
Muchas veces suelo poner los efectos de optimización SEO de un proyecto al cabo de unos meses, esto cambia hoy 😜
Estamos empezando a optimizar un proyecto de cero y os voy a contar en este hilo estilo "hiling" (blogging estilo hilo 😂) lo que vamos haciendo 😇
👇🏽 Hilo 👇🏽
Estamos empezando a optimizar un proyecto de cero y os voy a contar en este hilo estilo "hiling" (blogging estilo hilo 😂) lo que vamos haciendo 😇
👇🏽 Hilo 👇🏽
Al hacerlo en tiempo real, veréis tanto los efectos positivos (o negativos!) así como los blockers y cómo vamos iterando la optimización 📈📉
Se trata de un sitio web de clasificados generalista (toca todas las verticales menos RE) dentro de @Adevinta
Se trata de un sitio web de clasificados generalista (toca todas las verticales menos RE) dentro de @Adevinta
Es una web muy antigua (con m.site) y que está en modo mantenimiento, no se desarrollan apenas funcionalidades nuevas, pero ha surgido la oportunidad de dedicarle un par de días de desarrollo a la semana.
Vamos a intentar sacarle el máximo provecho 😜
Vamos a intentar sacarle el máximo provecho 😜
Las 4 áreas de trabajo diseñadas son las siguientes:
1) Mejoras de Crawling & Indexing 🤖
2) Trabajar en indexar un path de listados 📈
3) Hacer fixes para el Mobile First Index 📲
4) Mejoras sección de Motor 🚗
1) Mejoras de Crawling & Indexing 🤖
2) Trabajar en indexar un path de listados 📈
3) Hacer fixes para el Mobile First Index 📲
4) Mejoras sección de Motor 🚗
✨ Semana 1 ✨
Empezamos desarrollando la parte de Crawling & Indexing con unas mejoras en el robots.txt para petarnos todos los filtros inútiles, paginaciones, perfiles de usuario y otras tantas burradas que estaban consumiendo mucho rastreo y que no aportaban NADA 🧑🚒🔥
Empezamos desarrollando la parte de Crawling & Indexing con unas mejoras en el robots.txt para petarnos todos los filtros inútiles, paginaciones, perfiles de usuario y otras tantas burradas que estaban consumiendo mucho rastreo y que no aportaban NADA 🧑🚒🔥
Literalmente la web estaba tan mal optimizada que había muchísimos de los links internos que tenían UTMs...
De lo peorcito que he visto, los hemos quitado todos. Links a URLs finales. Esto también afectaba a Google Analytics ya que el UTM sobreescribe la sesión 🤢
De lo peorcito que he visto, los hemos quitado todos. Links a URLs finales. Esto también afectaba a Google Analytics ya que el UTM sobreescribe la sesión 🤢
Finalmente, aunque realmente no tiene que ver con Crawling & Indexing he podido colar la agregación del Schema de Breadcrumb y Producto para sacar algunos rich snippets 😇
Ya aparecen en algunas queries los rich snippets de Producto, mostrando precio e imagen en algunos casos. Por desgracia el Breadcrumb se ha subido con un bug y habrá que subir el fix.
Vamos a dejarlo reposar y a sacar datos de impacto la semana que viene 😁
Vamos a dejarlo reposar y a sacar datos de impacto la semana que viene 😁


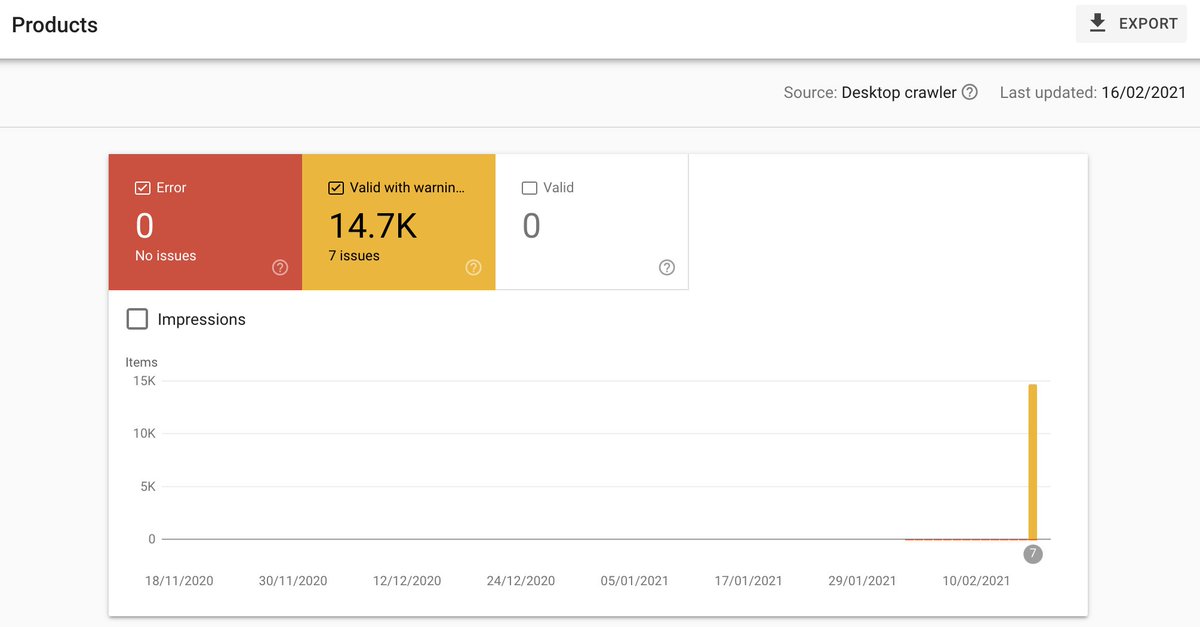
Vamos a dar un poco más de contexto sobre un par de temas: usar robots.txt vs. hacer una limpieza "de manual" 📚
La desindexación de manual suele ser poner un noindex/canonical/redirect... luego quitar links a esos enlaces, y finalmente bloquear por robots.txt si es necesario 🤔
La desindexación de manual suele ser poner un noindex/canonical/redirect... luego quitar links a esos enlaces, y finalmente bloquear por robots.txt si es necesario 🤔
Esto tendría un coste bastante alto en este proyecto a nivel de tiempo por su complejidad, y el beneficio es muy bajo.
El robots.txt es una gran arma en sitios web grandes, y en este caso la arma infalible con coste de implementación de 5 minutos 😍
El robots.txt es una gran arma en sitios web grandes, y en este caso la arma infalible con coste de implementación de 5 minutos 😍
Muchas de las URLs en cualquier caso ya estaban con noindex, o Google ni las indexaba por baja calidad.
Así que con los cambios de robots.txt máximo se nos va a colar un 5-10% de URLs que están indexadas #worthit
Así que con los cambios de robots.txt máximo se nos va a colar un 5-10% de URLs que están indexadas #worthit

El principal error que cometen muchos SEOs es tratar de ser demasiado perfeccionistas. Solucionar errores que no aportan ningún beneficio. Seguir "la checklist". Hacer un "audit".
seomba.substack.com/p/lets-never-t…
seomba.substack.com/p/lets-never-t…
Mientras vamos analizando el impacto de los cambios en robots.txt, ya estamos preparando el punto 2 de nuestro plan 🚀
Hemos creado una replica del buscador en otro path y vamos a tunearlo para conseguir los resultados esperados.
Hemos creado una replica del buscador en otro path y vamos a tunearlo para conseguir los resultados esperados.
¿Qué tendrá de distinto este path sobre el principal?
📖 Cerca de 90.000 landings que cubren todo tipo de búsquedas de los usuarios que ahora no cubrimos
🔗 Enlazado interno potente
🔤 Mejores titles, meta description y h1
🗑 Bloqueo filtros y paginaciones des del inicio
📖 Cerca de 90.000 landings que cubren todo tipo de búsquedas de los usuarios que ahora no cubrimos
🔗 Enlazado interno potente
🔤 Mejores titles, meta description y h1
🗑 Bloqueo filtros y paginaciones des del inicio
La semana que viene lo intentaremos poner en producción 🤞
Queremos darle mucha fuerza de enlazado a este path desde el inicio, así que crearemos links a tutiplén 🖇
- Home (top potencial)
- Categorías
- Dentro del propio path (semánticos)
- Detalles de anuncio
Queremos darle mucha fuerza de enlazado a este path desde el inicio, así que crearemos links a tutiplén 🖇
- Home (top potencial)
- Categorías
- Dentro del propio path (semánticos)
- Detalles de anuncio
✨ Semana 2 ✨
El developer trabaja lunes y martes en SEO, es muy bueno y rápido con lo que con tan poco tiempo logra avanzar bastante.
Durante el día de ayer hemos estado preparando el path de nuevas landings. Mucho bug fixing: canonicals, alternates de mobile, meta tags... 😅
El developer trabaja lunes y martes en SEO, es muy bueno y rápido con lo que con tan poco tiempo logra avanzar bastante.
Durante el día de ayer hemos estado preparando el path de nuevas landings. Mucho bug fixing: canonicals, alternates de mobile, meta tags... 😅
La base que cogimos era bastante mala con lo que hemos tenido que invertir bastante en ponerlo bien, pero era mejor que empezar de cero.
Ya tiene montado también todo el linking interno desde categoría y detalle, esa parte fue super rápida 💨
Ya tiene montado también todo el linking interno desde categoría y detalle, esa parte fue super rápida 💨
Si todo va bien, hoy mismo podemos lanzar el path con las +90.000 páginas. A malas, el próximo lunes 🚀
También le he pasado para este nuevo deploy algunos cambios que me dejé en el robots.txt y el fix del Schema de los Breadcrumbs 🥖
También le he pasado para este nuevo deploy algunos cambios que me dejé en el robots.txt y el fix del Schema de los Breadcrumbs 🥖
🎯 Resultados hasta el momento 🎯
Los errores de Breacrumbs por subir, pero ya los ha ido detectando. El de Producto lo ha leído todo bien y ya muestra rich snippets de Precio + Imagen.
Queda pendiente analizar el impacto en CTR que tiene esto, pero debería ser relevante.
Los errores de Breacrumbs por subir, pero ya los ha ido detectando. El de Producto lo ha leído todo bien y ya muestra rich snippets de Precio + Imagen.
Queda pendiente analizar el impacto en CTR que tiene esto, pero debería ser relevante.


A nivel de robots.txt, con la gran podada ✄ que hicimos, ya se empieza a ver el aumento brutal de páginas bloqueadas.
Eso es bueno, el problema del progreso de esto es que no aparece en GSC hasta que la URL no entra en el scheduler, con lo que no se ve el impacto real ahora.
Eso es bueno, el problema del progreso de esto es que no aparece en GSC hasta que la URL no entra en el scheduler, con lo que no se ve el impacto real ahora.

No tengo acceso a logs, pero después de los cambios en el robots.txt todo parece haber seguido bien.
El tráfico orgánico sube +12% vs. semana previa (probablemente estacionalidad), pero almenos vemos que no nos hemos cargado nada (solo HTML).
El tráfico orgánico sube +12% vs. semana previa (probablemente estacionalidad), pero almenos vemos que no nos hemos cargado nada (solo HTML).

❌ Problemas detectados ❌
Mirando más a fondo vi que la web está replicada en 10 hosts en subdominios.
dominio.dominio.com
dominio2.dominio.com
beta.dominio.com
y así...
Queda pendiente subir un robots.txt para hosts "no oficiales" para bloquear rastreo.
Mirando más a fondo vi que la web está replicada en 10 hosts en subdominios.
dominio.dominio.com
dominio2.dominio.com
beta.dominio.com
y así...
Queda pendiente subir un robots.txt para hosts "no oficiales" para bloquear rastreo.
Otro problema detectado es que tal y como funciona la ordenación de listados a día de hoy, hace que el linking vaya todo a items recientes y no llegue a los más antiguos.
Con el path de landings nuevas esto debería quedar semi solucionado 🧐
Con el path de landings nuevas esto debería quedar semi solucionado 🧐
Con las nuevas reglas de robots.txt queda todo mucho más limitado, pero hay demasiadas orphan, hay un problema grande con anuncios antiguos que habrá que solucionar, pero esto para más adelante... 👋🏼

• • •
Missing some Tweet in this thread? You can try to
force a refresh


