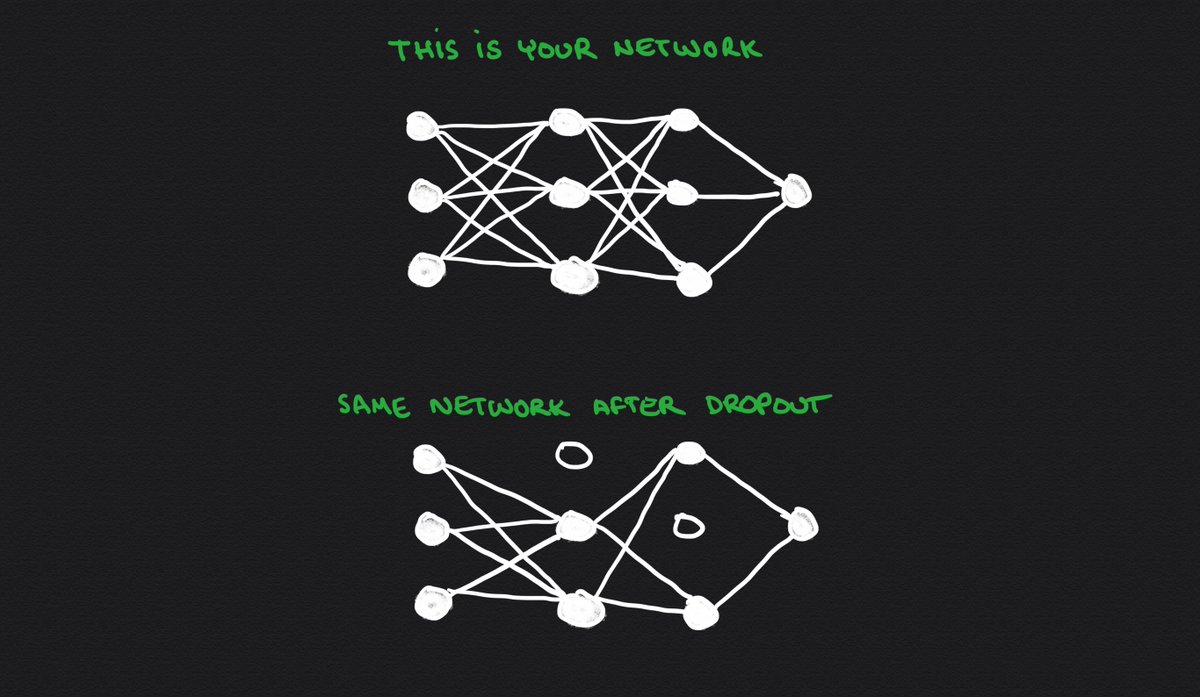
6⃣ Use Dropouts
Dropout is a regularization method that randomly ignores some of the outputs of a layer.
This simulates the process of training different neural networks with different architectures in parallel, which is a way to avoid overfitting.
machinelearningmastery.com/dropout-for-re…
Dropout is a regularization method that randomly ignores some of the outputs of a layer.
This simulates the process of training different neural networks with different architectures in parallel, which is a way to avoid overfitting.
machinelearningmastery.com/dropout-for-re…
7⃣ L1 and L2 regularization
These refer to a technique that penalizes the loss function to keep the weights of the network constrained.
This means that the network is forced to generalize better because it can't grow the weights without limit.
👇
These refer to a technique that penalizes the loss function to keep the weights of the network constrained.
This means that the network is forced to generalize better because it can't grow the weights without limit.
👇
Is there anything else you use to prevent your models from overfitting?
• • •
Missing some Tweet in this thread? You can try to
force a refresh