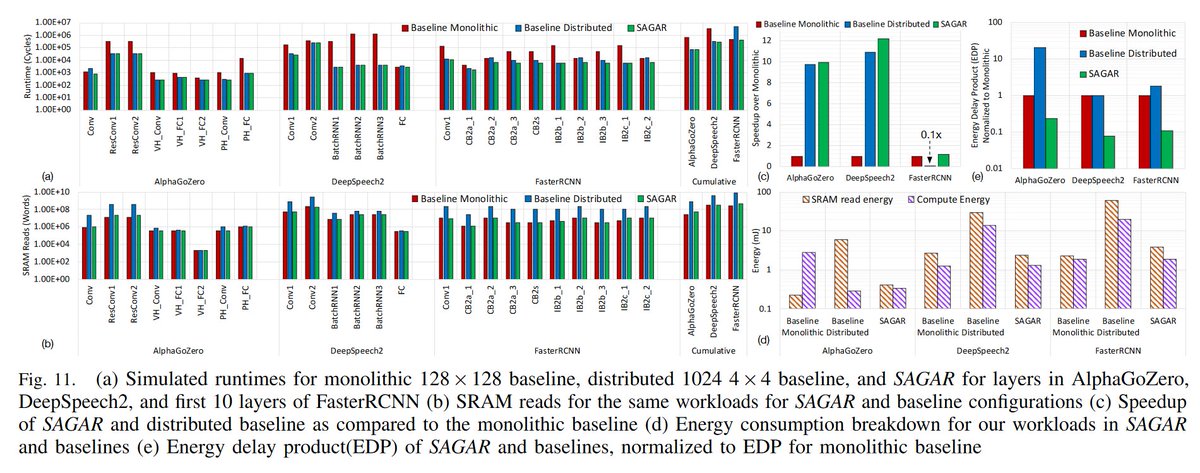
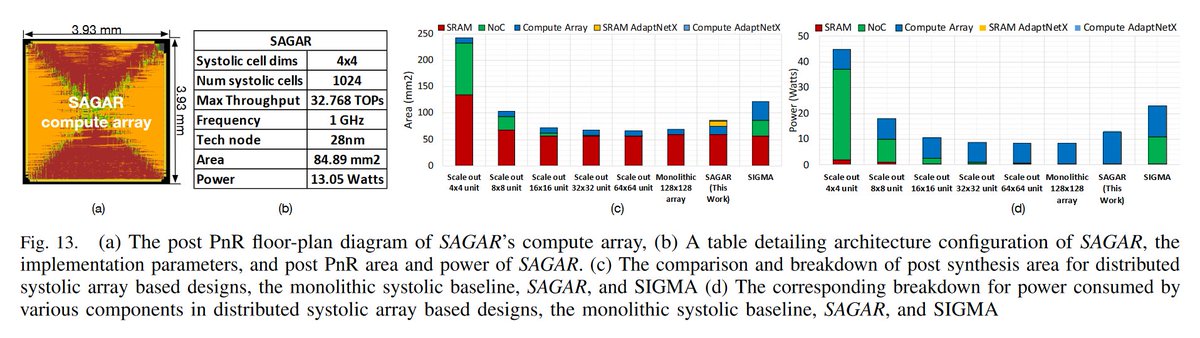
In this paper is presented PyTorch-Direct, a GPU-centric data access paradigm with a novel circular shift indexing optimization for GNN training to reduce training time, CPU utilization, and power consumption. #PyTorch #DeepLearning
arxiv.org/pdf/2101.07956…
arxiv.org/pdf/2101.07956…




PyTorch-Direct presents a new class of tensor called “unified tensor.” While a unified tensor resides in host memory, its elements can be accessed directly by the GPUs, as if they reside in GPU memory.
To support seamless transition of applications from the original PyTorch to PyTorch-Direct, it's presented a programming interface for using unified tensors, giving consistency with the existing PyTorch GPU tensor declaration mechanism.
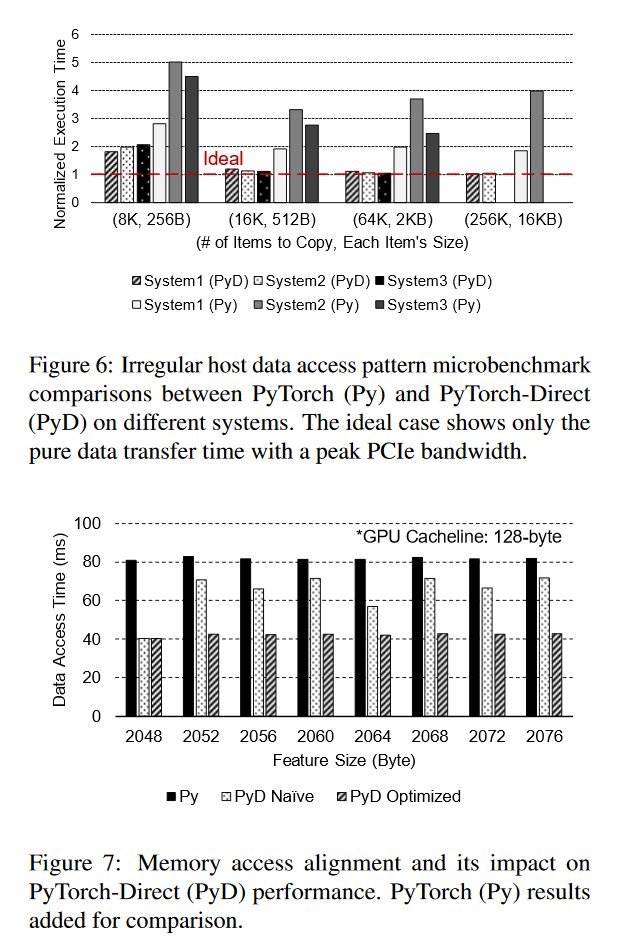
"With PyTorch-Direct, the time spent for accessing irregular data structures in host memory is reduced on average by 47.1% compared to the baseline PyTorch approach."
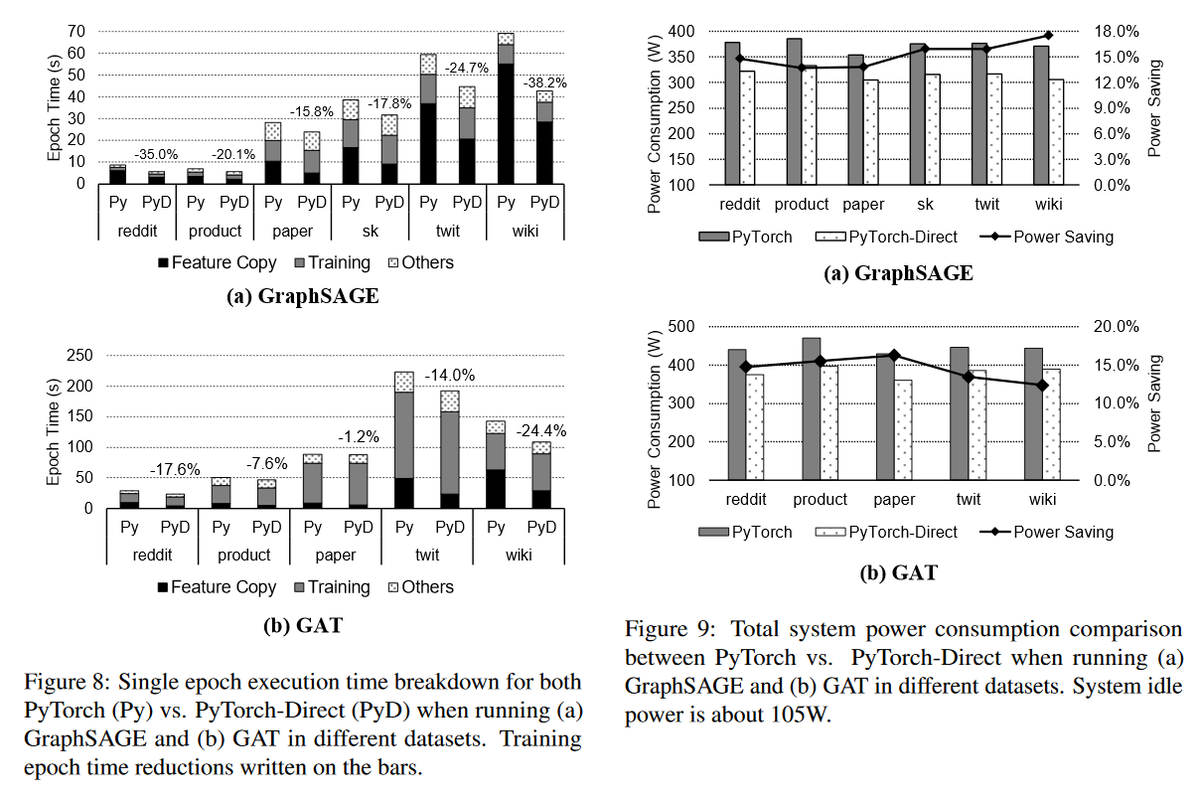
PyTorch-Direct also can speedup end-to-end GNN training by up to 1.62x depending on GNN architecture and input graph. Furthermore, by reducing the CPU workload, PyTorch-Direct provides 12.4% to 17.5% of reduced system power consumption during GNN training.
• • •
Missing some Tweet in this thread? You can try to
force a refresh