
Gimana caranya mesin memahami bahasa manusia?
.
.
.
A Thread
.
.
.
A Thread
Komunikasi adalah suatu hal yang paling esensial dalam kehidupan manusia. Tidak dipungkiri setiap hari kita melakukan komunikasi baik kepada keluarga, teman, tetangga, maupun sahabat
Tapi kebayang ga sih hidup tanpa komunikasi, pasti bakal sulit banget untuk mengerti maksud lawan bicara kita. Apalagi kalau yang pacaran.. pasti bisa berantem terus dehh
Lalu di era yang canggih ini, pernah ga sih kalian ngebayangin kenapa komputer atau mesin bisa mengerti bahasa manusia? Kenapa mereka bisa memahami maksud kita melalui tulisan seperti ini?
Misalnya melalui chat bot atau robot yang bisa ngobrol sama manusia. Kira-kira bagaimana yah?
Jadi sebenarnya mesin juga bisa mengerti bahasa manusia karena mereka diajarkan juga.. Eits tapi ya jangan dibayangin mesin diajari membaca dan mengenal huruf seperti kita saat masih kecil dulu ya 😂
Tentunya karena tulisan atau huruf langsung tidak bisa secara langsung dipahami oleh mesin, jadi kita harus mengubah terlebih dahulu bentuk huruf / tulisan ini menjadi bentuk yang dipahami oleh mesin
Ya benar! Karena bentuk yang dipahami mesin adalah angka, maka kita harus mengubah terlebih dahulu huruf-huruf tersebut menjadi angka.
Tapi sebelum diubah, kita harus membersihkan terlebih dahulu kalimat yang kita miliki agar mesin lebih mudah mengolah kata-kata yang kita gunakan. Kira-kira begini prosesnya,
Pertama kalimat yang kita miliki akan diekstrak terlebih dahulu sehingga lebih mudah dipahami oleh mesin. Pemecahan ini terdiri dari dua proses yaitu tokenization dan juga lemmatization
Tokenization adalah proses dimana kita memecah kalimat berdasarkan kata per katanya atau berdasarkan frasa yang ada dalam kalimat tersebut. 

Dalam proses ini juga tanda baca dihilangkan gais, karena dianggap tidak memberikan informasi tambahan pada kalimat misalnya seperti . , ! dan tanda baca lainnya
Misalnya kita memiliki kalimat :
“Aku senang mempelajari machine learning!”
“Aku senang mempelajari machine learning!”
Maka saat dilakukan tokenization akan menjadi
[‘Aku, ‘senang’, ‘mempelajari’, ‘machine’, ‘learning’]
[‘Aku, ‘senang’, ‘mempelajari’, ‘machine’, ‘learning’]
Nah dalam proses ini kita juga harus berhati hati untuk memecah kalimatnya ya, karena bisa jadi terdapat frasa yang jika dipecah akan memberikan arti berbeda
Misalnya pada kalimat “aku membeli buah tangan”. Frasa “buah tangan” jika dipecah menjadi ‘buah’ dan ‘tangan’ akan memberikan arti berbeda, padahal sebenarnya maksud kalimat tersebut bukan seperti itu 😅
Sampai sini masih paham lah ya, lanjut gais ke lemmatization
Sebelum dilakukan lemmatization, beberapa kata yang dianggap “stopwords” akan dihilangkan. Stopwords ini bisa dibilang kata-kata yang dianggap tidak memberikan arti yang signifikan pada kalimat jadi bisa dihilangkan
Kata kata yang biasa digolongkan menjadi stopwords itu biasanya merupakan kata hubung misalnya dan, untuk, yang, kepada dan masih banyak lagi
Kata yang termasuk stopwords ini bisa di custom ya guys, kalian bisa bebas menambahkan atau mengurangi daftar stopwords pada dictionary / library yang kalian gunakan
Setelah stopwords dihilangkan, maka sekarang adalah proses lemmatization. Pada proses ini, setiap kata / frasa yang telah dipecah akan dikembalikan pada kata dasarnya, dan dijadikan bentuk tunggal (singular) serta dibuat menjadi lowercase
Misalnya pada kalimat tadi, hasil proses lemmatizationnya adalah
[‘aku’, ‘senang’, ‘belajar’, ‘machine’, ‘learning’]
[‘aku’, ‘senang’, ‘belajar’, ‘machine’, ‘learning’]
Nah kalau sudah seperti ini kata-kata yang ada sudah siap diproses melalui machine learning deh!
Agar dapat dimengerti oleh mesin, kumpulan kata-kata ini akan diubah menjadi bentuk matriks supaya bisa dipahami dan dilakukan perhitungan oleh mesin, dan proses ini biasanya disebut word embedding.
Salah satu word embedding yang mudah dipahami adalah metode TF-IDF (Term Frequency(TF) - Inverse Dense Frequency(IDF))
Misalnya kita punya 3 kalimat nih,
Kalimat 1 : This movie is very scary and long (7 kata)
Kalimat 2: This movie is not scary and is slow (8 kata)
Kalimat 3: This movie is spooky and good (6 kata)
Kalimat 1 : This movie is very scary and long (7 kata)
Kalimat 2: This movie is not scary and is slow (8 kata)
Kalimat 3: This movie is spooky and good (6 kata)
Berarti vocabulary yang kita miliki disini ada 11 kata ya
‘This’, ‘movie’, ‘is’, ‘very’, ‘scary’, ‘and’, ‘long’, ‘not’, ‘slow’, ‘spooky’, ‘good’
‘This’, ‘movie’, ‘is’, ‘very’, ‘scary’, ‘and’, ‘long’, ‘not’, ‘slow’, ‘spooky’, ‘good’
Untuk menghitung nilai TF, kita hanya perlu membagi banyaknya kata tersebut muncul pada kalimat dengan banyaknya kata pada kalimat tersebut
Jadi untuk menghitung nilai TF(‘this’, kalimat 2) adalah ⅛, karena kata ‘this’ pada kalimat 2 muncul sebanyak 1 kali dan banyaknya kata pada kalimat 2 adalah 8 kata
Dengan cara serupa bisa kita dapatkan nilai TF(‘movie’, kalimat 1) = 1/7 dan seterusnya

Sedangkan nilai IDF adalah log(banyaknya kalimat dibagi dengan banyaknya kalimat yang mengandung kata tersebut)
Misalnya untuk IDF(‘this’) = log(3/3) = 0 dan IDF(‘not) = log(3/1) = 0.48 karena hanya ada 1 kalimat (kalimat 2) yang mengandung kata ‘not’

Dan terakhir, nilai TF-IDF adalah perkalian nilai TF dan IDF saja
TF-IDF(‘this’, kalimat 2) = TF(‘this’, kalimat 2) * IDF(‘this’) = ⅛ * 0 = 0
TF-IDF(‘this’, kalimat 2) = TF(‘this’, kalimat 2) * IDF(‘this’) = ⅛ * 0 = 0
Setelah ini tinggal kita bandingkan saja nilai TF-IDF pada setiap kalimat. Nilai TF-IDF yang tinggi akan menandakan kata tersebut berperan penting dalam kalimat tersebut.
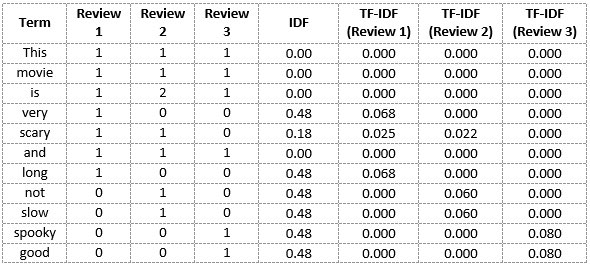
Jadi bisa kita ketahui bahwa inti kalimat 1 adalah very scary dan long, kalimat 2 adalah not scary dan slow, dan kalimat 3 adalah spooky dan good. Berarti ketiga kalimat ini memiliki pandangan berbeda-beda ya terhadap film tersebut 😁
Singkatnya seperti itu guys cara mesin mempelajari bahasa manusia. Kalau kamu penasaran dan tertarik mengenai NLP serta machine learning, kamu bisa ikut kelas Pacmann.AI lho! (bridging)
Kalau kemarin kalian ketinggalan daftar di batch 2, tenang aja, pendaftaran batch 3 dibuka tanggal 22 Maret nanti. Atau kalau kalian mau cek kurikulumnya, bisa dulu liat di bit.ly/brosurpacmannai atau tanya kami di bit.ly/WASalesPacmann. Sampai jumpa di batch 3!
• • •
Missing some Tweet in this thread? You can try to
force a refresh


