Stitching together my previous tweets on @dyanacek's session (BLD205) on "Monitoring production services at Amazon" so it's easier to share
#aws #reinvent2020
virtual.awsevents.com/media/1_4nwtxc…
#aws #reinvent2020
virtual.awsevents.com/media/1_4nwtxc…
"For amazon.com we found the "above the fold" latency is what customers are the most sensitive to" 

This is an interesting insight, that not all service latencies are equal and that improving the overall page latency might actually end up hurting the user experience if it negatively impacts the "above the fold" latency as a result. 💡
It's one of those insights that seems so obvious once it's been pointed out. But if you're just looking at your microservice's latency rather than looking at the whole UX holistically, it's easy to fall into optimizing things that don't move the needle.
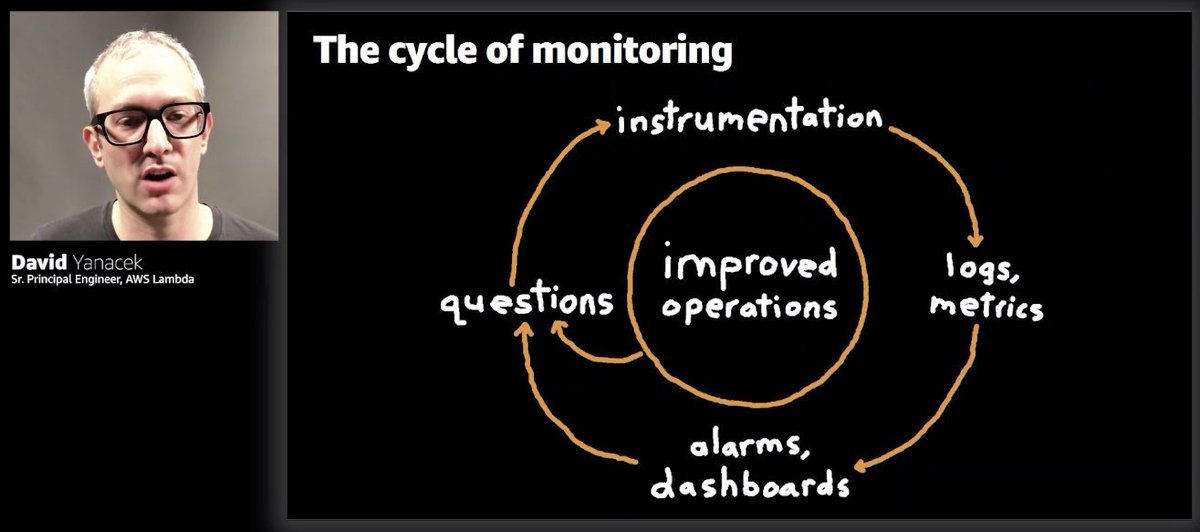
"Instrumentation needs to be as easy as possible"
That's music to my ears, need to make it easy for people to do the right thing. That's why folks at @Lumigo take a lot of pride at its auto-instrumentation capability.
That's music to my ears, need to make it easy for people to do the right thing. That's why folks at @Lumigo take a lot of pride at its auto-instrumentation capability.

This is a great tip! 💰💰💰
Create separate metrics based on query cost, so you remove noise from your latency metrics 🤯
Create separate metrics based on query cost, so you remove noise from your latency metrics 🤯



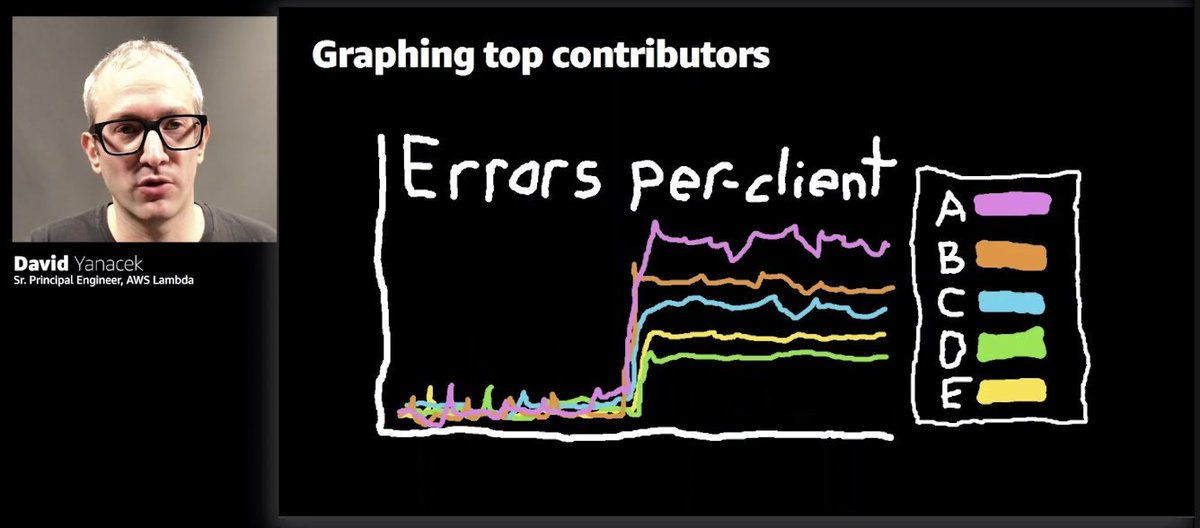
And here's another one - use CloudWatch contributor insights to look at per-client error rate to filter out the noise in client errors.
You can get an approximation of % of clients who are experiencing any kind of errors. It's a stable metric and suitable for alarming.
You can get an approximation of % of clients who are experiencing any kind of errors. It's a stable metric and suitable for alarming.


haha, this has happened to me so many times before! Took me a while to eventually learn 😂
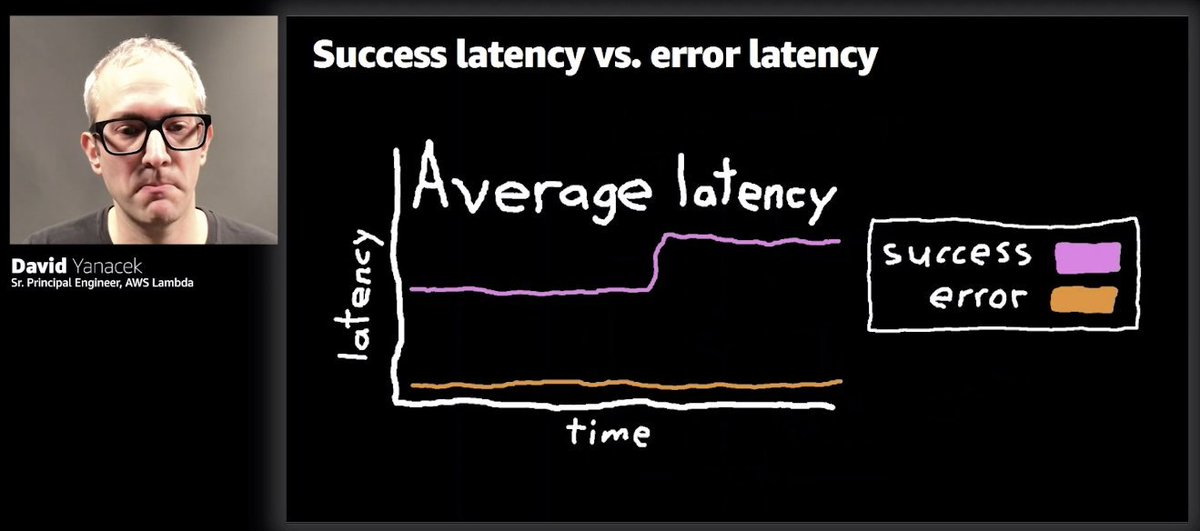
tip - separate latency metrics for success and failures
#reInvent2020
tip - separate latency metrics for success and failures
#reInvent2020

• • •
Missing some Tweet in this thread? You can try to
force a refresh