Some people are interpreting the below study as evidence that people who test positive without symptoms won't spread infection, but it's not quite that simple. A short thread on epidemic growth and timing of infections... 1/
https://twitter.com/AdamJKucharski/status/1329841203727265792
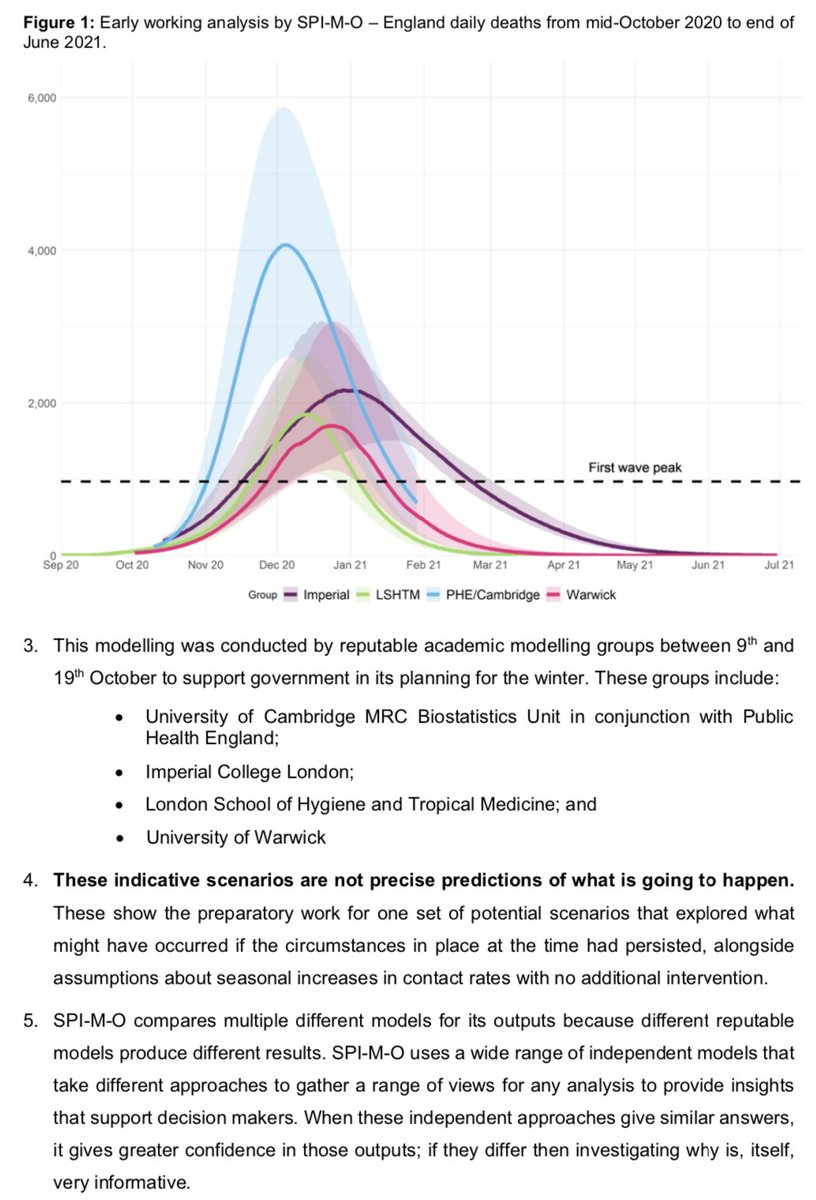
If we assume most transmission comes from those who develop symptoms, there are 2 points where these people can test positive without having symptoms - early in their infection (before symptoms appear) & later, once symptoms resolved (curve below from: cmmid.github.io/topics/covid19…) 2/ 
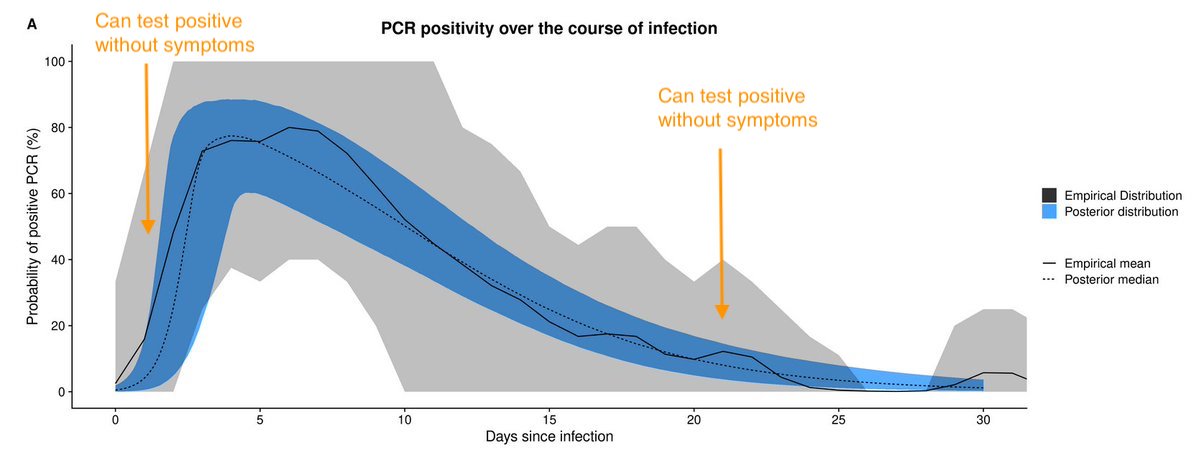
So if people test positive without symptoms, are they more likely to be early in their infection or later? Well, it depends on the wider epidemic... 3/
If epidemic is growing, majority of infections will have occurred recently (because that's definition of growing). As a result, people more likely to be early in their infection than later. So +ve tests without symptoms are more likely to be on left hand side of this curve. 4/
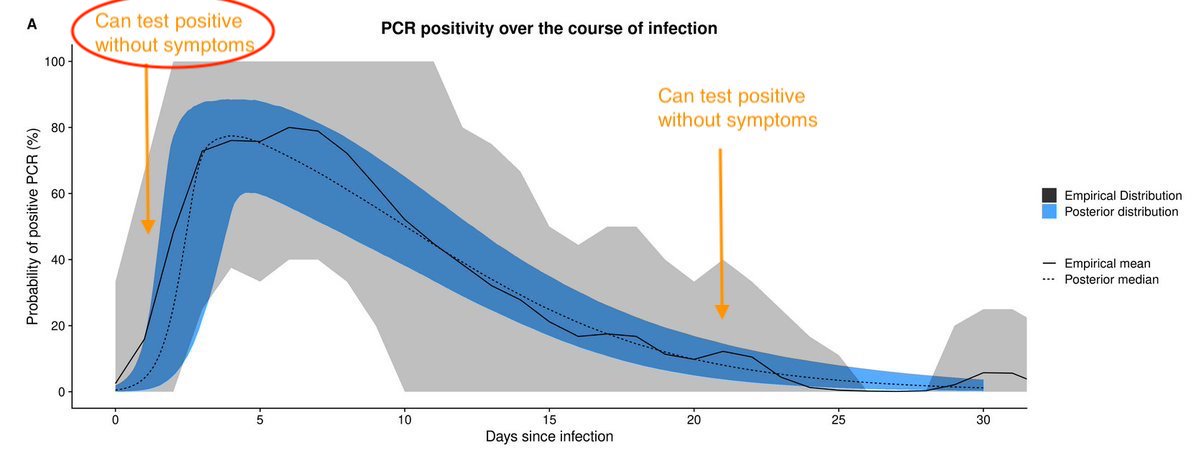
This means having a lot of people testing positive without symptoms isn't particularly reassuring, because they may well transmit & become symptomatic in near future... 5/
In contrast, if epidemic declining, most people who test +ve will be later in their infection. So less likely to be infectious in near future. This is situation with above Wuhan study. Outbreak was over when study done, so +ve tests likely to be people infected a while ago. 5/
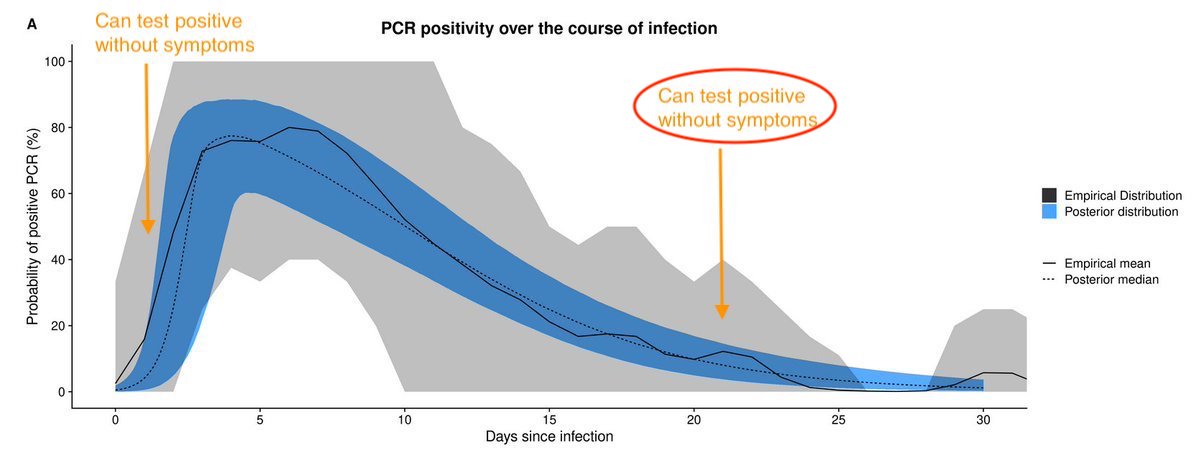
It's an important distinction to make, because it's the difference between saying '+ve tests without symptoms can't spread infection' and '+ve tests without symptoms may yet spread infection'. Given epidemics have been growing in many places recently, latter more likely. 6/
As a final note, this 'growing epidemic = people are earlier in infection' issue also has implications for screening measures, e.g. elifesciences.org/articles/05564.
• • •
Missing some Tweet in this thread? You can try to
force a refresh