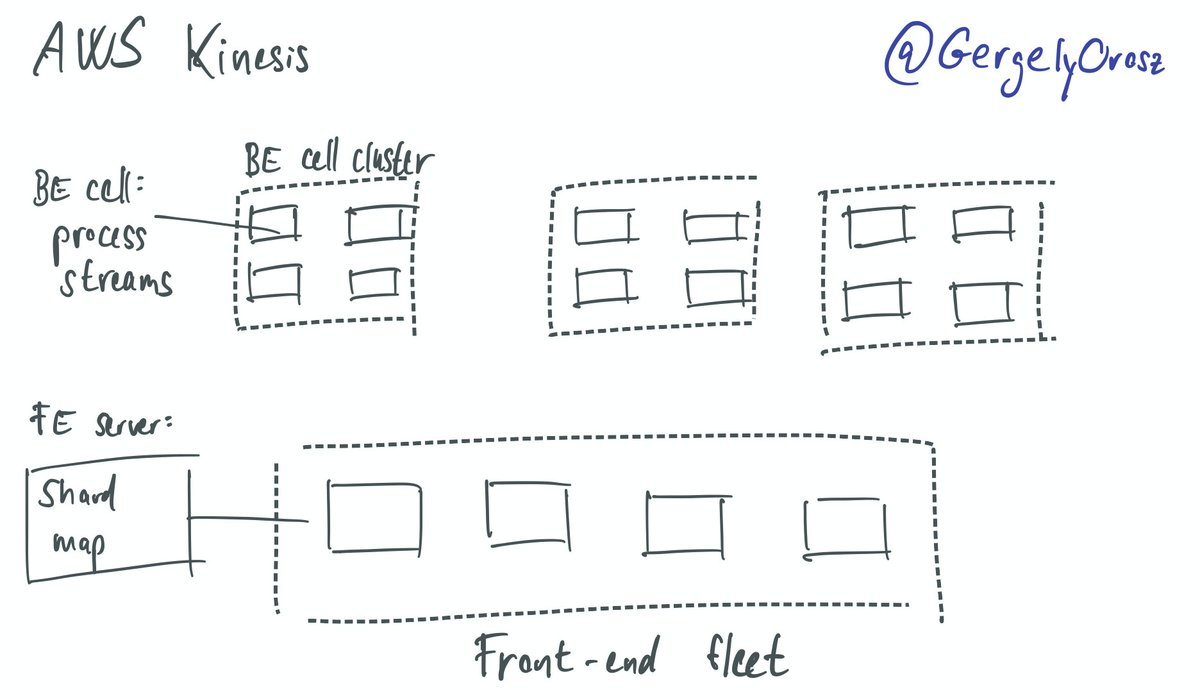
How do you bring up the topic of promotions with your manager?
My 7 pieces of advice (thread)
1. Understand how proms work at your company.
2. Talk with your manager: get them on your side. If you don't bring it up: don't expect it to happen.
My 7 pieces of advice (thread)
1. Understand how proms work at your company.
2. Talk with your manager: get them on your side. If you don't bring it up: don't expect it to happen.

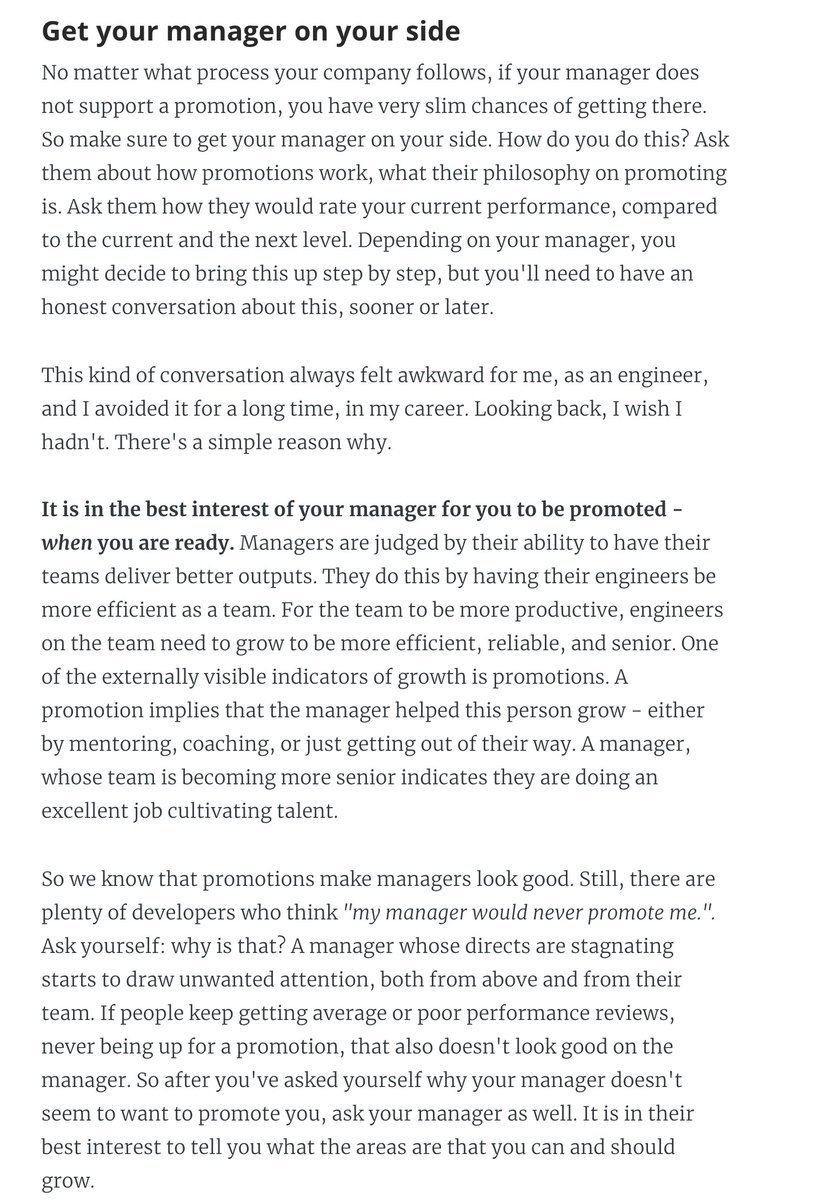
2. (Cont'd) It's in all managers' interest to have people promoted who are already performing at the next level. Makes the manager look good! You're on the same team.
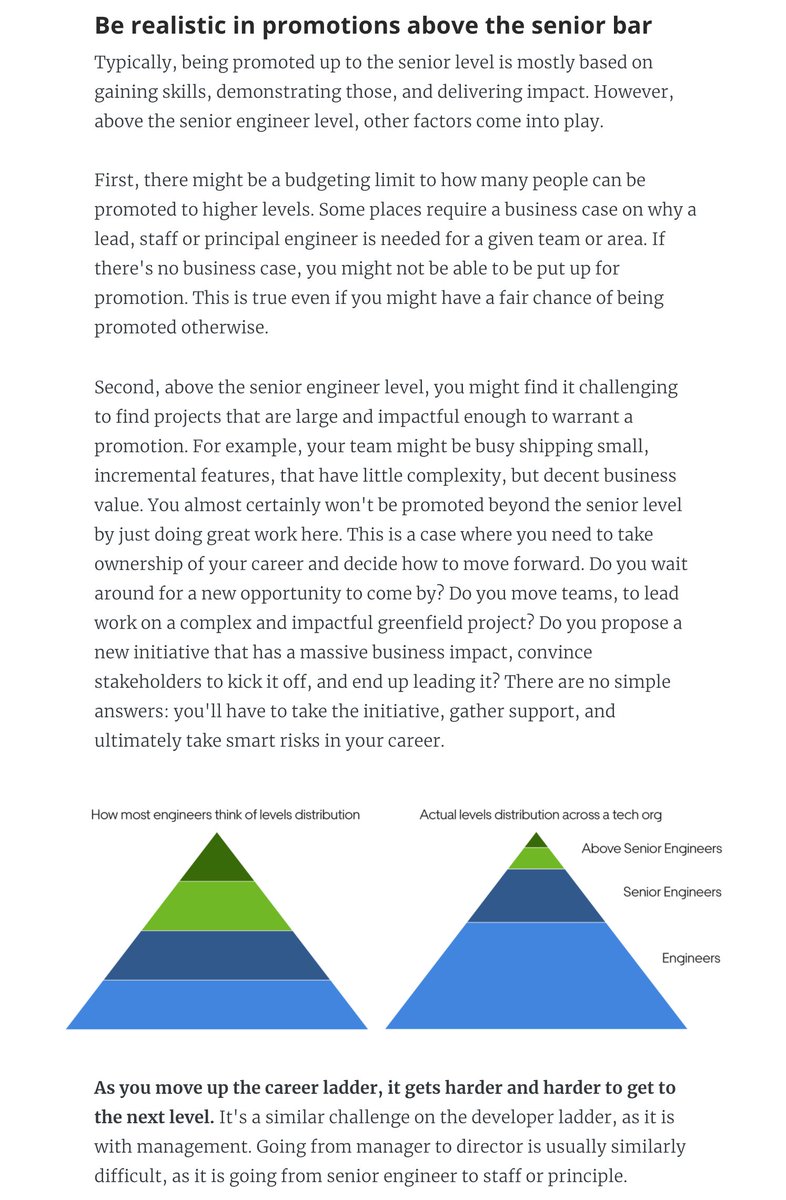
3. Be realistic about what it takes to be promoted above the senior levels. These are usually far more difficult.
3. Be realistic about what it takes to be promoted above the senior levels. These are usually far more difficult.
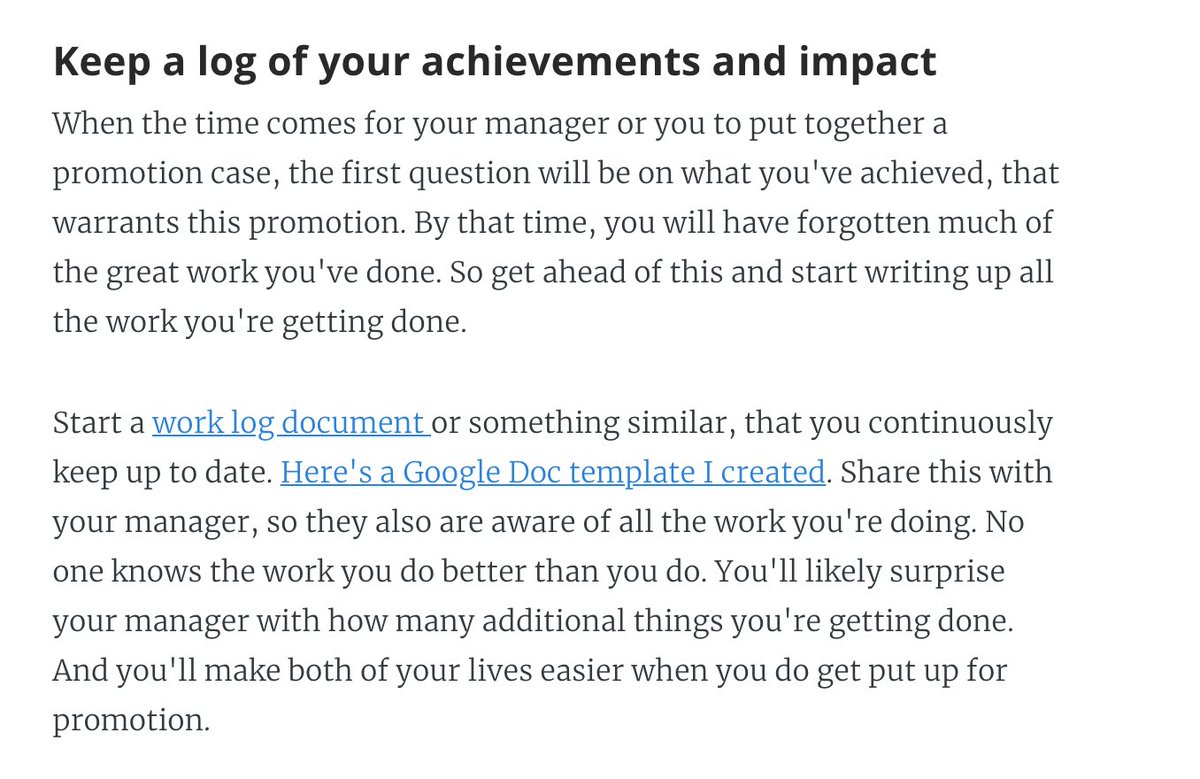
4. Set goals to "close the gap" that you have compared to the next level. Act like you would like if you had the title. Keep a work log.
5. Find a mentor within the company. Ask for regular feedback.
5. Find a mentor within the company. Ask for regular feedback.

6. Don't "blindly chase" the promotion, alienating others. Stay grounded, but put in the work.
7. Don't have promotion be your only goal. Aim for professional growth, over chasing titles.
I wrote all this down in an article, with resources & templates: blog.pragmaticengineer.com/software-engin…
7. Don't have promotion be your only goal. Aim for professional growth, over chasing titles.
I wrote all this down in an article, with resources & templates: blog.pragmaticengineer.com/software-engin…

• • •
Missing some Tweet in this thread? You can try to
force a refresh