
CNN bisa deteksi psychological disorders pengguna Reddit?! 🤔🤨
.
.
.
A thread
.
.
.
A thread
Siapa yang disini sejak pandemi jadi gampang stress??
Kalau lagi stress, sedih, atau lagi badmood, kalian suka ga sih curhat di sosmed atau seengkanya mengungkapkan emosi kalian gitu walaupun ga menjelaskan penyebabnya secara detail?
Kalau mimin sih salah satu tipe yang mengekspresikannya di sosmed, ya walaupun ga menjelaskan penyebabnya dengan detail. Kalau kamu tipe yang kaya gini juga, tenang aja, kita ga sendiri kok!
Sosial media itu udah sering banget digunakan penggunanya buat mengekspresikan perasaan mereka. Nah, makanya ga sedikit pengguna yang menceritakan bagaimana keadaan mentalnya di sosmed.
Dengan trend yang kaya gini, banyak penelitian yang mencoba buat mendeteksi keadaan kesehatan mental seseorang berdasarkan status di sosmednya. Kali ini, mimin bakal bahas salah satu penelitian yang mencoba buat detect hal tersebut berdasarkan postingan pengguna Reddit.
Reddit ini semacam sosial media pada umumnya gitu guys, cuma yang membedakan adalah mereka punya semacam “sub-tema” gitu yang dinamakan “sub-reddit”. Nah, disini, ada juga subreddit yang bertemakan kesehatan mental.
Penelitian yang mimin bahas di thread ini mau mendeteksi kesehatan mental pengguna Reddit yang aktif memposting di sub tema r/depression, r/bipolar, r/anxiety, r/BPD, r/schizophrenia, dan r/autism.
Oh iya, disclaimer dulu, penelitian ini udah disetujui sama Ethical Committee and Institutional Review Board of the Department of Applied Artificial Intelligence, Sungkyunkwan University.
Oke, kita lanjutkan yaa. Melihat tujuan penelitian, maka para peneliti mengumpulkan data posting dan user dari ke-enam sub-reddit tersebut. Detail data yang dikumpulkan bisa kalian lihat di gambar ini: 
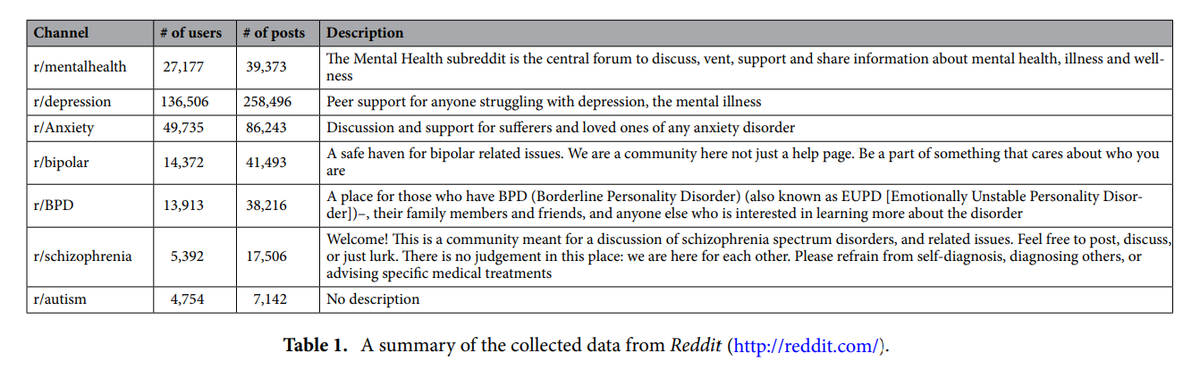
Kalau ditotalkan, data awal yang dikumpulkan itu berjumlah 633,385 post dari 248,537 pengguna. Data ini merupakan postingan pada rentang waktu Januari 2017 hingga Desember 2018.
Sebelum peneliti mengolah datanya, mereka melakukan preprocessing datanya dulu nih. Mereka menghilangkan tanda baca dan spasi yang ga begitu penting pada setiap postingan.
Selanjutnya, mereka juga menggunakan natural language toolkit (NLTK) di Python untuk men-’tokenize’ postingan pengguna dan nge-filter kata-kata yang sering digunakan.
Peneliti juga menggunakan Porter Stemmer, yakni tools yang digunakan untuk mencari definisi atau maksud dari kata-kata yang sering digunakan tadi, sehingga kita bisa tau apa arti inti dari kata tersebut dan mengurangi word corpusnya.
Setelah data preprocessing ini, akhirnya data yang digunakan berkurang jadi tinggal 448,472 postingan dari 228,060 pengguna. Lengkapnya bisa kalian lihat disini:

Langkah selanjutnya adalah memulai klasifikasi. Awalnya, peneliti ngebuat 6 klasifikasi sesuai dengan subreddit tadi; r/depression, r/anxiety, r/bipolar, r/BPD, r/schizophrenia, r/autism.
Tapi nih, setiap pengguna itu kan bisa posting di lebih dari 1 subreddit yaa. Contohnya bisa aja satu pengguna posting di r/depression sama r/anxiety. Kalau kaya gini, nanti training modelnya jadi punya noisy data.
Maka dari itu, akhirnya peneliti memutuskan buat bikin 6 klasifikasi independen saja untuk setiap mental disorder, jadi setiap pengguna dianggap hanya punya 1 kondisi aja sehingga nanti peneliti bisa mengidentifikasi secara akurat.
‘Eeh-- bentar min, emang datanya sudah pasti balance ya?’ Tenang guys, untuk mengatasi masalah ini, peneliti menerapkan algoritma synthetic minority over sampling technique (SMOTE).
Oke, kita lanjutin ya. Data-data ini kemudian dibagi jadi 2 nih, 80% nya untuk training dan 20% nya untuk testing. Terus biar tau kira-kira model apa yang cocok untuk melakukan klasifikasi, peneliti nguji model XGBoost sama convolutional neural network (CNN).
Untuk XGBoost, peneliti menggunakan TF-IDF vectorizer di sckit-learn package untuk mengubah kata-kata ke n-dimentional vectors. Nah, kalau untuk CNN, peneliti menggunakan word2vec API nya python package, genism.
Untuk yang CNN sendiri, kira kira cara kerjanya seperti ini:
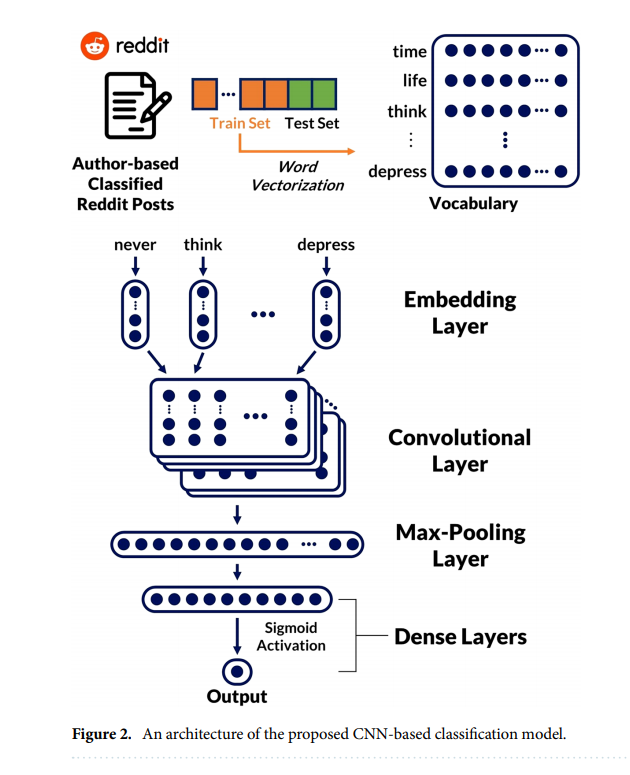
Terus kalau udah diproses pakai XGBoost dan CNN, nentuiin model yang paling baiknya gimana caranya?
Nah, kita butuh ‘evaluasi’ nih dari kedua model tersebut. Maka dari itu, peneliti menghitung nilai true positive, false positive, false negative, dan true negative. Kalau udah ketemu nilainya, nanti akan digunakan untuk mencari accuracy, precision, dan recall.
Dulu, Pacmann udah pernah bahas nih tentang confusion matrix dan perhitungan accuracy, precision, dan recall di thread ini:
https://twitter.com/pacmannai/status/1376504490317074437
Nah, ga berhenti disitu aja, peneliti juga mencari F1-score dari kedua model. Penemuannya seperti ini:
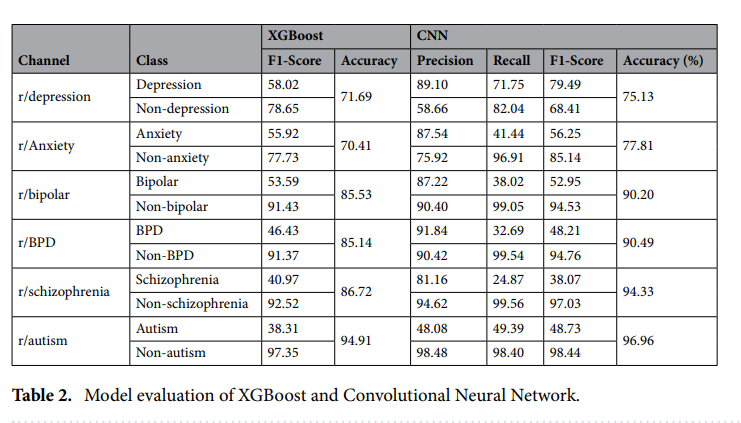
Kalau kita perhatikan, diantara keenam subreddit, r/autism memiliki akurasi tertinggi di model CNN, tapi memiliki nilai F1-score terendah diantara subreddit lain. Hal ini disebabkan oleh masalah class imbalance.
Tapi, kalau secara umum, model CNN ini memiliki akurasi lebih tinggi dibandingkan XGBoost di keenam subreddit. Kalau disimpulkan, model yang digunakan dalam penelitian ini bisa mendeteksi secara akurat pengguna potensial yang mungkin memiliki psychological disorders.
Lalu apa yang bisa diambil dari penelitian ini?
Melihat kalau model yang digunakan dalam penelitian ini memiliki akurasi yang tinggi, maka platform sosial media bisa nih memainkan peranan untuk mencegah atau membantu para penggunanya yang mungkin memiliki psychological disorders.
Nah, mungkin kamu bisa juga nih jadi salah satu yang mengembangkan fitur yang membantu para pengguna ini. Tentunya, untuk mewujudkan hal ini, kamu harus memahami per-machine-learningan dulu.
Kamu bisa belajar di Data Scientist Pacmann.AI. Ga cuma belajar dari dasar aja, tapi kamu juga berkesempatan buat bikin project lab yang bisa dijadikan portfolio kamu nih. Cek informasi lengkapnya di bit.ly/PacmannioTwitt… yaa!
Oh iya, kalau kamu penasaran mau ngotak ngatik datanya, bisa diakses di sini yaa guys: jina-kim.github.io/dataset/20srep… atau kalau mau baca paper lengkapnya, baca disini yaa: nature.com/articles/s4159…
• • •
Missing some Tweet in this thread? You can try to
force a refresh


