Dell EMC Host Connectivity Guide for Windows
P/N 300-000-603
REV 61
MAY 2020
9.5 mb pdf
delltechnologies.com/en-us/collater…
P/N 300-000-603
REV 61
MAY 2020
9.5 mb pdf
delltechnologies.com/en-us/collater…
i've found that Execution Throttle was relied on so heavily in the past with QLogic HBAs that many folks are unfamilar with setting a per-LUN servic queue depth for QLogic in Windows.
The Dell host connectivity guide i linked above in the thread discusses this on page 67. 

Before changing LUN service queue depth regardless of host HBA make/model, consider. requirements/recommendations for the storage array.
Working in the past with EMC CLARiiON arrays and some of the older Hitachi arrays, there was good reason not to set higher than 32.
Working in the past with EMC CLARiiON arrays and some of the older Hitachi arrays, there was good reason not to set higher than 32.
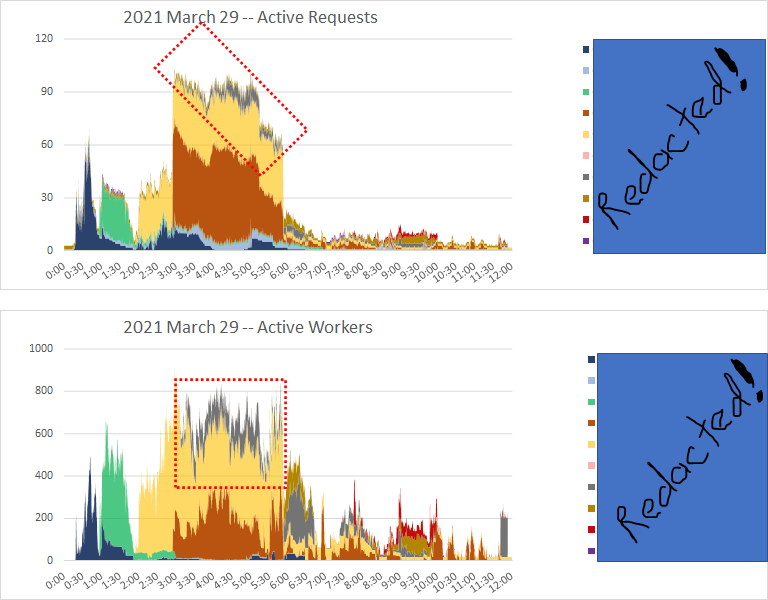
Why consider increasing LUN service queue depth from default?
Consider this example. Much higher average write service time in the dark blue box than the light blue box. Even though total bytes/sec is lower.
Consider this example. Much higher average write service time in the dark blue box than the light blue box. Even though total bytes/sec is lower.

Looking at an individual LUN from perfmon, same comparison between dark blue and light blue boxes. Except bytes/sec is expectedly lower all around, and average write/sec service time is higher.

Looking at IOPs it's pretty much the same story. Neither bytes/sec nor IOPs explains the higher avg write service times in the dark blue box.

Saturated write cache, high pending writes, forced write cache flushes can elevate both write and read service times.
Something like a copy-on-write snapshot being maintained at that time of this capture could elevate avg write service times, too.
Something like a copy-on-write snapshot being maintained at that time of this capture could elevate avg write service times, too.
A COW snapshot would transform first writes into [read from source] + [write to snapshot] + [write to source] unless using a shadow filesystem strategy like NetApp.
COW without shadow filesystem is more painful on all HDDs than on an AFA, but there's still overhead on an AFA.
COW without shadow filesystem is more painful on all HDDs than on an AFA, but there's still overhead on an AFA.
• • •
Missing some Tweet in this thread? You can try to
force a refresh