
Bagaimana cara membuat pricing model?
Thread kecil, pembahasan dari kasus sebelumnya.
Thread kecil, pembahasan dari kasus sebelumnya.
Mari kita mulai pembahasan dengan restate kasus kita:
Toko Selular Nusantara menjual telepon selular bekas di e-commerce lokal. Toko ini merasa penentuan harganya terkadang terlalu murah, terkadang terlalu mahal. Toko tersebut memiliki data: 1) jenis hape, 2) harga, 3) terjual atau tidak, 4) kondisi hape.
Q1: Apa yang harus dimodelkan?
Pembahasan gue masih menekankan bahwa kebanyakan data scientist mengabaikan modeling, hanya fokus ke curve fitting.
Pertama tentukan dulu objective dari model nya apa. Dalam kasus ini kita mau memaksimalkan sebuah telepon selular terjual dengan harga paling optimal.
Isi model:
1. Modeling probability terjual
2. Modeling harga optimal.
Isi model:
1. Modeling probability terjual
2. Modeling harga optimal.
Tentukan decision space dari model:
Price = [0, +inf]
Jadi price harus positif. Berapa price nya? Ini yang harus dimodelkan.
Price = [0, +inf]
Jadi price harus positif. Berapa price nya? Ini yang harus dimodelkan.
Q2: Apa loss function nya?
Loss function ini selalu digunakan untuk optimisasi, goal nya adalah meminimalisir loss. Yang kita mau maximize adalah Sales.
arg max Sales
Sales = Quantity x Price.
Loss function ini selalu digunakan untuk optimisasi, goal nya adalah meminimalisir loss. Yang kita mau maximize adalah Sales.
arg max Sales
Sales = Quantity x Price.
Quantity ini karena menjualnya adalah per barang, maka kta ubah menjadi Probability terjual given price, bisa dimodelkan dengan Logistic Regression, gue lambangkan dengan f(Price).
Price terbaiki diasumsikan sebagai Price*, kita jamet-jamet biasanya nyebutnya dengan "price star".
L(f(Price), Price)= f(Price) × Price.
Pertanyaannya berapa harga yang memaksimalkan sales?
L(f(Price), Price)= f(Price) × Price.
Pertanyaannya berapa harga yang memaksimalkan sales?
Q3: Gimana cara fitting nya?
Nah ini baru masuk fitting, apa-apa gak langsung dimasukin ke scikit-learn atau xgboost ya. Kalau situ masih ngelakuin kayak gitu, ya agak disayangkan aja situ jadi library operator aja. Padahal bisa lebih
Nah ini baru masuk fitting, apa-apa gak langsung dimasukin ke scikit-learn atau xgboost ya. Kalau situ masih ngelakuin kayak gitu, ya agak disayangkan aja situ jadi library operator aja. Padahal bisa lebih
Ini adalah data yang kita punya 

Yang diprediksi adalah......
Terjual/ Tidak Terjual
Inputnya adalah....
Kondisi hape, harga dan tahun.
Terjual/ Tidak Terjual
Inputnya adalah....
Kondisi hape, harga dan tahun.
Ini modelnya

Kemarin ada yang bilang mau pakai Deep Learning/Xgboost, gue ragu.... soalnya kita mau optimisasi Price star. Jadi kalau non linear bakalan banyak local optima.
Silakan kasih argumen kalau ternyata bisa. Ini cuma modeling, gue open buat diskusi.
Silakan kasih argumen kalau ternyata bisa. Ini cuma modeling, gue open buat diskusi.
Q4: Apa batasannya?
Pasti jamet-jamet dari ekonomi langsung mau komentar casciscus. Benar model ini ada batasannya dan sejujurnya hampir pasti bias.
Pasti jamet-jamet dari ekonomi langsung mau komentar casciscus. Benar model ini ada batasannya dan sejujurnya hampir pasti bias.
Setiap input variable punya korelasi, misal:
- semakin tua sebuah telepon selular maka semakin mungkin untuk baret.
- semakin tua sebuah telepon selular maka semakin murah harganya.
- semakin tua sebuah telepon selular maka semakin mungkin untuk baret.
- semakin tua sebuah telepon selular maka semakin murah harganya.
Akibatnya adalah beta dari estimasi harga akan bias! sehingga mengakibatkan estimasi efek perubahan harga terhadap probabilty terjual menjadi salah.
Misal harusnya beta 2.0, jadinya 1.5 atau 2.5. Paham gak?
Kalau gak paham mending ikut kelas @pacmannai aja...
Misal harusnya beta 2.0, jadinya 1.5 atau 2.5. Paham gak?
Kalau gak paham mending ikut kelas @pacmannai aja...
Q5: Apa metode yang digunakan?
Bayesian Logistic Regression..... biar ketahuan nanti kalau kita masukin simulasi uncertainty harga dan uncertainty lossnya gimana.
Bayesian Logistic Regression..... biar ketahuan nanti kalau kita masukin simulasi uncertainty harga dan uncertainty lossnya gimana.
Q6: Bagaimana cara optimisasinya?
capek nulis...
capek nulis...

Anda tinggal melakukan simulasi harga dari barang tersebut, karena harga adalah hal yang bisa kontrol/decision yang bisa kita ambil.

Recall our objective function:
Harga ketinggian bikin hape gak kejual, harga kemurahan bikin revenue kerendahan. Jadi simulasikan cari price terbaik.
Harga ketinggian bikin hape gak kejual, harga kemurahan bikin revenue kerendahan. Jadi simulasikan cari price terbaik.
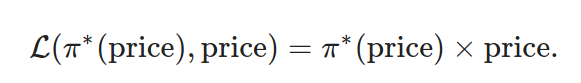
Selesai, pinter kan mimin?
Enggak kaleng-kalengan kayak tempat bootcamp yang lain, di pacmann ai beneran belajar modeling.
Ada pertanyaan?
Enggak kaleng-kalengan kayak tempat bootcamp yang lain, di pacmann ai beneran belajar modeling.
Ada pertanyaan?
Materi ini diambil dari blog Bayesian Decision Theory, silakan dibaca statsathome.com/2017/10/12/bay…
Kenapa gak pakai Deep Learning/XGboost?
Karena kalau pakai DL, karena dia non linear, maka decision nya juga non linear, sehingga bentuknya gak 1 global optimal, melainkan banyak local optimal.
The proof is left as an exercise to the readers.
Karena kalau pakai DL, karena dia non linear, maka decision nya juga non linear, sehingga bentuknya gak 1 global optimal, melainkan banyak local optimal.
The proof is left as an exercise to the readers.
https://twitter.com/pacmannai/status/1360965488801554432?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh







