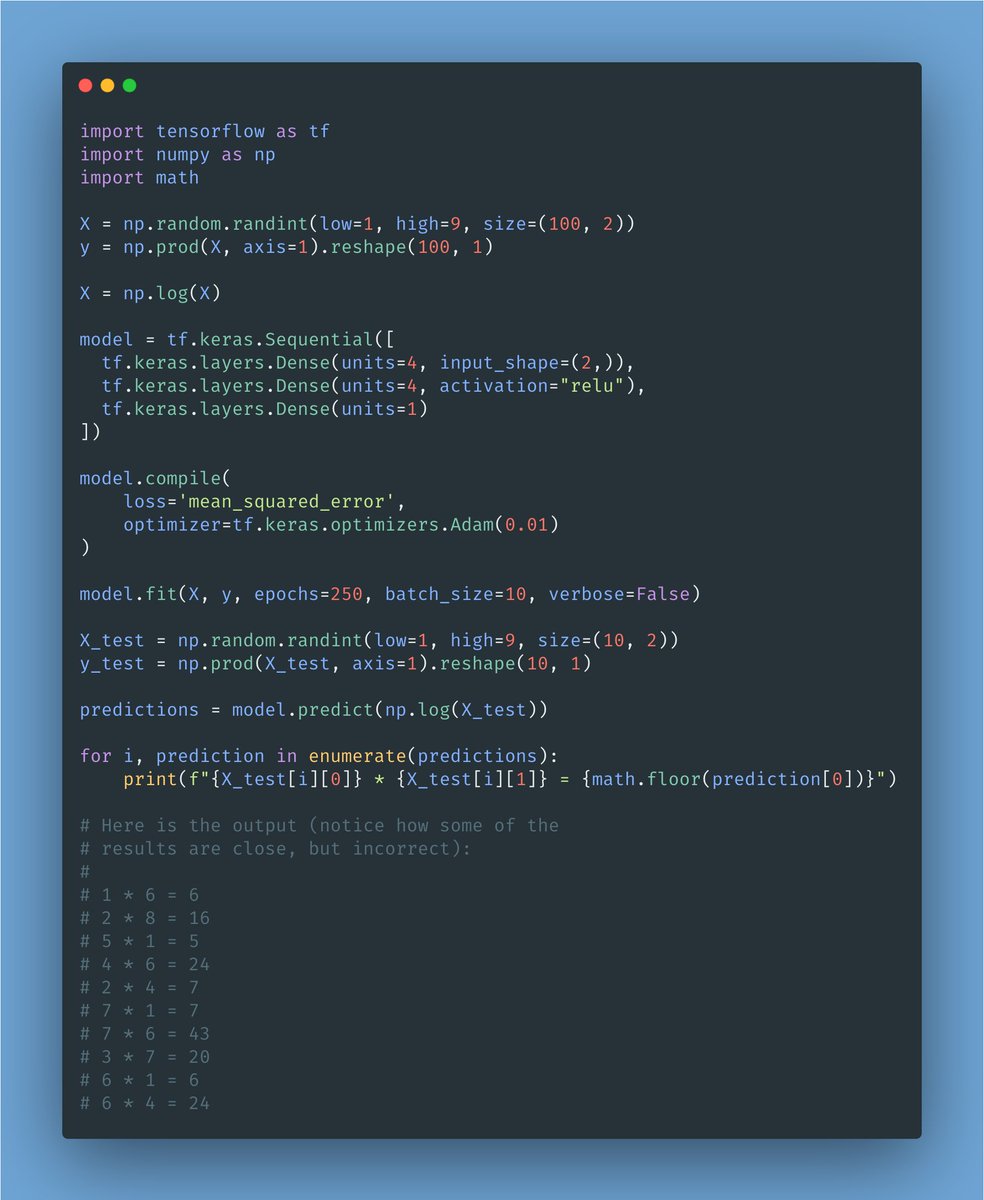
I built a model to predict whether you'll be involved in a crash next time you get in a car.
And it's 99% accurate!
Allow me to show you...👇
And it's 99% accurate!
Allow me to show you...👇

Here is the model:
👇
👇

The National Safety Council reports that the odds of being in a car crash in the United States are 1 in 102.
That's a probability of 0.98% of being involved in a crash.
Therefore, my silly model is accurate 99% of the time!
See? I wasn't joking before.
👇
That's a probability of 0.98% of being involved in a crash.
Therefore, my silly model is accurate 99% of the time!
See? I wasn't joking before.
👇
By now, it is probably clear that using "accuracy" as the way to measure the predictive capability of a model is not always a good idea.
The model could be very accurate... and still, give you no useful information at all.
Like right now.
👇
The model could be very accurate... and still, give you no useful information at all.
Like right now.
👇
Determining whether you are crashing on a car is an "imbalanced classification problem."
There are two classes: you crash, or you don't. And one of these represents the overwhelming majority of data points.
Takeaway: Accuracy is not a great metric for this type of problem.
👇
There are two classes: you crash, or you don't. And one of these represents the overwhelming majority of data points.
Takeaway: Accuracy is not a great metric for this type of problem.
👇
Crashing a car is a little bit too morbid, so here are a few more problems that could be framed as imbalanced classification tasks as well:
▫️ Detecting fraudulent transactions
▫️ Classifying spam messages
▫️ Determining whether a patient has cancer
👇
▫️ Detecting fraudulent transactions
▫️ Classifying spam messages
▫️ Determining whether a patient has cancer
👇
We already saw that we can develop a "highly accurate" model if we classify every credit card transaction as not fraudulent.
An accurate model, but not a useful one.
How do we properly measure the model's effectiveness if accuracy doesn't work for us?
👇
An accurate model, but not a useful one.
How do we properly measure the model's effectiveness if accuracy doesn't work for us?
👇
We care about *positive* samples (those transactions that are indeed fraudulent,) and we want to maximize our model's ability to find them.
In statistics, this metric is called "recall."
[Recall — Ability of a classification model to identify all relevant samples]
👇
In statistics, this metric is called "recall."
[Recall — Ability of a classification model to identify all relevant samples]
👇
A more formal way to define Recall is through the attached formula.
▫️ True Positives (TP): Fraudulent transactions that our model detected.
▫️ False Negatives (FN): Fraudulent transactions that our model missed.
👇
▫️ True Positives (TP): Fraudulent transactions that our model detected.
▫️ False Negatives (FN): Fraudulent transactions that our model missed.
👇

Imagine that we try again to solve the problem with the attached (useless) function.
We are classifying every instance as negative, so we are going to end up with 0 recall:
▫️ recall = TP / (TP + FN) = 0 / (0 + FN) = 0
👇
We are classifying every instance as negative, so we are going to end up with 0 recall:
▫️ recall = TP / (TP + FN) = 0 / (0 + FN) = 0
👇

That's something!
Now we know that our model is completely useless by using "recall" as our metric.
Since it's 0, we can conclude that the model can't detect any fraudulent transactions.
Ok, we are done!
Or, are we?
👇
Now we know that our model is completely useless by using "recall" as our metric.
Since it's 0, we can conclude that the model can't detect any fraudulent transactions.
Ok, we are done!
Or, are we?
👇
How about if we change the model to the attached function?
Now we are returning that every transaction is fraudulent, so we are maximizing True Positives, and our False Negatives will be 0:
▫️ recall = TP / (TP + FN) = TP / TP = 1
Well, that seems good, doesn't it? 🙁
👇
Now we are returning that every transaction is fraudulent, so we are maximizing True Positives, and our False Negatives will be 0:
▫️ recall = TP / (TP + FN) = TP / TP = 1
Well, that seems good, doesn't it? 🙁
👇

A recall of 1 is indeed excellent, but again, it just tells part of the story.
Yes, our model now detects every fraudulent transaction, but it also misclassifies every normal transaction!
Our model is not too *precise*.
👇
Yes, our model now detects every fraudulent transaction, but it also misclassifies every normal transaction!
Our model is not too *precise*.
👇
As you probably guessed, "precision" is the other metric that goes hand in hand with "recall."
[Precision — Ability of a classification model to identify only relevant samples]
👇
[Precision — Ability of a classification model to identify only relevant samples]
👇
A more formal way to define Precision is through the attached formula.
▫️ True Positives (TP): Fraudulent transactions that our model detected.
▫️ False Positives (FP): Normal transactions that our model misclassified as fraudulent.
👇
▫️ True Positives (TP): Fraudulent transactions that our model detected.
▫️ False Positives (FP): Normal transactions that our model misclassified as fraudulent.
👇

Let's compute the precision of our latest model (the one that classifies every transaction as fraudulent):
▫️ TP = just a few transactions, so a small number
▫️ FP = (1 - a small number) = large number
▫️ precision = TP / (TP + FP) = small / large ≈ 0
👇
▫️ TP = just a few transactions, so a small number
▫️ FP = (1 - a small number) = large number
▫️ precision = TP / (TP + FP) = small / large ≈ 0
👇
The precision calculation wasn't that clean, but hopefully, it is clear that the result will be very close to 0.
So we went from one extreme to the other!
Can you see the relationship?
As we increase the precision of our model, we decrease the recall and vice-versa.
👇
So we went from one extreme to the other!
Can you see the relationship?
As we increase the precision of our model, we decrease the recall and vice-versa.
👇
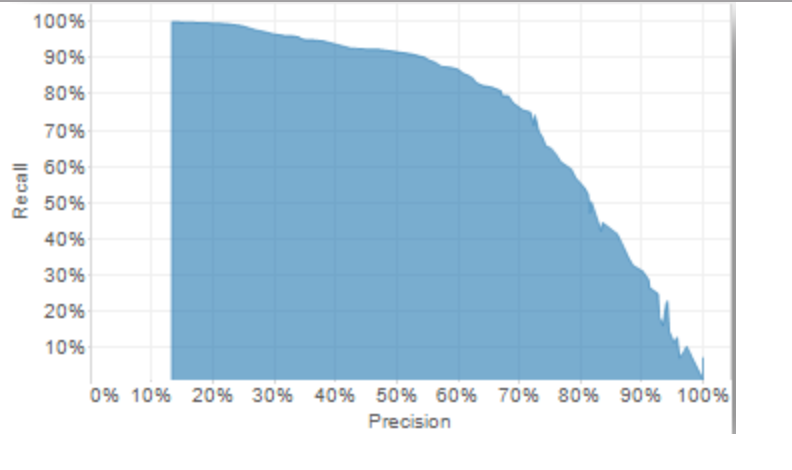
Alright, so now we know a few things about imbalanced classification problems:
▫️ Accuracy is not that useful.
▫️ We want a high recall.
▫️ We want high precision.
▫️ There's a tradeoff between precision and recall.
There's one more thing that I wanted to mention.
👇
▫️ Accuracy is not that useful.
▫️ We want a high recall.
▫️ We want high precision.
▫️ There's a tradeoff between precision and recall.
There's one more thing that I wanted to mention.
👇
There may be cases where we want to find a good balance between precision and recall.
For this, we can use a metric called "F1 Score," defined with the attached formula.
[F1 Score — Harmonic mean of precision and recall]
👇
For this, we can use a metric called "F1 Score," defined with the attached formula.
[F1 Score — Harmonic mean of precision and recall]
👇
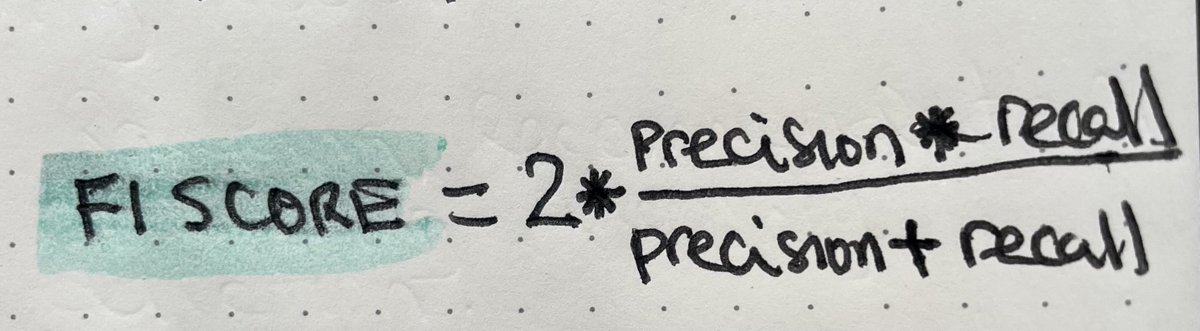
The F1 Score gives equal weight to both precision and recall and punishes extreme values.
This means that either one of the dummy functions we discussed before will show a very low F1 Score!
My models suck, and they won't fool the F1 Score.
👇
This means that either one of the dummy functions we discussed before will show a very low F1 Score!
My models suck, and they won't fool the F1 Score.
👇
So that's it for this story.
If you want to keep reading about metrics, here is an excellent, more comprehensive thread about different metrics used in machine learning (and the inspiration for this thread):
If you want to keep reading about metrics, here is an excellent, more comprehensive thread about different metrics used in machine learning (and the inspiration for this thread):
https://twitter.com/AlejandroPiad/status/1356716242606972931?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh