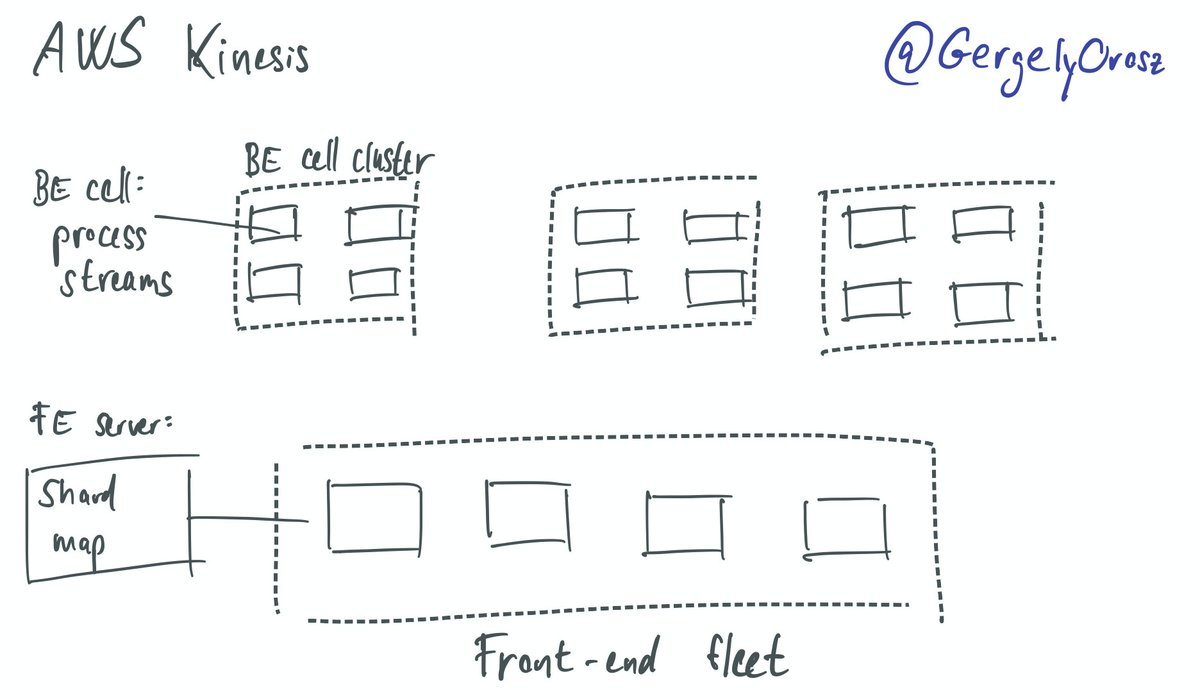
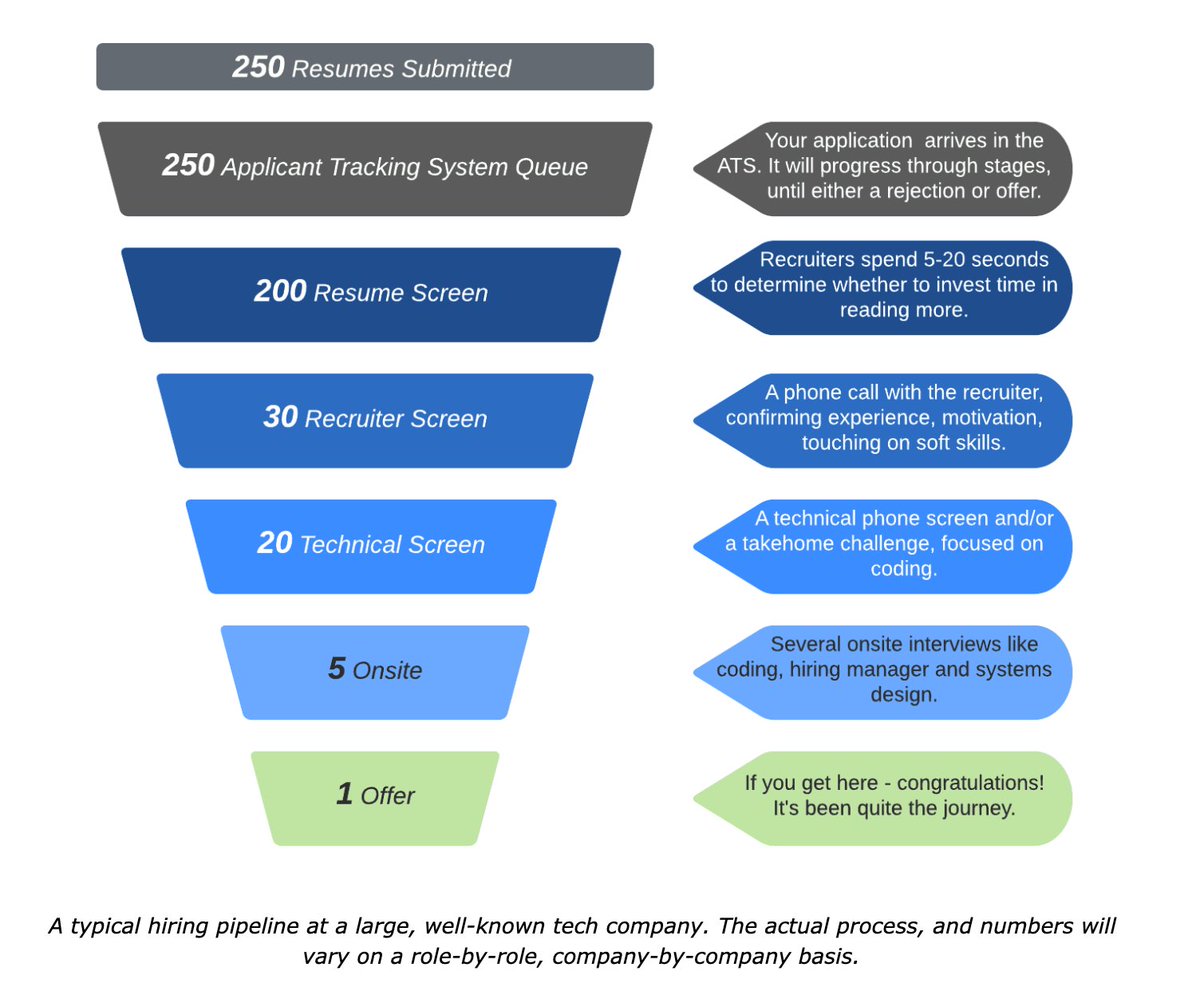
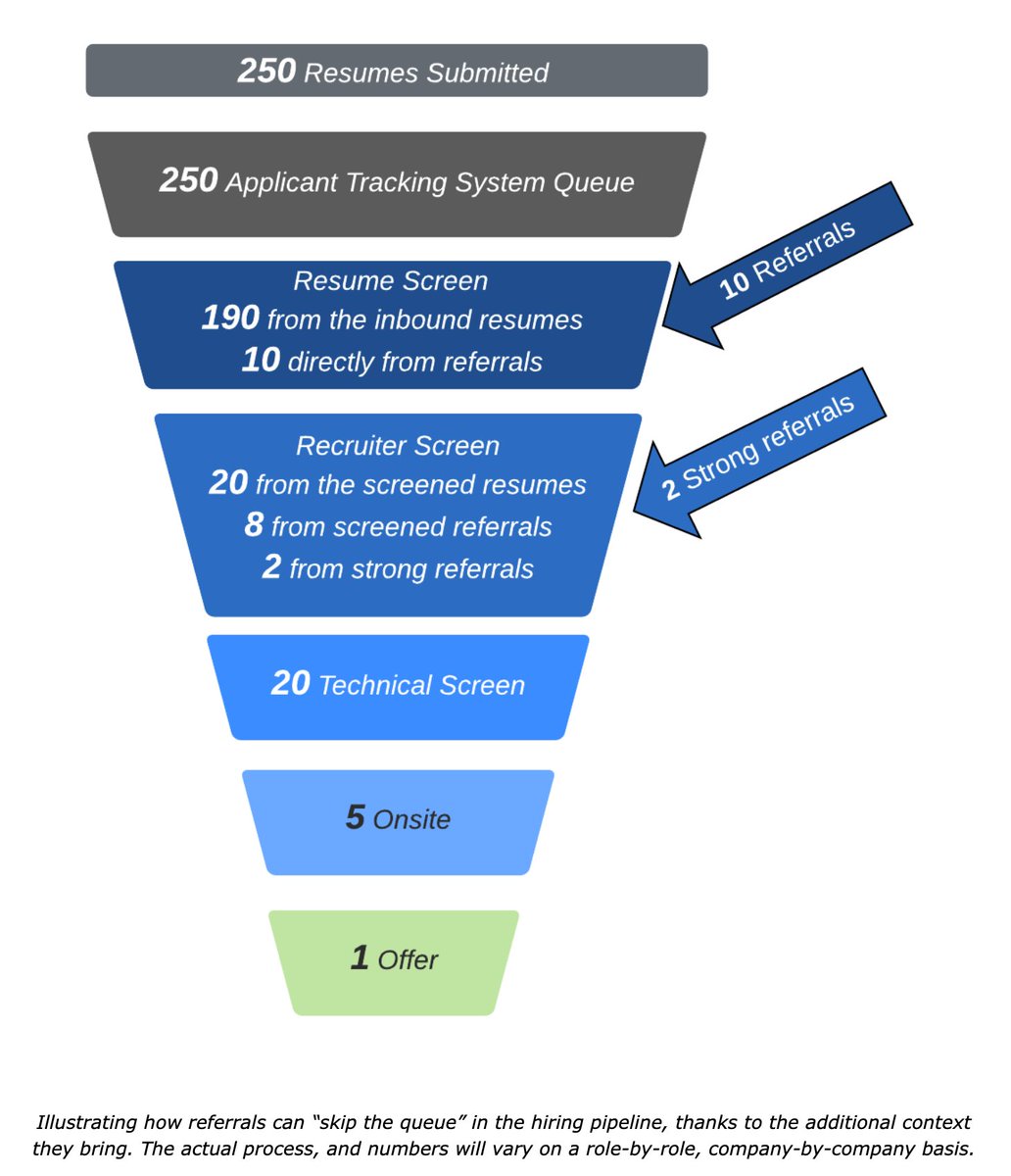
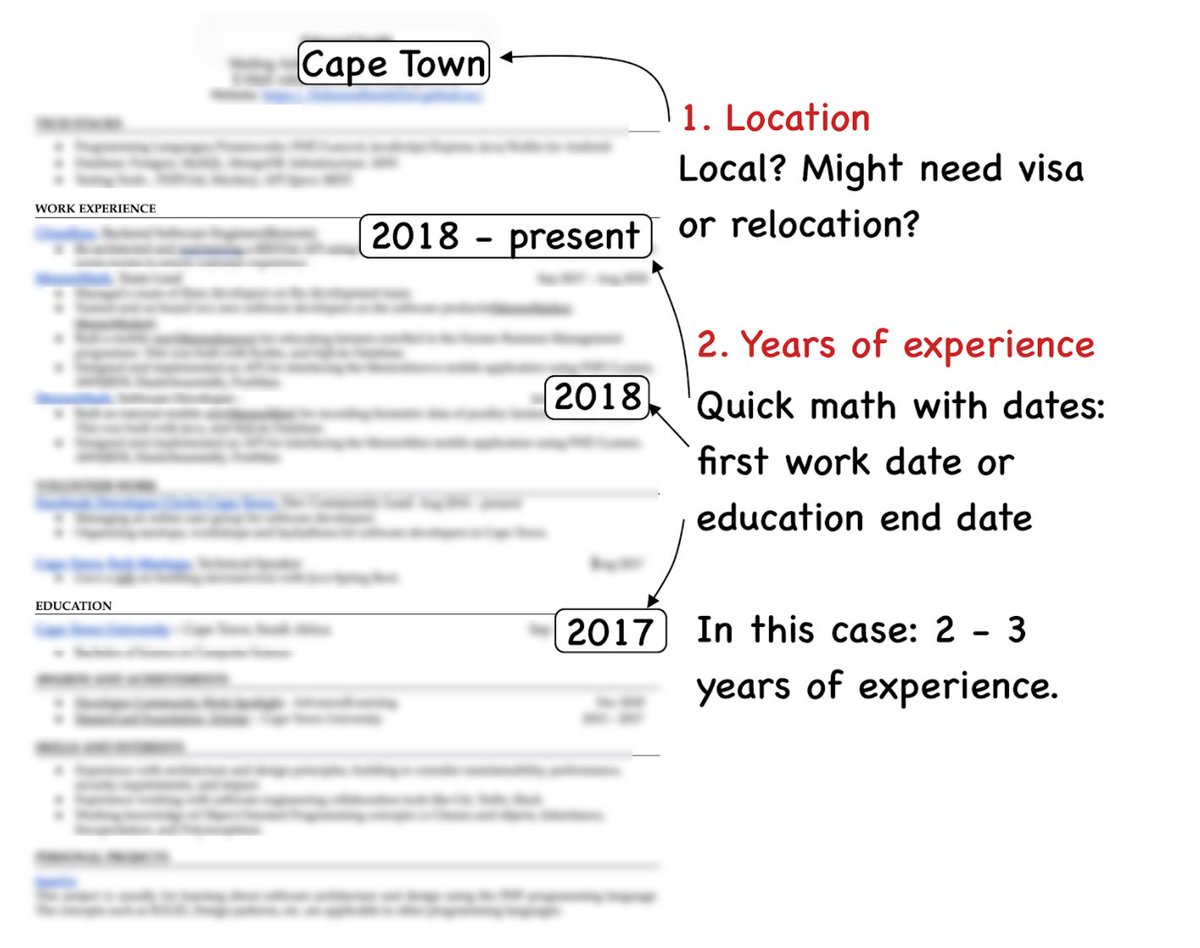
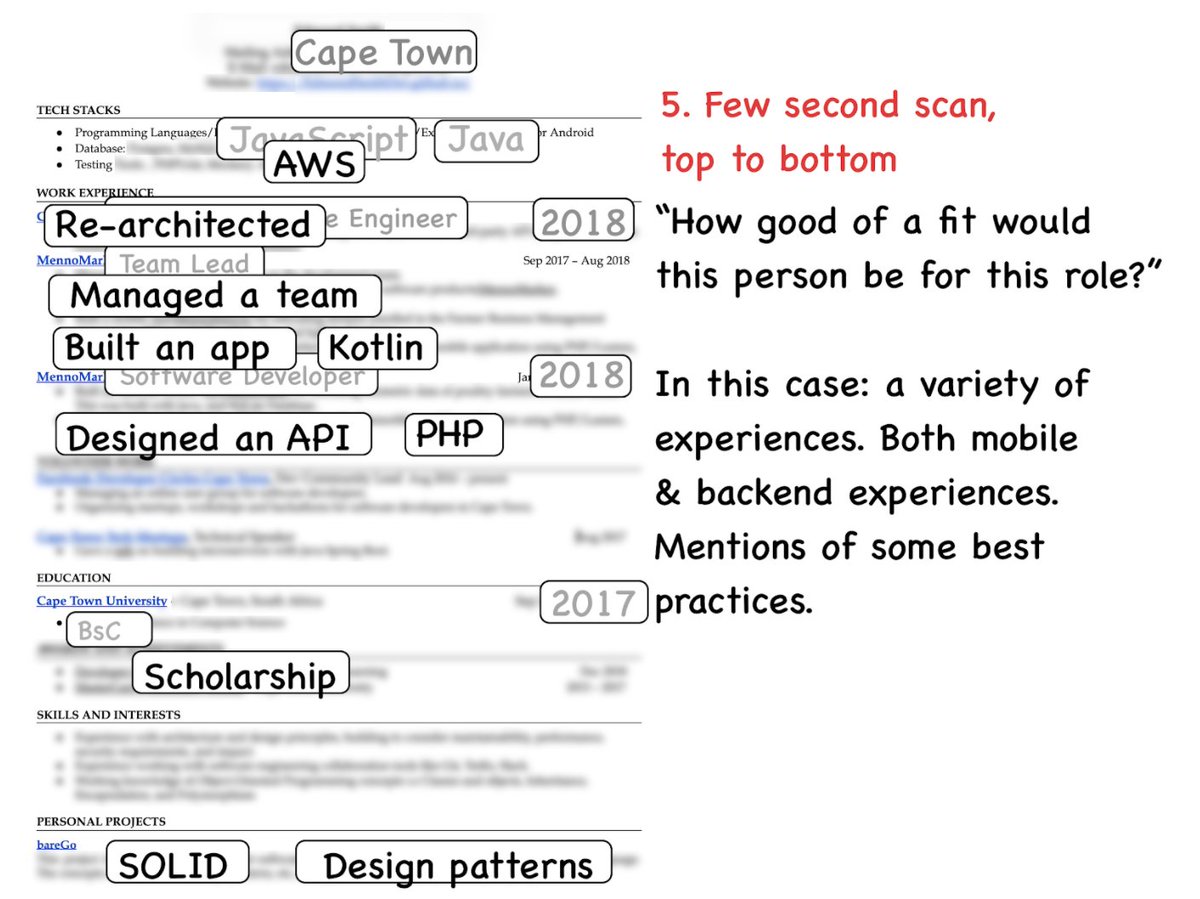
“Why does {company/app} have more than X engineers?” where X typically greater than 20/50/100.
Here’s how and why this makes sense for *the company* from a business-point of view. A thread.
Here’s how and why this makes sense for *the company* from a business-point of view. A thread.
1. What you see as “one app” is indeed, a lot of small parts that all contribute to the company making money.
Take the Twitter app. Almost all functionality (timeline, lists, profile, moments etc) are here to drive engagement. Then there’s ads and ad tools (I’m simplifying ofc)
Take the Twitter app. Almost all functionality (timeline, lists, profile, moments etc) are here to drive engagement. Then there’s ads and ad tools (I’m simplifying ofc)
2. A company never asks “how many engineers do we need overall?” They look at business cases.
“If we hire 4 engineers, we can build Lists. We expect to reduce churn by 4% annually which results in $15M/yr revenue. The cost of this team is A LOT less than this.”
“If we hire 4 engineers, we can build Lists. We expect to reduce churn by 4% annually which results in $15M/yr revenue. The cost of this team is A LOT less than this.”
3. Engineering gets funded based on business cases like this. All of it needs to make (some) financial sense. You might have loss-making units that move long-term/strategic metrics (growth, market share, coverage etc)
4. Eventually, all companies need to become not loss-making. All decisions take this into account. Engineering will ply a part in this, and large teams not contributing to the business according would get trimmed or re-allocated.
5. Companies/apps that seem to have overly large teams to *you* are either a lot more complex (Uber) or profitable (Twitter) than you think, or are investing strategically for long-term gain (Amazon, Gojek).
Took me years & making cases for team headcount to appreciate all this.
Took me years & making cases for team headcount to appreciate all this.
https://twitter.com/GergelyOrosz/status/1345288831029956610
6. An example that might seem like extreme:
Amazon Alexa: over 10K ppl voicebot.ai/2018/11/15/ama…
Almost everyone from the outside would mark this as “crazy”.
What is more likely: Jeff Bezos being crazy or you and me missing some key information on the complexity&potential here?
Amazon Alexa: over 10K ppl voicebot.ai/2018/11/15/ama…
Almost everyone from the outside would mark this as “crazy”.
What is more likely: Jeff Bezos being crazy or you and me missing some key information on the complexity&potential here?
• • •
Missing some Tweet in this thread? You can try to
force a refresh