How to easily edit and compose images like in Photoshop using GANs🔥
❓What?
Given an incomplete image or a collage of images, generate a realistic image
📌How?
1.Train a regressor to predict StyleGAN latent code even from incomplete image
2.Embedd collage and send it to GAN
❓What?
Given an incomplete image or a collage of images, generate a realistic image
📌How?
1.Train a regressor to predict StyleGAN latent code even from incomplete image
2.Embedd collage and send it to GAN

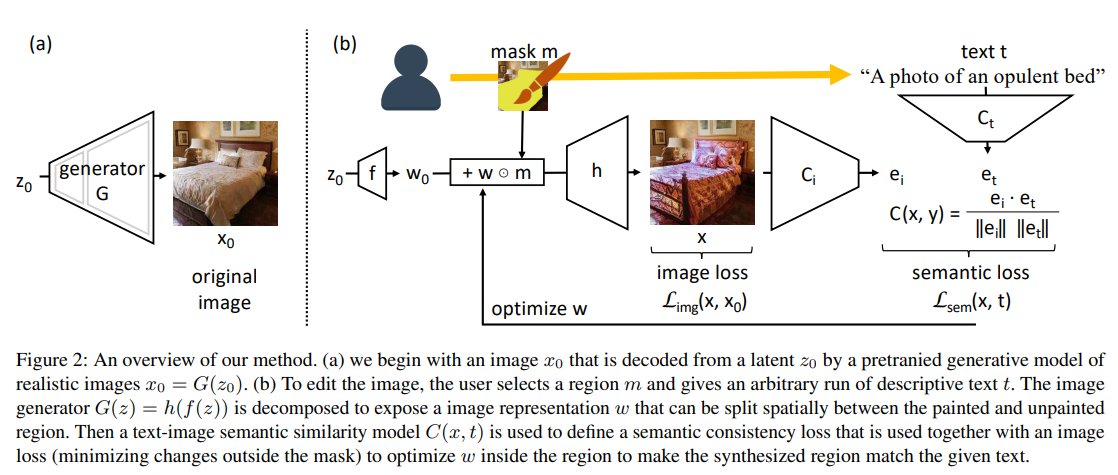
Using latent space regression to analyze and leverage compositionality in GANs
🔶Method
Given a fixed pretrained generator (e.g., StyleGAN), they train...
📝arxiv.org/abs/2103.10426
🧿Project page chail.github.io/latent-composi…
🛠️chail.github.io/latent-composi…
📔colab: colab.research.google.com/drive/1p-L2dPM…
🔶Method
Given a fixed pretrained generator (e.g., StyleGAN), they train...
📝arxiv.org/abs/2103.10426
🧿Project page chail.github.io/latent-composi…
🛠️chail.github.io/latent-composi…
📔colab: colab.research.google.com/drive/1p-L2dPM…
... they train a regressor network to predict
the latent code from an input image. To teach the regressor to predict the latent code for images w/ missing pixels they mask random patches during training.
Now, given an input collage, the regressor projects it into a reasonable...
the latent code from an input image. To teach the regressor to predict the latent code for images w/ missing pixels they mask random patches during training.
Now, given an input collage, the regressor projects it into a reasonable...
... given an input collage, the regressor projects it into a reasonable location of the latent space, which then the generator maps onto the image manifold. Such an approach enables more localized editing of individual image parts compared to direct editing in the latent space
4/
4/
Interesting findings:
- Even though our regressor is never trained on unrealistic and incoherent collages, it projects the given image into a reasonable latent code.
- Authors show that the representation of the generator is already compositional in the latent code. Meaning..
5/
- Even though our regressor is never trained on unrealistic and incoherent collages, it projects the given image into a reasonable latent code.
- Authors show that the representation of the generator is already compositional in the latent code. Meaning..
5/
Meaning that altering the part of the input image, will result in a change of the regressed latent code in the corresponding location.
➕Pros
-As input, we need only a single example of approximately how we want the generated image to look (can be a collage of dif. images)
6/
➕Pros
-As input, we need only a single example of approximately how we want the generated image to look (can be a collage of dif. images)
6/
- Requires only one forward pass of the regressor and generator -> fast, unlike iterative optimization approaches that can require up to a minute to reconstruct an image. arxiv.org/abs/1911.11544
- Does not require any labeled attributes
📎Applications
- image inpainting ...
7/
- Does not require any labeled attributes
📎Applications
- image inpainting ...
7/
- example-based image editing (incoherent collage -> to realistic image)
That's it!😉
That's it!😉

Subscribe to my Telegram channel not to miss other novel paper reviews like this! 😉
t.me/gradientdude
t.me/gradientdude
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh