
So excited to begin to share this system for knowledge synthesis I've been developing (in conversation w/ affordances of @RoamResearch, my own pain points as a researcher, and the scientific literature on tools for thought)!
A 🧵for context 👇
https://twitter.com/RobertHaisfield/status/1343232768608636934
A 🧵for context 👇
The motivation for this system is to empower as many people as possible to do effective knowledge synthesis
Synthesis --- such as an effective theory or model, a systematic review, or critical review of existing knowledge to identify the most important knowledge gaps - is a crucial engine of scientific progress
My favorite source for this is Strike and Posner
My favorite source for this is Strike and Posner


A few examples to illustrate the power of synthesis for conceptual progress:
First, @AdamMarblestone's Technological Roadmapping, which synthesizes bodies of work to identify "gems hidden in plain sight" (described well in this podcast w/ @Ben_Reinhardt: ideamachinespodcast.com/adam-marblesto…)
First, @AdamMarblestone's Technological Roadmapping, which synthesizes bodies of work to identify "gems hidden in plain sight" (described well in this podcast w/ @Ben_Reinhardt: ideamachinespodcast.com/adam-marblesto…)


Another example is a humble book chapter that launched Esther Duflo's Nobel-Prize winning work: promarket.org/2019/10/14/est…

And finally, Darwin's masterful synthesis of a massive body of evidence to generate a theory of the origin of species, whose impact on biology is hard to exaggerate. The long process by which this synthesis happened is analyzed nicely in this book: amazon.com/Darwin-Man-Psy…
Yet, effective synthesis is rarer than we'd like. It's hard to measure directly, but there are hints in poor synthesis in dissertations, complaints of subpar lit reviews by journal editors




This isn't great for science. Per Allen Newell, "You can't play twenty questions with nature and win".
Fields vary in how bad this problem is, but in my home field of psych, we have recurring criticisms of the lack of synthesis/theory:
Fields vary in how bad this problem is, but in my home field of psych, we have recurring criticisms of the lack of synthesis/theory:
https://twitter.com/IrisVanRooij/status/1307069924666470400
I suspect this is an underappreciated reason for observed slowdowns in scientific progress (good overview for this phenomenon by @ArtirKel here: nintil.com/ideas-harder-f…). We're often flying blind!
If we grant that effective synthesis is rarer than we'd like, we can ask why. Personally, I'm focused on how hard it is. Yes, intellectually it's hard, but also.... think about the tools we have for the job (Zotero, Google Docs, spreadsheets, etc.). Are they up to the task?
Two examples that point to substantial inefficiencies.
First, a wonderful cognitive work analysis of a systematic review team, choosing to summarize their experience as being "enslaved to the trapped data"
First, a wonderful cognitive work analysis of a systematic review team, choosing to summarize their experience as being "enslaved to the trapped data"

This experience might partially explain why so many systematic reviews take so long to complete, and many are not updated even when they need to be (rendering them obsolete!)


Second, some reflections from @AdamMarblestone about the lack of systematic, tuned tools to do synthesis work like Technological Roadmapping in this podcast (~25 and ~30 mins or so): ideamachinespodcast.com/adam-marblesto…
W/ collaborators, I've argued that our tools (search engines / lit review tools) aren't really tuned for synthesis: we want to discover and analyze concepts/findings/ideas, but our infrastructure and tools emphasize the *paper* as the unit of analysis: dl.acm.org/doi/10.1145/33…

We've been investigating over the last couple years what tools/processes might look like that are tuned to synthesis: enabling people to find and analyze the right units of analysis in a way that minimizes overhead so we can focus on the actual task of synthesis
One aspect of this is tools for individual synthesis that are well-tuned for the job
Another aspect is systems that enable us to distribute the work of synthesis (e.g., reusing intermediate products of synthesis from others instead of starting from scratch almost every time)
Another aspect is systems that enable us to distribute the work of synthesis (e.g., reusing intermediate products of synthesis from others instead of starting from scratch almost every time)
The vision for this line of work can be seen in this (not super polished) set of slides: drive.google.com/file/d/1nMNl89…
Early prototype for a specialized scientific paper reader here: (focus on specifying context, can see echoes of this in the context snippets portion of the current model). Latest pre-Roam work described here: dl.acm.org/doi/10.1145/33…
It turns out this vision is basically the same as @RoamResearch ! I discovered this roughly in November 2019, in this video demo (and the whitepaper: roamresearch.com/#/app/help/pag…
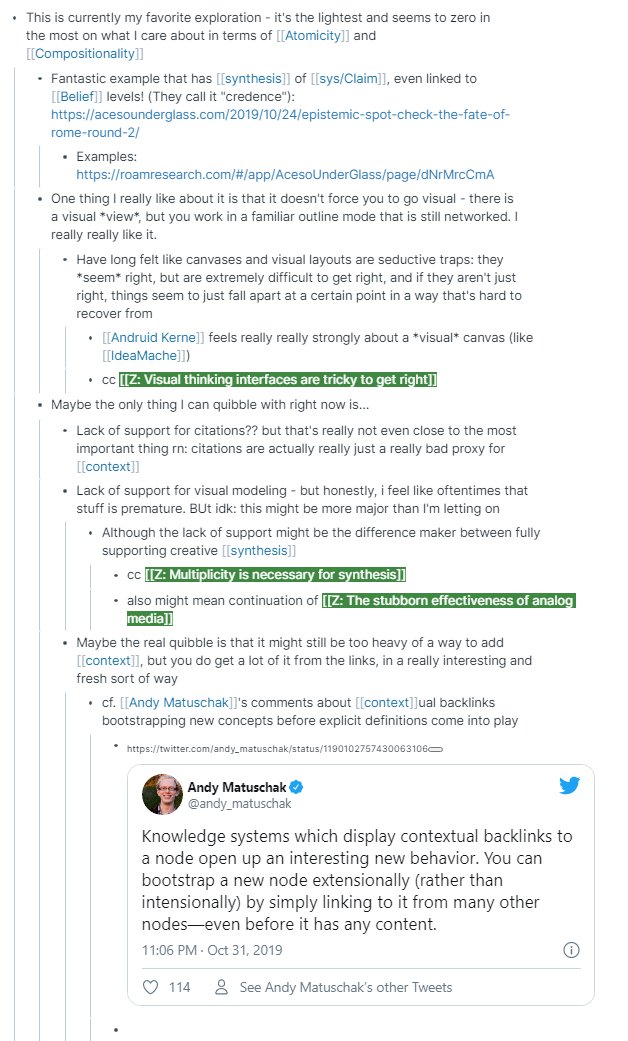
Which brings us back to this system for synthesis in @RoamResearch - it's an ongoing research project, with a vision for basically augmenting collective intelligence (by individually augmenting synthesis, and also making it possible to distribute synthesis)
Having explored independently how to build tools for synthesis, I was prepared and excited to see how @RoamResearch is so well-tuned as an environment for knowledge synthesis (see these notes I wrote about it ~Nov 2019), and this short @RoamBrain post: roambrain.com/knowledge-synt…
My early explorations of this in ~Apr 2020 showed significant promise for this, as seen in my first convo with @RobertHaisfield:
(some other context for this in my chat with @RoamFm here:
https://twitter.com/RobertHaisfield/status/1254129270709862400
(some other context for this in my chat with @RoamFm here:
https://twitter.com/RoamFm/status/1326042642287714306)
My ongoing work in and on @RoamResearch as an environment for augmented synthesis has only continued to solidify my assessment of its potential. My colleagues have seen me use this seriously, and my students are starting to learn the system.
My confidence that this is a system worth exploring is continuing to grow. I'd like to invite #roamcult academics (and anyone else interested in knowledge synthesis) to give this a spin. The writeup (in progress) is here: oasislab.pubpub.org/pub/54t0y9mk/r…
If this sounds interesting to you, please get in touch (DM here, Slack, email)! I'd love to explore further how we might build shared standards for augmented individual synthesis that also open up paths to augmenting distributed/collective synthesis. /fin
• • •
Missing some Tweet in this thread? You can try to
force a refresh





