Get into your slides!
I recently found an easy setup to get into my slides. Compared to the standard zoom setup, it's fun, engaging, and allows me to interact with the slide contents directly.
Check out the thread below and set it up for your own presentation!
I recently found an easy setup to get into my slides. Compared to the standard zoom setup, it's fun, engaging, and allows me to interact with the slide contents directly.
Check out the thread below and set it up for your own presentation!

I mainly follow the excellent video tutorial by @cem_yuksel
but with a poor man's variant (i.e., without a white background or green screen).
Make sure to check out the videos for the best quality!
but with a poor man's variant (i.e., without a white background or green screen).
Make sure to check out the videos for the best quality!
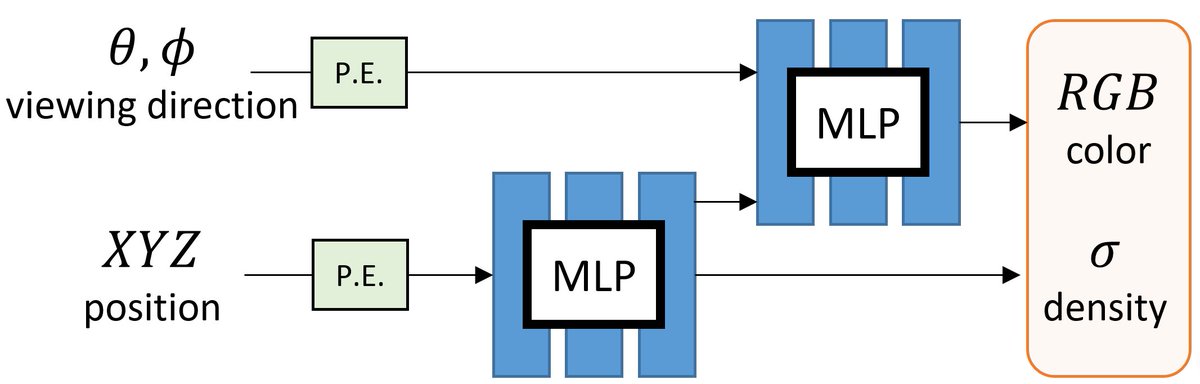
Step 1: Download Open Broadcaster Software (OBS) studio. obsproject.com
Why: We will use OBS to composite the slides and your camera video feed together and create a "virtual camera".
You can then use the virtual camera for your video conferencing presentation.
Why: We will use OBS to composite the slides and your camera video feed together and create a "virtual camera".
You can then use the virtual camera for your video conferencing presentation.

Step 2: Use Skype to create a FAKE digital green screen.
Specifically, choose a green image as your background effect. Now, leave this window there. We will use this camera preview on the screen as our video source in OBS (so that it won't reveal any background clutter).
Specifically, choose a green image as your background effect. Now, leave this window there. We will use this camera preview on the screen as our video source in OBS (so that it won't reveal any background clutter).

Step 3: Use OBS to create the layered composition.
- Top: Your slides
- Middle: Window capture the skype (with crop and color key filters)
- Bottom: Your slides
The layering ensures that your face/hands appear BEHIND the slide contents.
- Top: Your slides
- Middle: Window capture the skype (with crop and color key filters)
- Bottom: Your slides
The layering ensures that your face/hands appear BEHIND the slide contents.

Step 4: Set up the Virtual Camera.
In OBS, you will see the control panel on the bottom right. Just start the virtual camera.
Then, in the zoom video setting, you can select this "OBS Virtual Camera" as your video source.
In OBS, you will see the control panel on the bottom right. Just start the virtual camera.
Then, in the zoom video setting, you can select this "OBS Virtual Camera" as your video source.


Voilà! Now you can move into your slides, stream/record your presentation, and engage your students/audience better. No green screen or white background needed.
Try it out and let me know how it goes! Have fun!
Try it out and let me know how it goes! Have fun!
Yet another solution is through the advanced zoom sharing feature. This approach, however, would
- limit yourself in the bottom right corner (cannot point to your content)
- occlude the slide contents.
- limit yourself in the bottom right corner (cannot point to your content)
- occlude the slide contents.

• • •
Missing some Tweet in this thread? You can try to
force a refresh