In case you missed our #neurips poster on MixMatch (arxiv.org/abs/1905.02249) today because you aren't in Vancouver or didn't survive the poster session stampede, here's the PDF: github.com/google-researc… and here's a transcript of what I said to everyone who came by: ⬇️ 1/11
The goal in semi-supervised learning (SSL) is to use unlabeled data to improve a model's performance. Many approaches do this by using the model to produce "label guesses" for unlabeled data, and then training the model to predict those guesses. 2/11
Two common ingredients for producing label guesses are consistency regularization ("When I perturb the input or model, the model's prediction shouldn't change.") and entropy minimization ("The model should output low-entropy/confident predictions on unlabeled data.") 3/11
Another important ingredient when doing semi-supervised learning is regularization, because typically we only have a few labels and it's easy for the model to memorize them. 4/11
MixMatch is a *holistic* SSL algorithm which combines these ingredients in a simple recipe. MixMatch first feeds k augmented versions of an unlabeled image to the model to obtain k predictions. It then averages the k predictions and "sharpens" the result. 5/11 

Sharpening simply corresponds to lowering the distribution's temperature. The sharpened average prediction is then used as the label guess for the original unlabeled image. 6/11
After we've obtained label guesses, we just proceed as if we're doing supervised learning, with label guesses as targets for unlabeled examples and the ground-truth labels as targets for labeled examples. 7/11
For regularization, we use weight decay and MixUp (arxiv.org/abs/1710.09412) across both labeled and unlabeled examples. This is super important to get good performance. 8/11
The combination of these ingredients produced SoTA results in the realistic SSL setting (arxiv.org/abs/1804.09170) when MixMatch came out. For example, we achieved an error rate of about 11% with only 250 labels on CIFAR-10. 9/11
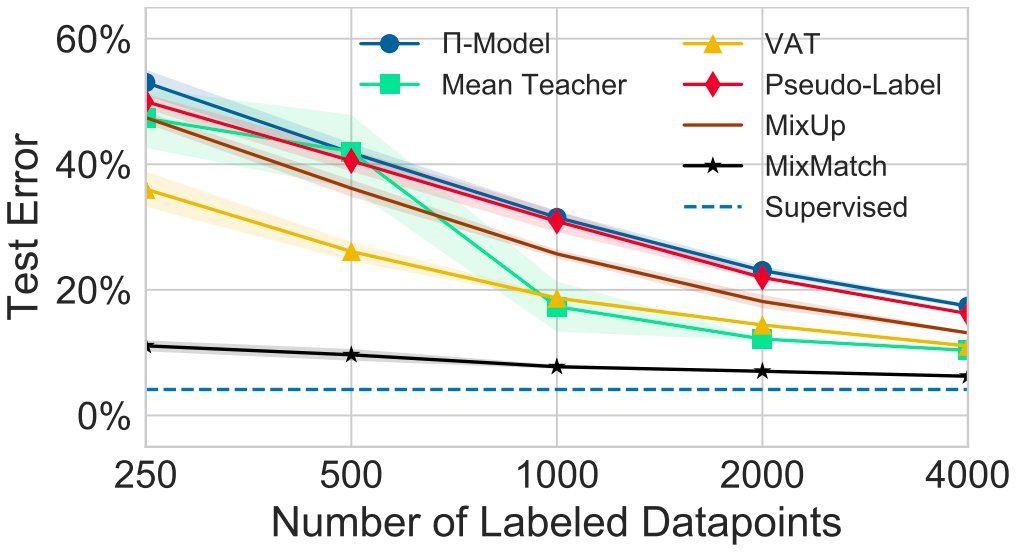
The MixMatch paper includes experiments on other datasets as well as a nice ablation study. In the past 6 months, our results have been beaten - including by us! Look out for more exciting SSL results soon. 10/11
Our code is available here: github.com/google-researc… MixMatch is joint work with @d_berthelot_ml, @goodfellow_ian, Nicholas Carlini, @avitaloliver, and @nicolaspapernot. Thanks for coming to my Twitter poster presentation! 11/11