10 years of replication and reform in psychology. What has been done and learned?
Our latest paper prepared for the Annual Review summarizes the advances in conducting and understanding replication and the reform movement that has spawned around it.
psyarxiv.com/ksfvq/
1/
Our latest paper prepared for the Annual Review summarizes the advances in conducting and understanding replication and the reform movement that has spawned around it.
psyarxiv.com/ksfvq/
1/

Co-authors: @Tom_Hardwicke @hmoshontz @AllardThuriot @katiecorker Anna Dreber @fidlerfm @JoeHilgard @melissaekline @MicheleNuijten @dingding_peng Felipe Romero @annemscheel @ldscherer @nicebread303 @siminevazire 2/
We open w/ anecdote of the 2014 special issue of Social Psychology. The event encapsulated themes that played out over the decade. The issue brought attention to replications, Registered Reports, & spawned “repligate”
econtent.hogrefe.com/toc/zsp/45/3
Figure from royalsocietypublishing.org/doi/full/10.10…
econtent.hogrefe.com/toc/zsp/45/3
Figure from royalsocietypublishing.org/doi/full/10.10…

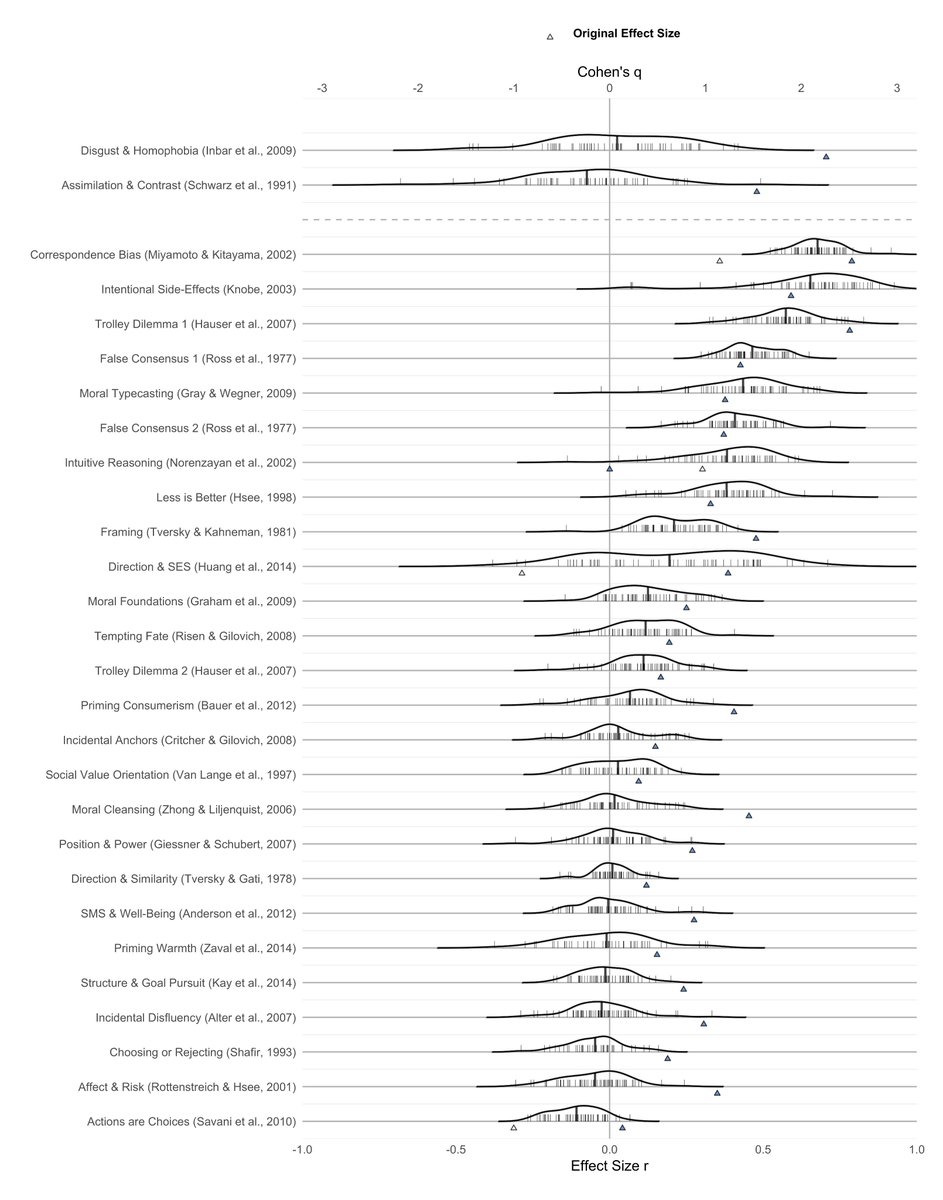
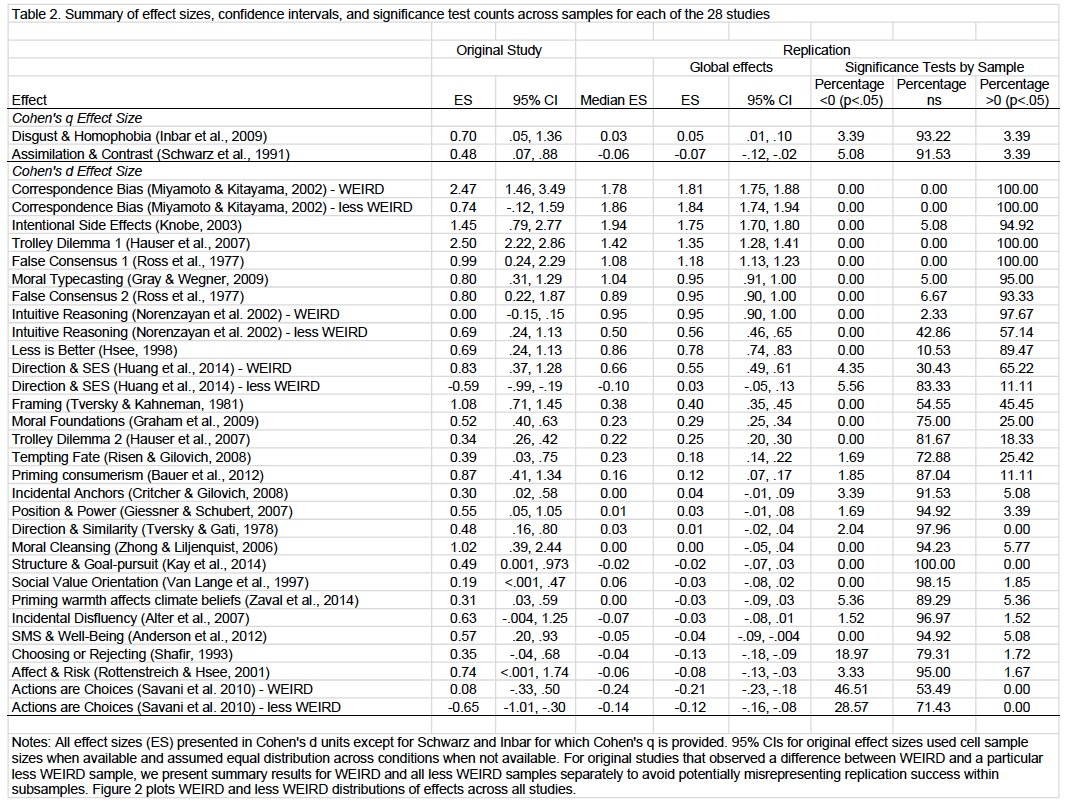
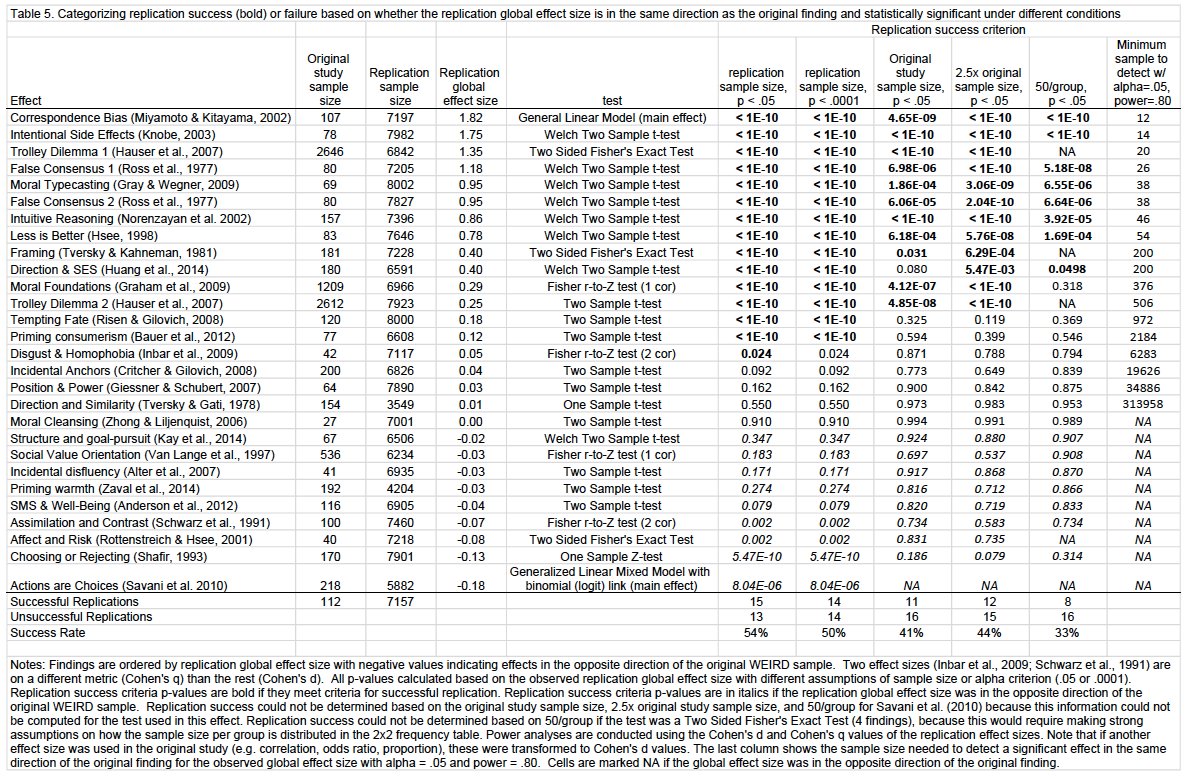
We consolidate evidence replication efforts. Across 307 replications, 64% reported statistically significant effect sizes in the same direction with effect sizes 68% as large as the originals. The median replication was 2.8x the sample size of the original, the mean was 15.1x.

Values below zero line are replications<original studies. Open circles are non-significant replications. x-axis is effect size of original.
1st 3 panels are systematic replications; 4th panel is 77 multisite replications; 5th panel is a prospective “best practice” replication.
1st 3 panels are systematic replications; 4th panel is 77 multisite replications; 5th panel is a prospective “best practice” replication.

We examine whether there is evidence for self-correcting after failures to replicate. So far, not much, when considering how original studies are cited in the few years following a prominent failure to replicate. More attention needed to this question, see osf.io/preprints/meta…

We review the role of theory, features of original studies, and features of replication studies in determining what replicates and what does not. Weak, non-specific theories don’t help. Neither do poor methods and small samples in original studies.
Neither would incompetence and lack of fidelity in replication studies. However, the existing evidence about qualities of the replication studies does not support these as explaining why there have been high failures to replicate in systematic and multisite replications.
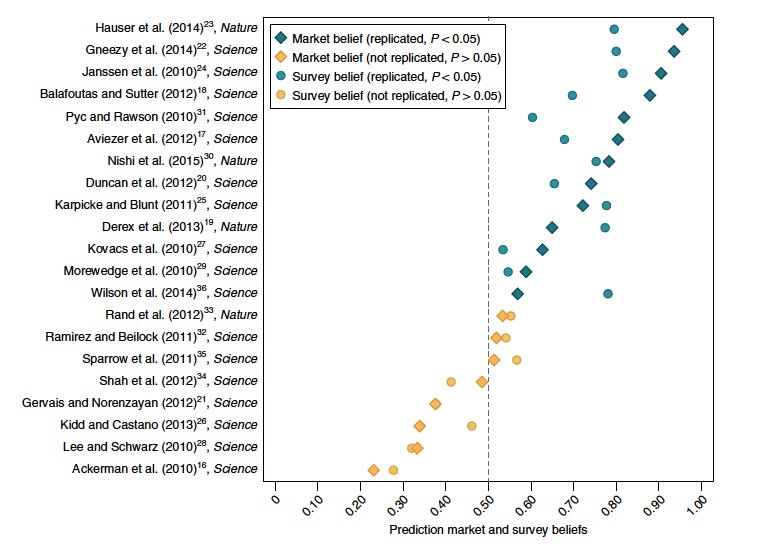
We review evidence that replication outcomes can be predicted in advance by surveys, prediction markets, structured elicitations, and machine learning. This evidence is the basis of developing tools to assess credibility automatically to help guide attention and decision-making.

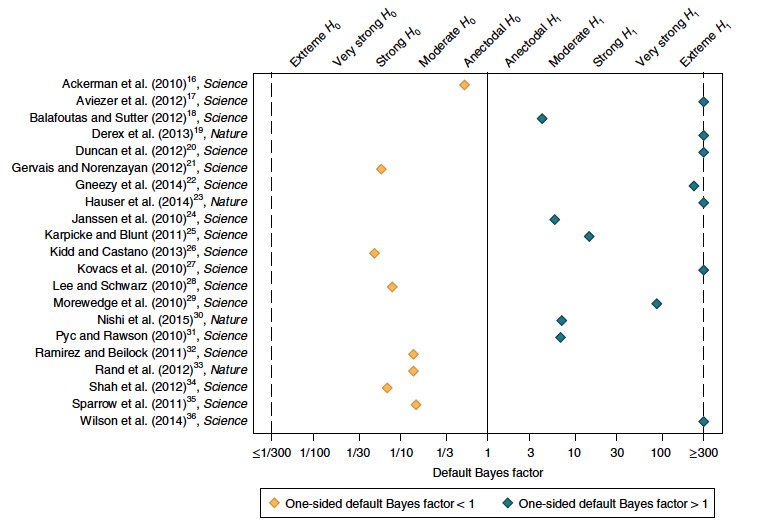
We review evidence about what could improve replicability and discuss what is optimal: "Low replicability is partly a symptom of tolerance for risky predictions and partly a symptom of poor research practices. Persistent low replicability is a symptom of poor research practices.”
We also discuss evidence such as Protzko et al (2020) that high replicability is achievable. Figure from psyarxiv.com/n2a9x/

We review the cultural, structural, social, and individual impediments to improving replicability: reward systems demanding novelty and discouraging replication, social challenges navigating hostility and reputational stakes, & confirmation, hindsight, & outcome reasoning biases.
We summarize the reform movement and its progress including the decentralized strategy for culture change. For example, this Figure shows adoption of transparency policies (TOP) by a random sample and a selection of high-impact psychology journals.

This Figure illustrates the integration of the many services, communities, and stakeholders that are individually and collectively contributing to scaling up behavior and culture change toward more transparency and rigor.

We close by highlighting the metascience community in psychology that has turned theory & methodology to examine itself. With all the progress made, its greatest contribution might be having identified even more of what we do not yet understand. psyarxiv.com/ksfvq/
• • •
Missing some Tweet in this thread? You can try to
force a refresh