
This week we've learnt how to perform inference with a latent variable 👻 energy 🔋 based model. 🤓
These models are very convenient when we cannot use a standard feed-forward net that maps vector to vector, and allow us to learn one-to-many and many-to-one relationships.
These models are very convenient when we cannot use a standard feed-forward net that maps vector to vector, and allow us to learn one-to-many and many-to-one relationships.
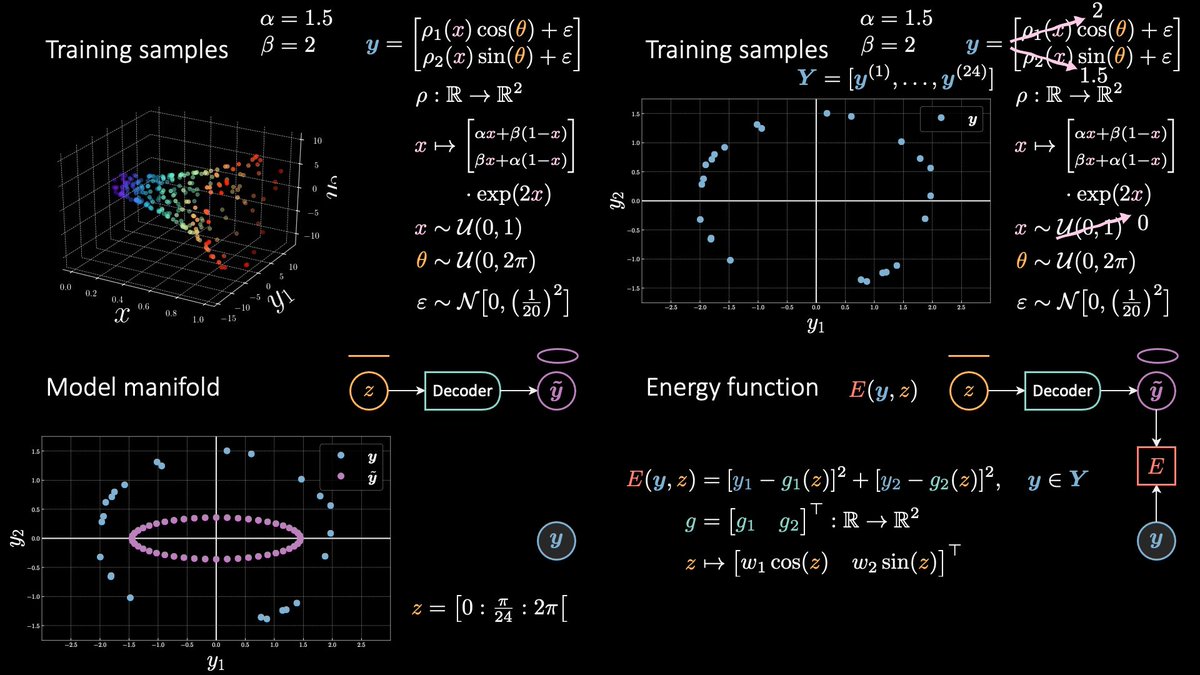



Take the example of the horn 📯 (this time I drew it correctly, i.e. points do not lie on a grid 𐄳). Given an x there are multiple correct y's, actually, there is a whole ellipse (∞ nb of points) that's associated with it!
Or, forget the x, even considering y alone…
Or, forget the x, even considering y alone…
there are (often) two values of y₂ per a given y₁! Use MSE and you'll get a point in the middle… which is WRONG.
What's a “latent variable” you may ask now.
Well, it's a ghost 👻 variable. It was indeed used to generate the data (θ) but we don't have access to (z).
What's a “latent variable” you may ask now.
Well, it's a ghost 👻 variable. It was indeed used to generate the data (θ) but we don't have access to (z).
So, it went missing.
How to recover it?
Well, we can simply find the one that minimises our energy.
Then, what's this “energy”?
Okay, okay, I'm getting there. It represents the level of compatibility between x, y, z. x being your input, y the target, and z the latent.
How to recover it?
Well, we can simply find the one that minimises our energy.
Then, what's this “energy”?
Okay, okay, I'm getting there. It represents the level of compatibility between x, y, z. x being your input, y the target, and z the latent.
So, given that we have access to this energy E, we can find a value for z (blue ❌ below) that minimises the degree of annoying the model. The value of E at that location is called “free energy” or Fₒₒ (this is also called the zero-temperature limit of E).

This lesson first part has been recorded and will come up online, together with the slides, next week or so. You'll find it on the class website together with a transcript put together by this semester students.
Next week we'll cover the second part, where we'll learn about the latent marginalisation, training for unconditional and conditional cases, and we'll have a look at the notebook I've put together to craft this lecture.
Thanks for reading. 👀
Keep learning! 🎓
🤓😋❤️
Thanks for reading. 👀
Keep learning! 🎓
🤓😋❤️
• • •
Missing some Tweet in this thread? You can try to
force a refresh






