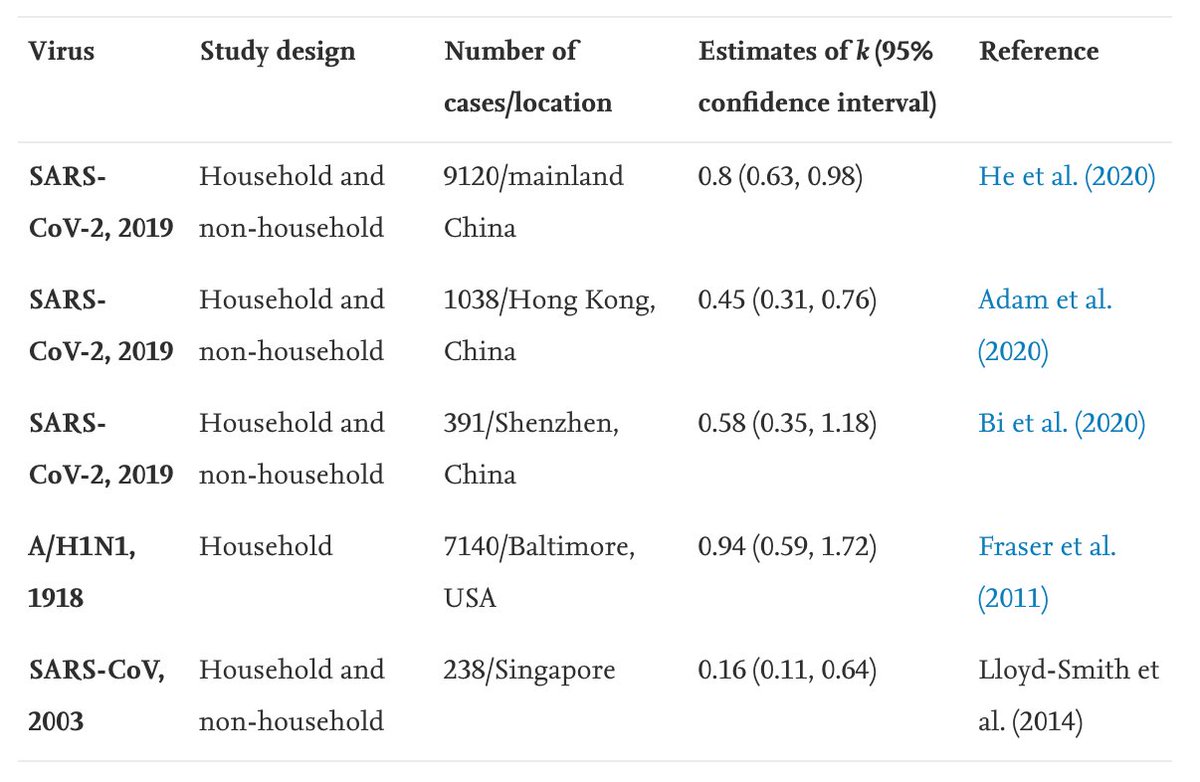
Below report also includes data on secondary attack rate for old UK variants vs new variant VOC 202012/01: 
https://twitter.com/SMHopkins/status/1343678566840545291

Secondary attack rate measures transmission risk per-contact, so above suggests difference between groups spreading old and new variant isn't down to one group simply having more contacts. This is consistent with data from our recent pre-print (cmmid.github.io/topics/covid19…)

In other words, it seems the new variant VOC 202012/01 has a different ’T’ to the old one.
https://twitter.com/AdamJKucharski/status/1320797430124863488?s=20
There may also be some change to 'S' if there are age-specific differences at play (which are yet to be confirmed).
• • •
Missing some Tweet in this thread? You can try to
force a refresh