
Day 14 #31DaysofML
🤔 How to pick the right #GoogleCloud #MachineLearning tool for your application?
Answer these questions
❓ What's your teams ML expertise?
❓ How much control/abstraction do you need?
❓ Would you like to handle the infrastructure components?
🧵 👇
🤔 How to pick the right #GoogleCloud #MachineLearning tool for your application?
Answer these questions
❓ What's your teams ML expertise?
❓ How much control/abstraction do you need?
❓ Would you like to handle the infrastructure components?
🧵 👇
@SRobTweets created this pyramid to explain the idea.
As you move up the pyramid, less ML expertise is required, and you also don’t need to worry as much about the infrastructure behind your model.
To lear more watch this video 👉
#31DaysofML 2/10
As you move up the pyramid, less ML expertise is required, and you also don’t need to worry as much about the infrastructure behind your model.
To lear more watch this video 👉
#31DaysofML 2/10
@SRobTweets If you’re using Open source ML frameworks (#TensorFlow) to build the models, you get the flexibility of moving your workloads across different development & deployment environments. But, you need to manage all the infrastructure yourself for training & serving
#31DaysofML 3/10
#31DaysofML 3/10
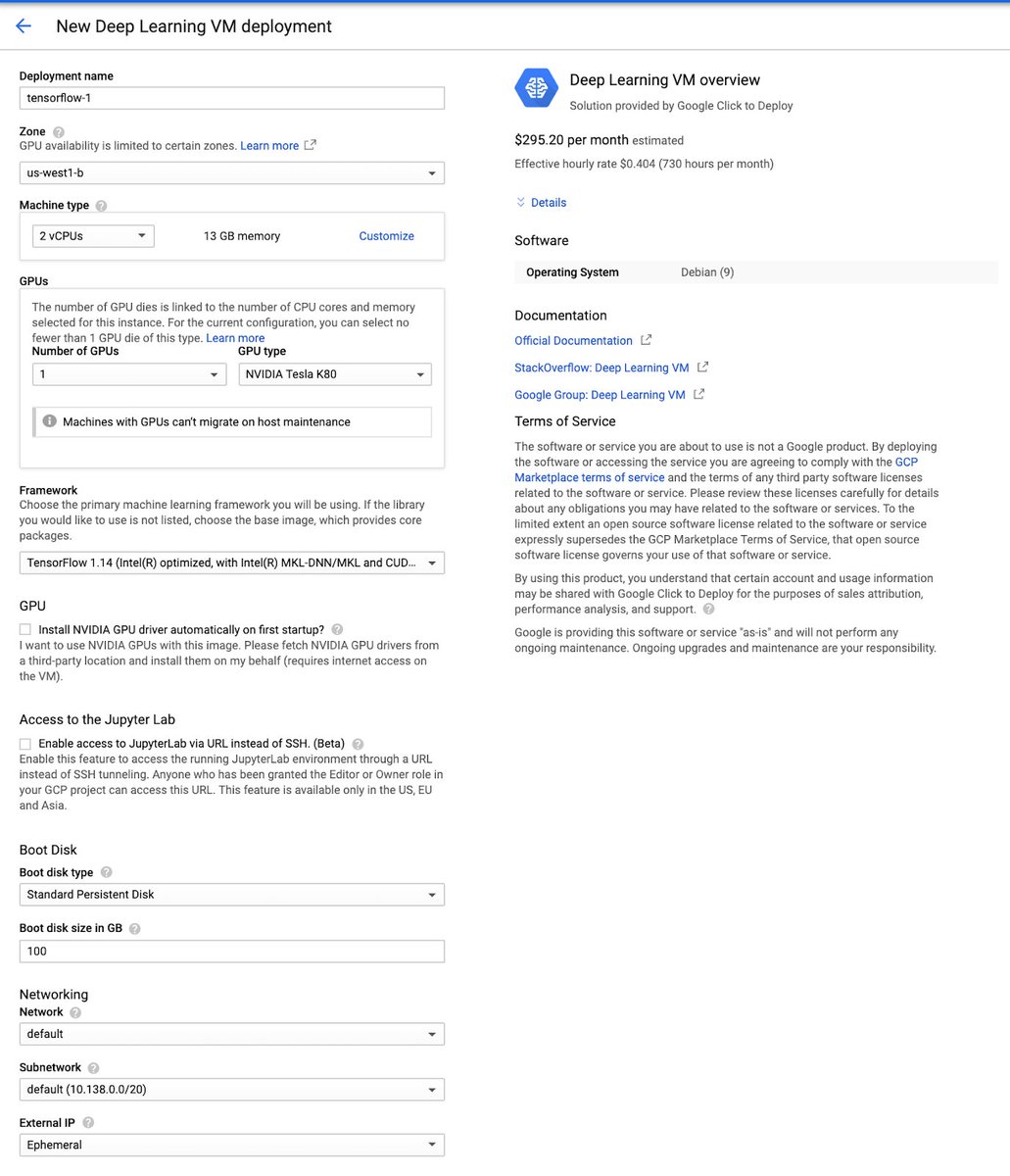
@SRobTweets Deep Learning VMs provide managed, click-to-deploy VMs for processing data & training the model
🔹 Popular ML frameworks pre-installed
🔹 Reduces the overhead of managing & allocating compute & storage required
🔹 But you figure out how you’ll serve those models
#31DaysofML 4/10
🔹 Popular ML frameworks pre-installed
🔹 Reduces the overhead of managing & allocating compute & storage required
🔹 But you figure out how you’ll serve those models
#31DaysofML 4/10

@SRobTweets Kubeflow - OS project for deploying ML workloads on #Kubernetes
🔹 Helps configure a multi-step ML pipeline including pre-processing data, training & serving the model
🔹 Run it on-premise or on any cloud
🔹 You’ll still need to configure where it’s managed
#31DaysofML 5/10
🔹 Helps configure a multi-step ML pipeline including pre-processing data, training & serving the model
🔹 Run it on-premise or on any cloud
🔹 You’ll still need to configure where it’s managed
#31DaysofML 5/10
@SRobTweets AI Platform - managed service for all custom model needs
🔹 Includes tools for training & serving models, hosted notebooks, a data labeling service & more
🔹 Eg: take notebook code running on-premise with Kubeflow, and run it on GCP with AI Platform Notebooks
#31DaysofML 6/10
🔹 Includes tools for training & serving models, hosted notebooks, a data labeling service & more
🔹 Eg: take notebook code running on-premise with Kubeflow, and run it on GCP with AI Platform Notebooks
#31DaysofML 6/10
@SRobTweets BQML: Brings the power of ML closer to where the data is analyzed & make it accessible to data analysts
🔹 You don’t have to write any of the underlying model code
🔹 Choose model type
🔹 Simple SQL queries to create & train the model & make predictions
#31DaysofML 7/10
🔹 You don’t have to write any of the underlying model code
🔹 Choose model type
🔹 Simple SQL queries to create & train the model & make predictions
#31DaysofML 7/10
@SRobTweets AutoML democratizes ML to build custom ML models regardless of ML expertise.
🔹 Use the UI to upload the data - images, video, text, or structured
🔹 Press "train" button
🔹 Model is available for prediction via an API
🔹 No need to deploy it yourself
#31DaysofML 8/10
🔹 Use the UI to upload the data - images, video, text, or structured
🔹 Press "train" button
🔹 Model is available for prediction via an API
🔹 No need to deploy it yourself
#31DaysofML 8/10
@SRobTweets ML APIs: Easiest and fastest way to get started with AI
🔹 Don’t need ML engineers or data scientists just some developers
🔹 Simple API request to pre-trained models for images, video, speech, text & translation
🔹 No need to supply any training data yourself
#31DaysofML 9/10
🔹 Don’t need ML engineers or data scientists just some developers
🔹 Simple API request to pre-trained models for images, video, speech, text & translation
🔹 No need to supply any training data yourself
#31DaysofML 9/10
@SRobTweets ML APIs → goo.gle/2r30flz
AutoML → goo.gle/38zZS2E
BQML → goo.gle/2PwbgVX
AI Platform → goo.gle/36JYPLW
Kubeflow → goo.gle/2PvJRDk
Deep Learning VMs → goo.gle/2rYttST
Tensorflow → goo.gle/35zholN
10/10
AutoML → goo.gle/38zZS2E
BQML → goo.gle/2PwbgVX
AI Platform → goo.gle/36JYPLW
Kubeflow → goo.gle/2PvJRDk
Deep Learning VMs → goo.gle/2rYttST
Tensorflow → goo.gle/35zholN
10/10
• • •
Missing some Tweet in this thread? You can try to
force a refresh


