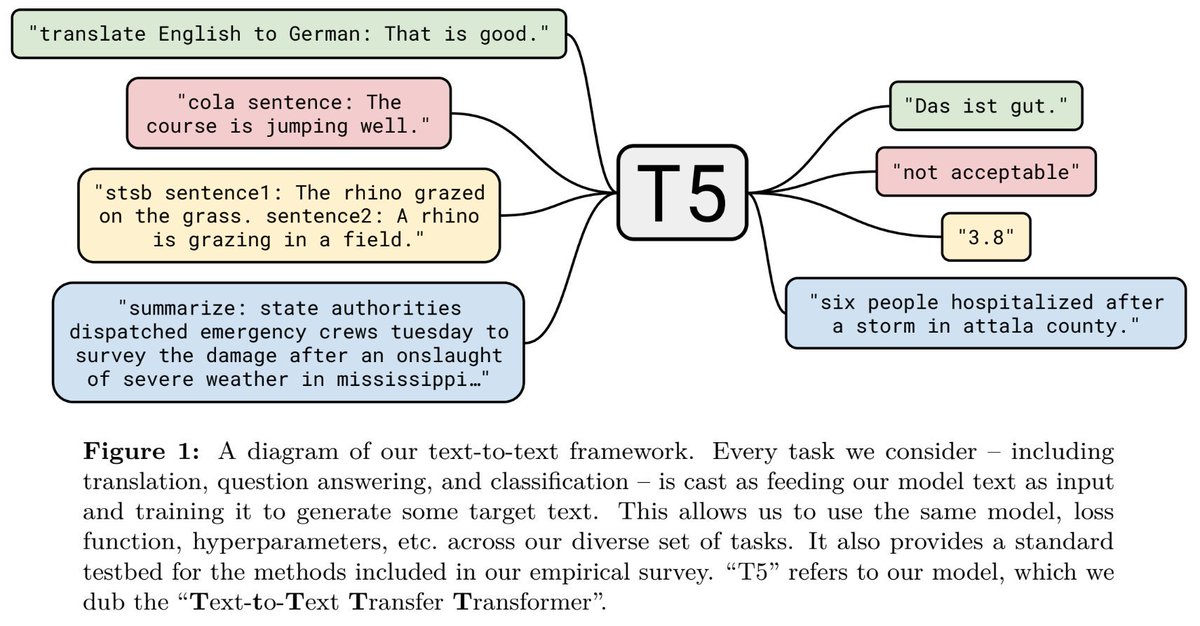
Can your NLP model handle noooisy mEsSy #realworldtext?
ByT5 works on raw UTF-8 bytes (no tokenization!), beats SoTA models on many popular tasks, and is more robust to noise.
📜 Preprint: arxiv.org/abs/2105.13626
💾 Code/Models: github.com/google-researc…
Summary thread ⬇️ (1/9)
ByT5 works on raw UTF-8 bytes (no tokenization!), beats SoTA models on many popular tasks, and is more robust to noise.
📜 Preprint: arxiv.org/abs/2105.13626
💾 Code/Models: github.com/google-researc…
Summary thread ⬇️ (1/9)
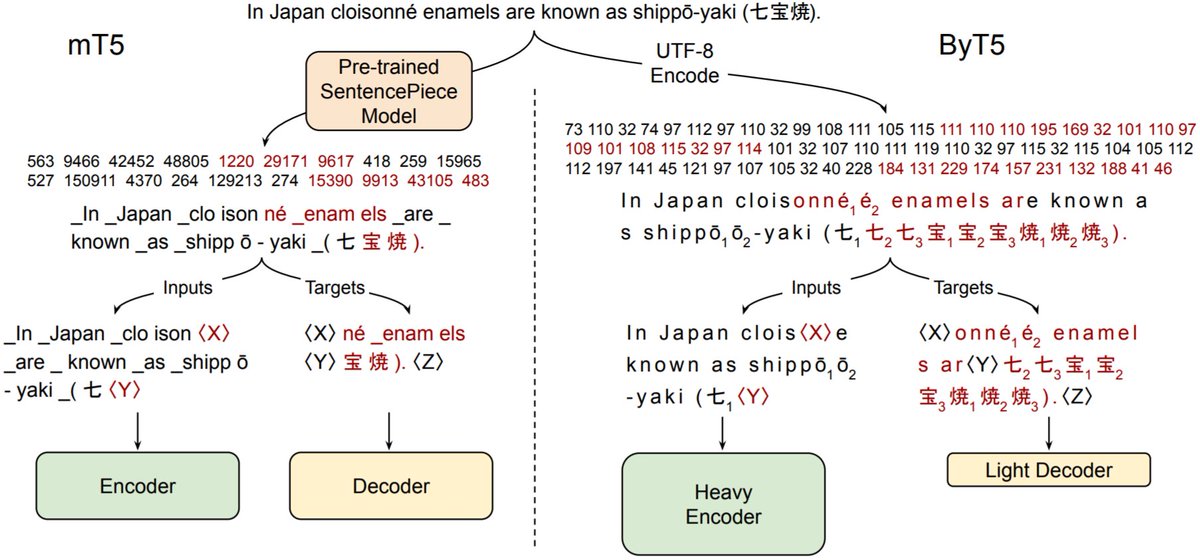
Tokenizers have many drawbacks:
- Finite, fixed vocabulary - often can't process new/unseen languages
- Lack of robustness to missspeling and n o i s e
- Not learned "end-to-end"
- Giant vocabulary matrices in the multilingual setting
- Lots of technical debt in practice
(2/9)
- Finite, fixed vocabulary - often can't process new/unseen languages
- Lack of robustness to missspeling and n o i s e
- Not learned "end-to-end"
- Giant vocabulary matrices in the multilingual setting
- Lots of technical debt in practice
(2/9)
Operating on the raw byte sequence used to represent text (e.g. UTF-8) solves many of the aforementioned issues. The main drawback: Sequence lengths tend to increase significantly compared to using token sequences.
(3/9)
(3/9)
Past work on byte-level models has therefore mainly focused on architectural innovations (convolutional front-ends, downsampling, etc.) to mitigate the increased computational cost that comes along with longer byte-level sequences.
(4/9)
(4/9)
With ByT5, we instead ask: What are the minimal changes to turn a token-to-token model (mT5) into a reasonably efficient byte-level model? Turns out it's basically
1. Make the encoder bigger and decoder smaller
2. Use a longer span mask lengths during (MLM) pre-training
(5/9)
1. Make the encoder bigger and decoder smaller
2. Use a longer span mask lengths during (MLM) pre-training
(5/9)
The above changes result in a model that
- performs about as well as its token-level counterpart on "normal" tasks
- performs *dramatically* better on tasks dealing with pronunciation and noisy text
- is not dramatically slower, especially on tasks with short outputs
(6/9)
- performs about as well as its token-level counterpart on "normal" tasks
- performs *dramatically* better on tasks dealing with pronunciation and noisy text
- is not dramatically slower, especially on tasks with short outputs
(6/9)
Some positive results to highlight:
- Much better on TweetQA
- Boosts on XTREME in gold + translate-train settings
- Noise like raNDOm CaSe causes ~1% performance degradation in ByT5 vs. ~25% for mT5
- ByT5-Small/Base/Large are about as fast as mT5 on XNLI
(7/9)
- Much better on TweetQA
- Boosts on XTREME in gold + translate-train settings
- Noise like raNDOm CaSe causes ~1% performance degradation in ByT5 vs. ~25% for mT5
- ByT5-Small/Base/Large are about as fast as mT5 on XNLI
(7/9)
On the negative side, the larger variants of ByT5 are quite a lot slower at inference time on tasks that require generating long outputs (for example, ByT5-XXL is ~7x slower than mT5-XXL on XSUM). Good avenues for future work!
(8/9)
(8/9)
More details & results in our preprint: arxiv.org/abs/2105.13626
As always, code, models, & data are available: github.com/google-researc…
Work done mainly by my amazing coauthors: @lintingxue, Aditya Barua, @noahconst, @aboSamoor, @sharan0909, Mihir Kale, & @ada_rob
(9/9)
As always, code, models, & data are available: github.com/google-researc…
Work done mainly by my amazing coauthors: @lintingxue, Aditya Barua, @noahconst, @aboSamoor, @sharan0909, Mihir Kale, & @ada_rob
(9/9)
• • •
Missing some Tweet in this thread? You can try to
force a refresh