So many fascinating ideas at yesterday's #blackboxNLP workshop at #emnlp2020. Too many bookmarked papers. Some takeaways:
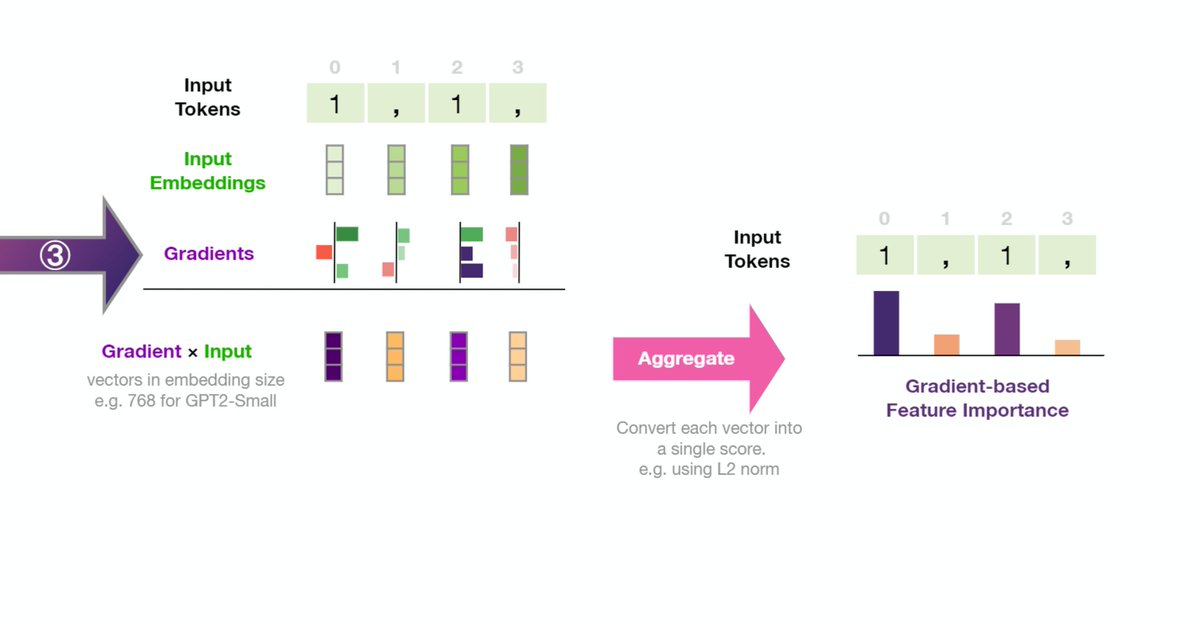
1- There's more room to adopt input saliency methods in NLP. With Grad*input and Integrated Gradients being key gradient-based methods.
1- There's more room to adopt input saliency methods in NLP. With Grad*input and Integrated Gradients being key gradient-based methods.

2- NLP language model (GPT2-XL especially -- rightmost in graph) accurately predict neural response in the human brain. The next-word prediction task robustly predicts neural scores. @IbanDlank @martin_schrimpf @ev_fedorenko
biorxiv.org/content/10.110…
biorxiv.org/content/10.110…

This line investigating the human brain's "core language network" using fMRI is helping build hypotheses of what IS a language task and what is not. e.g. GPT3 doing arithmetic is beyond what the human brain language network is responsible for
biorxiv.org/content/10.110…
biorxiv.org/content/10.110…
3- @roger_p_levy shows another way of comparing language models against the human brain in reading comprehension: humans take longer to read unexpected words -- that time correlates with the NLP model probability scores
cognitivesciencesociety.org/cogsci20/paper…
cognitivesciencesociety.org/cogsci20/paper…
https://twitter.com/roger_p_levy/status/1329849700091092996
4- Causal graphs are slowly trickling in. An effort to empower NLP models with aspects of causal inference (see: @yudapearl's Book of Why)
aclweb.org/anthology/2020…
aclweb.org/anthology/2020…
aclweb.org/anthology/2020…
arxiv.org/pdf/2005.13407…
aclweb.org/anthology/2020…
aclweb.org/anthology/2020…
aclweb.org/anthology/2020…
arxiv.org/pdf/2005.13407…




• • •
Missing some Tweet in this thread? You can try to
force a refresh