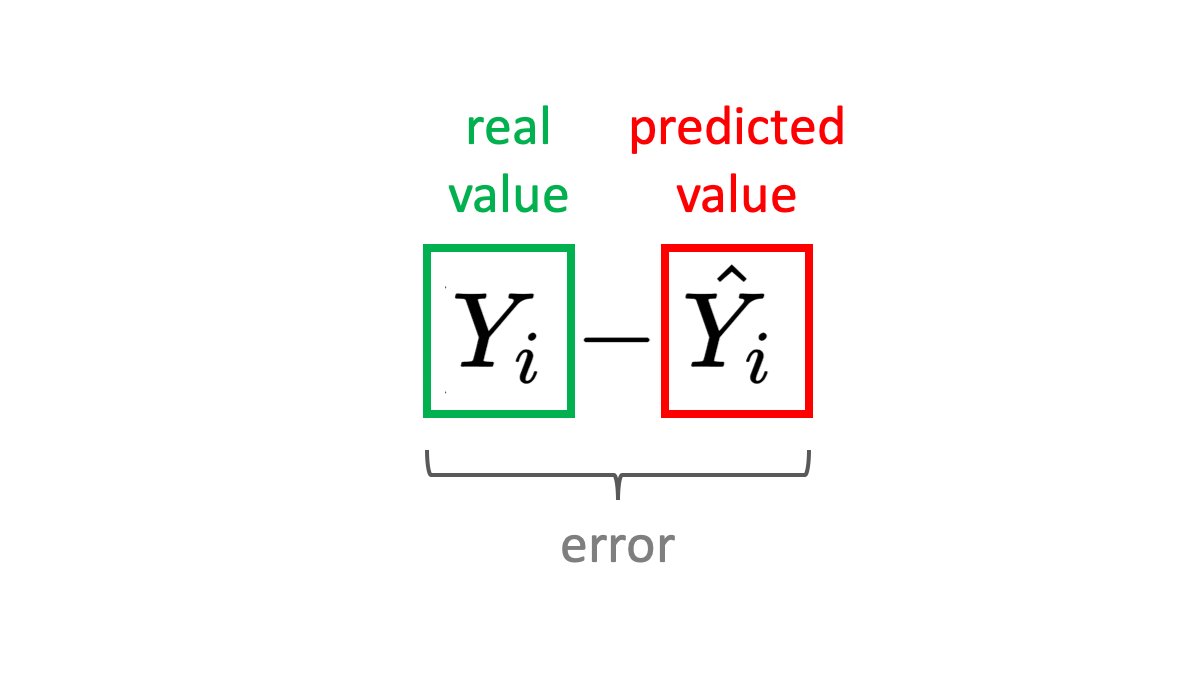
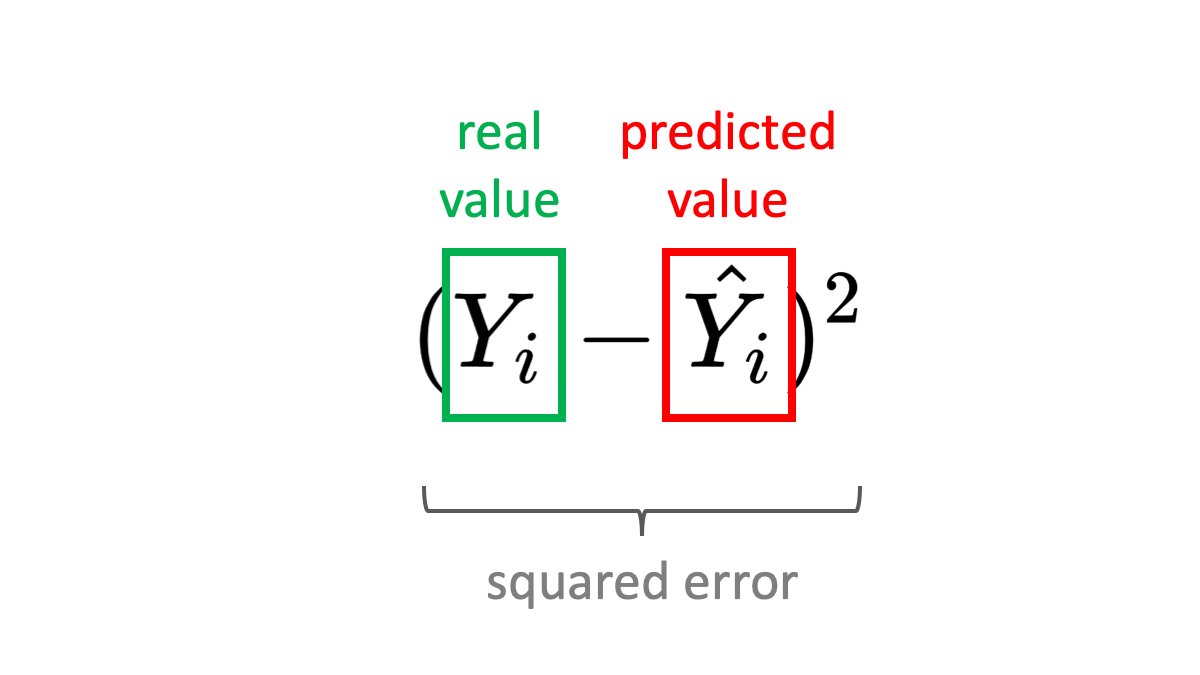
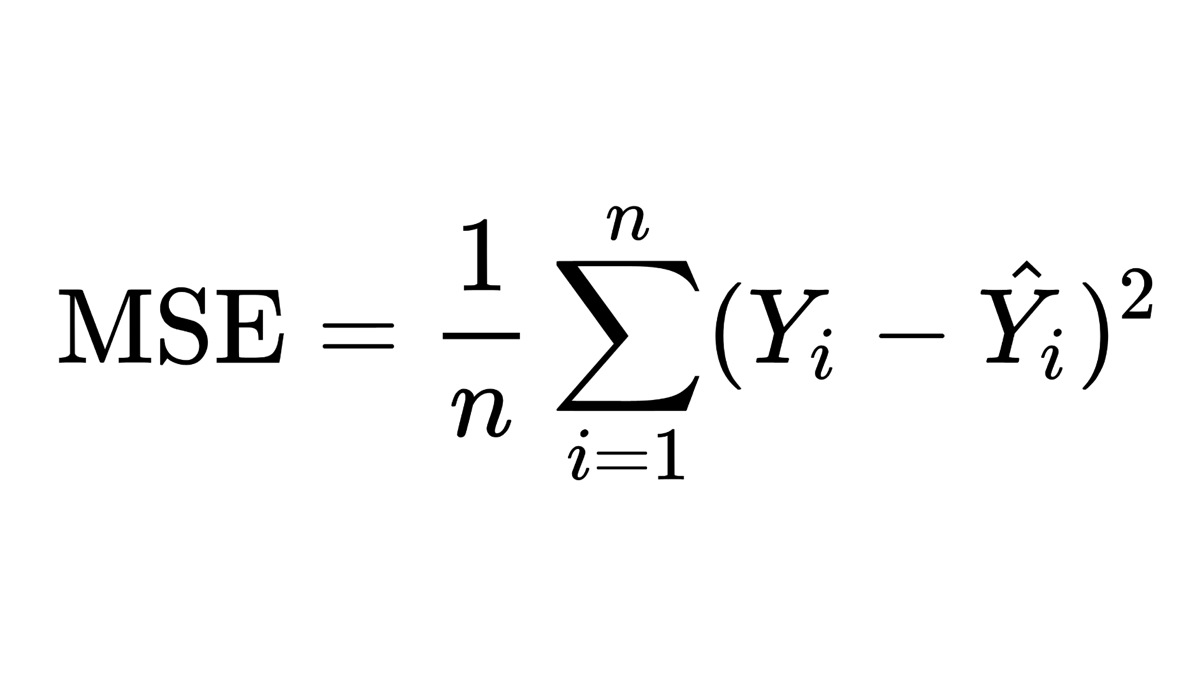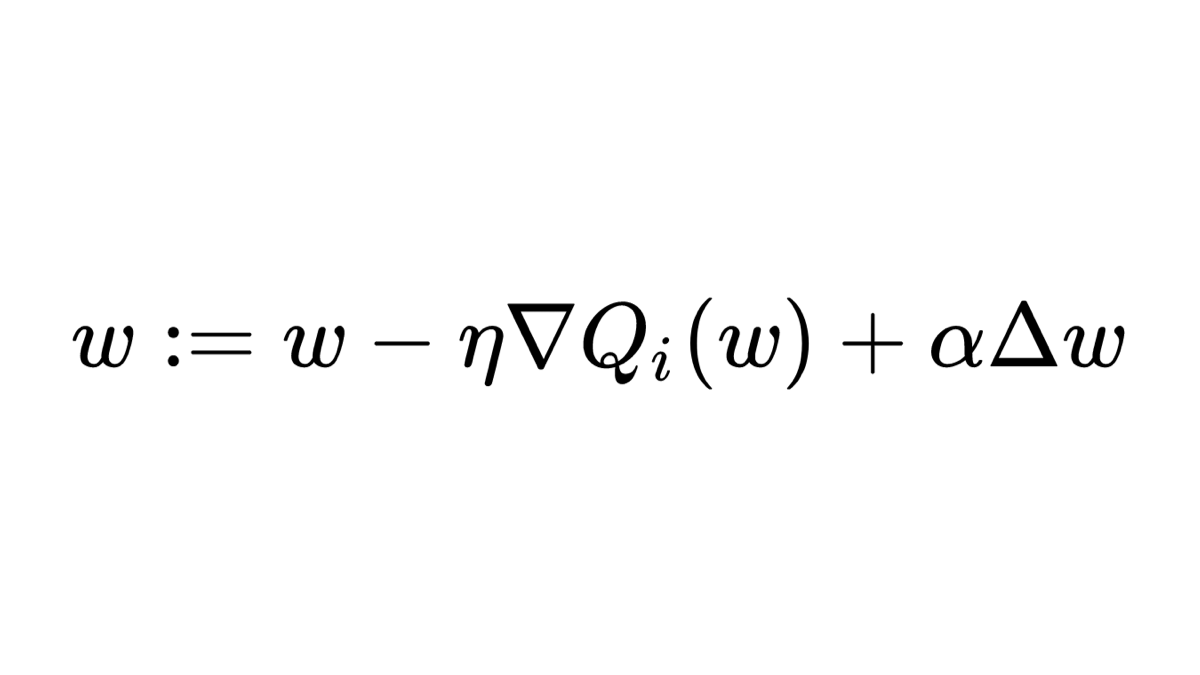What are Convolutional Neural Networks? 🏞️ ⏭️ ⛰️
CNNs are an important class of deep artificial neural networks that are particularly well suited for images.
If you want to learn the important concepts of CNNs and understand why they work so well, this thread is for you!
🧵👇
CNNs are an important class of deep artificial neural networks that are particularly well suited for images.
If you want to learn the important concepts of CNNs and understand why they work so well, this thread is for you!
🧵👇
What is a CNN? 🤔
A CNN is a deep neural network that contains at least one convolutional layer. A typical CNN has a structure like this:
▪️ Image as input
▪️ Several convolutional layers
▪️ Several interleaved pooling layers
▪️ One/more fully connected layers
Example: AlexNet
A CNN is a deep neural network that contains at least one convolutional layer. A typical CNN has a structure like this:
▪️ Image as input
▪️ Several convolutional layers
▪️ Several interleaved pooling layers
▪️ One/more fully connected layers
Example: AlexNet
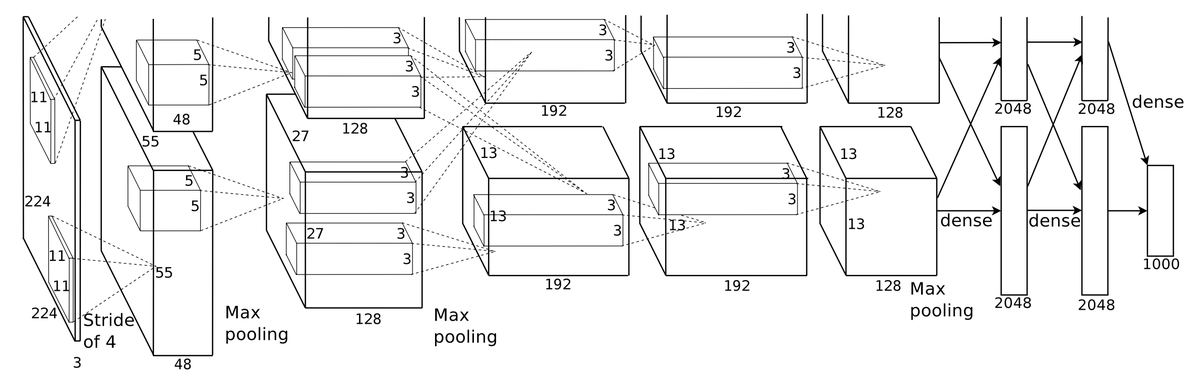
A good example - AlexNet
Throughout the thread I will be giving examples based on AlexNet - this is the net architecture that arguably started the whole deep learning revolution in computer vision!
I've written more about AlexNet here:
Throughout the thread I will be giving examples based on AlexNet - this is the net architecture that arguably started the whole deep learning revolution in computer vision!
I've written more about AlexNet here:
https://twitter.com/haltakov/status/1310591421771059200
Convolutional Layer *️⃣ ⏸️
Each convolutional layer is defined by a set of filters which are used on the input to transform it into some other representation.
A typical filter may detect horizontal edges or some specific color in the image.
The filters defined as convolutions.
Each convolutional layer is defined by a set of filters which are used on the input to transform it into some other representation.
A typical filter may detect horizontal edges or some specific color in the image.
The filters defined as convolutions.
Convolution Filter *️⃣
Here is how it works on the example of an image:
1️⃣ Take a small matrix (for example 5x5) - the filter
2️⃣ Overlay it over the image, multiply the pixel values with the matrix values and add them up
3️⃣ Slide the matrix over the whole image
Here is how it works on the example of an image:
1️⃣ Take a small matrix (for example 5x5) - the filter
2️⃣ Overlay it over the image, multiply the pixel values with the matrix values and add them up
3️⃣ Slide the matrix over the whole image
Real examples 🔬
Let's see what kind of filters AlexNet uses (it actually learns them, but will come to that in a moment). The example shows 11x11 filters that detect different features.
1️⃣ - horizontal edges
2️⃣ - vertical edges
3️⃣ - green patches
4️⃣ - blue to yellow edges
Let's see what kind of filters AlexNet uses (it actually learns them, but will come to that in a moment). The example shows 11x11 filters that detect different features.
1️⃣ - horizontal edges
2️⃣ - vertical edges
3️⃣ - green patches
4️⃣ - blue to yellow edges

The first Convolutional Layer *️⃣ ⏸️
The image as processed with many filters in the first layer (96 for AlexNet).
Every filter will effectively create a new image (called feature map) telling you where the filter "found" matching patterns.
Example for edge detection filters.
The image as processed with many filters in the first layer (96 for AlexNet).
Every filter will effectively create a new image (called feature map) telling you where the filter "found" matching patterns.
Example for edge detection filters.



The next Convolutional Layer *️⃣ ⏸️
The next layer will have as input not the image, but the feature maps from the previous layer. Now it can combine simple features to create more complex ones.
For example, find places in the image with both horizontal and vertical edges.
The next layer will have as input not the image, but the feature maps from the previous layer. Now it can combine simple features to create more complex ones.
For example, find places in the image with both horizontal and vertical edges.
Hierarchical architecture 🌲
Layer after layer the network will be combining more and more complex features giving it more expressive power. This is one of the big advantages of deep CNNs!
However, you may be wondering now - where do the filters come from???
Layer after layer the network will be combining more and more complex features giving it more expressive power. This is one of the big advantages of deep CNNs!
However, you may be wondering now - where do the filters come from???
Feature Learning 👨🏫
This is the coolest thing - the optimal filters are learned automatically by the network!
In traditional ML methods the features are usually engineered by people, but this is one of the greatest advantages of CNNs - they are learned from the data!
How...?
This is the coolest thing - the optimal filters are learned automatically by the network!
In traditional ML methods the features are usually engineered by people, but this is one of the greatest advantages of CNNs - they are learned from the data!
How...?
Parametrization 🔡
In classical NNs we connect each neuron of a layer to all of the neurons in the input and assign the connection some weight.
In CNNs the weights are the values in the filter matrix and they are shared over the whole image! This is way more efficient.
In classical NNs we connect each neuron of a layer to all of the neurons in the input and assign the connection some weight.
In CNNs the weights are the values in the filter matrix and they are shared over the whole image! This is way more efficient.
Parametrization 🔡
Imagine an image of 100x100 pixels. Every neuron in the first layer will have 10000 weights. 10000 per neuron❗
For a CNN with 100 3x3 filters we need 900 weights + 100 for the bias.
Indeed, 96% of the weights of AlexNet are in the dense layers!
Imagine an image of 100x100 pixels. Every neuron in the first layer will have 10000 weights. 10000 per neuron❗
For a CNN with 100 3x3 filters we need 900 weights + 100 for the bias.
Indeed, 96% of the weights of AlexNet are in the dense layers!
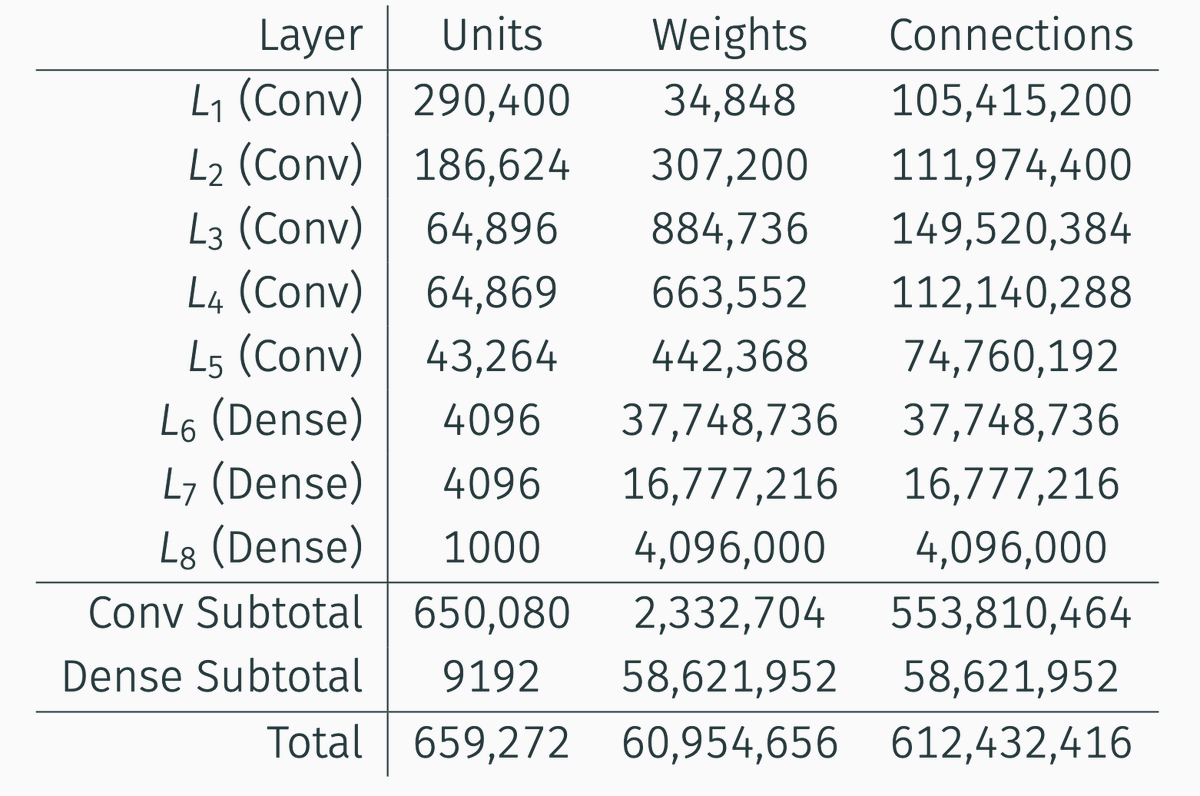
Training 🏋️
As with regular neural nets, during training we can use backpropagation to find the best weights for our problem. This is how the weights of the filter matrices will be optimized and the network will learn the best filters for our problem.
As with regular neural nets, during training we can use backpropagation to find the best weights for our problem. This is how the weights of the filter matrices will be optimized and the network will learn the best filters for our problem.
Local connectivity ⭕
CNNs are very suitable for images, because they exploit the local connectivity between pixels - pixels next to each other are usually correlated.
The way the filters are applied over the image also make them invariant to translation, which is important.
CNNs are very suitable for images, because they exploit the local connectivity between pixels - pixels next to each other are usually correlated.
The way the filters are applied over the image also make them invariant to translation, which is important.
Global context 🏞️
But wait, if we only look at 5x5 patches, how do we see the "big picture"? How do we use info from different parts of the image?
We scale the image down! When we make the image smaller, a 3x3 filter will correspond to a bigger patch of the original image.
But wait, if we only look at 5x5 patches, how do we see the "big picture"? How do we use info from different parts of the image?
We scale the image down! When we make the image smaller, a 3x3 filter will correspond to a bigger patch of the original image.
Pooling 💠
While there are ways to reduce resolution with convolutions, let's focus on pooling for now.
The idea is simple:
1️⃣ Take a NxN patch of the feature map
2️⃣ Replace it with a single value - the max or average value in the patch
This will reduce the resolution by N
While there are ways to reduce resolution with convolutions, let's focus on pooling for now.
The idea is simple:
1️⃣ Take a NxN patch of the feature map
2️⃣ Replace it with a single value - the max or average value in the patch
This will reduce the resolution by N
Pooling is useful as a way to select the strongest features and also give the network some additional translation invariance. In practice, a 2x2 pooling is usually used.
Typical architecture 🏛️
In a typical CNN, convolutional and pooling layers are alternated. The resolution of the feature maps is reduced through the network, but we usually increase the number of feature maps. The CNN will then learn more high-level features.
In a typical CNN, convolutional and pooling layers are alternated. The resolution of the feature maps is reduced through the network, but we usually increase the number of feature maps. The CNN will then learn more high-level features.
Summary 🏁
▪️ CNNs use convolutions to compute feature maps describing the image
▪️ The filters share the weights over the image reducing the number of parameters
▪️ CNNs exploit the local relationships between pixels
▪️ CNNs can learn high-level image features and concepts
▪️ CNNs use convolutions to compute feature maps describing the image
▪️ The filters share the weights over the image reducing the number of parameters
▪️ CNNs exploit the local relationships between pixels
▪️ CNNs can learn high-level image features and concepts
Further reading 📖
Make sure that you also read this great thread on the topic by @svpino!
Make sure that you also read this great thread on the topic by @svpino!
https://twitter.com/svpino/status/1360462217829900290
Sources 📃
I used images from the following sources:
▪️ Convolution example from this awesome repo: github.com/vdumoulin/conv…
▪️ AlexNet examples from the original paper: papers.nips.cc/paper/4824-ima…
▪️ These slides on AlexNet for the parameters table: cs.toronto.edu/~rgrosse/cours…
I used images from the following sources:
▪️ Convolution example from this awesome repo: github.com/vdumoulin/conv…
▪️ AlexNet examples from the original paper: papers.nips.cc/paper/4824-ima…
▪️ These slides on AlexNet for the parameters table: cs.toronto.edu/~rgrosse/cours…
• • •
Missing some Tweet in this thread? You can try to
force a refresh