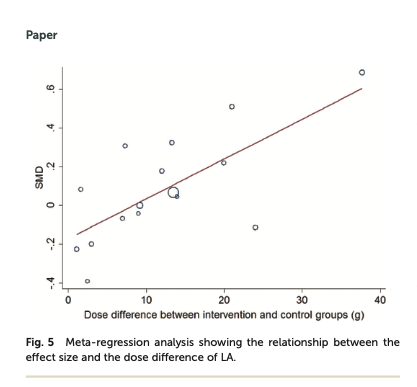
#ScienceBreakdown:
"The Phytochemical Diversity of Commercial #Cannabis in the United States."
This is a preprint for a study I recently completed with collaborators at @CUSystem: @bkeegan, @cannagenomics.
Descriptive summary of the study below.
biorxiv.org/content/10.110…
1/
"The Phytochemical Diversity of Commercial #Cannabis in the United States."
This is a preprint for a study I recently completed with collaborators at @CUSystem: @bkeegan, @cannagenomics.
Descriptive summary of the study below.
biorxiv.org/content/10.110…
1/
Some questions we asked:
How diverse is #cannabis in the US in terms of cannabinoid + terpene content?
Are similar or distinct chemical phenotypes (chemotypes) seen across US states?
What are the most common chemotypes we reliably see and about how many are there?
...
2/
How diverse is #cannabis in the US in terms of cannabinoid + terpene content?
Are similar or distinct chemical phenotypes (chemotypes) seen across US states?
What are the most common chemotypes we reliably see and about how many are there?
...
2/
Do industry labelling systems align w/ underlying chemistry? Any systematic difference, above chance levels, for samples labelled Indica vs. Sativa?
How about strain names? Are any reliably associated w/ certain chemotypes or are they random w/ respect to product chemistry?
3/
How about strain names? Are any reliably associated w/ certain chemotypes or are they random w/ respect to product chemistry?
3/
We analyzed #cannabis lab testing data from six US states, consisting of cannabinoid + terpene profiles from 10,000s of flower samples.
WA (@ConfAnalytics), OR (@ChemHistoryLabs), CA (@SCLaboratories), AL (@CannTest), MI (@PSILabs), FL (@ModernCanna).
4/
WA (@ConfAnalytics), OR (@ChemHistoryLabs), CA (@SCLaboratories), AL (@CannTest), MI (@PSILabs), FL (@ModernCanna).
4/
We also used @Leafly data to match sample strain names with their common, commercial Indica/Hybrid/Sativa designation, and assess the level of consumer popularity associated with each strain name.
So... here is a brief summary of what we saw.
5/
So... here is a brief summary of what we saw.
5/
Cannabinoid diversity.
>95% of commercial #cannabis in the US is THC-dominant.
Almost all the variation in cannabinoid content is explained by variation in total THC, CBD, and CBG levels, with THC explaining the bulk.
6/
>95% of commercial #cannabis in the US is THC-dominant.
Almost all the variation in cannabinoid content is explained by variation in total THC, CBD, and CBG levels, with THC explaining the bulk.
6/

Based on biochem of cannabinoid production, there are constraints on cannabinoid ratios you will see.
This is why you see three distinct THC:CBD chemotypes and correlations between THC/CBD/CBG.
So, we see what you'd expect. Not much cannabinoid diversity beyond THC levels.
7/
This is why you see three distinct THC:CBD chemotypes and correlations between THC/CBD/CBG.
So, we see what you'd expect. Not much cannabinoid diversity beyond THC levels.
7/


Terpenes.
First, we looked at which terpenes were most common. Across states, we see a similar set of terpenes that are more abundant than others.
For example, myrcene, caryophyllene and limonene are the most abundant.
8/
First, we looked at which terpenes were most common. Across states, we see a similar set of terpenes that are more abundant than others.
For example, myrcene, caryophyllene and limonene are the most abundant.
8/

Looked for certain terpene correlations were reliably present across states, which we also expect from the biology.
Example: caryophyllene and humulene have a strong correlation due to the biochem of how they are produced.
Saw this in each state, mostly as a sanity check.
9/
Example: caryophyllene and humulene have a strong correlation due to the biochem of how they are produced.
Saw this in each state, mostly as a sanity check.
9/


Next, looked at all terpenes consistently measured in each state & how they correlate with each other.
Lots of terpenes correlate with certain other terpenes, i.e. there are "entourages" of terpenes you tend to find in different #cannabis samples.
10/
Lots of terpenes correlate with certain other terpenes, i.e. there are "entourages" of terpenes you tend to find in different #cannabis samples.
10/

Again, what we expected to see based on past work. We saw that these patterns are present across US states.
Network diagram below is a more compact picture of which terpenes tend to co-occur most often. Thicker lines = stronger correlation between terpenes.
11/
Network diagram below is a more compact picture of which terpenes tend to co-occur most often. Thicker lines = stronger correlation between terpenes.
11/

Most of US #cannabis is THC-dominant, not CBD-dominant or Balanced. But are the THC-dominant samples also more diverse in terms of terpene profiles?
A: Yep.
High-CBD flower is less diverse, with a higher % of samples being myrcene-dominant compared to high-THC samples.
12/
A: Yep.
High-CBD flower is less diverse, with a higher % of samples being myrcene-dominant compared to high-THC samples.
12/


So... let's focus on the chemical diversity we see among THC-dominant samples, which represent the bulk of commercial #cannabis.
How well do Indica/Hybrid/Sativa labels map to the chemical diversity we actually see in THC-dominant #cannabis?
13/
How well do Indica/Hybrid/Sativa labels map to the chemical diversity we actually see in THC-dominant #cannabis?
13/
Most budtenders will tell you, confidently: Indicas are sedating, Sativas are energizing.
If true, you'd expect to see that "Indica" and "Sativa" samples, *as they are labelled & presented to consumers,* should display, on average, some kind of chemical difference...
14/
If true, you'd expect to see that "Indica" and "Sativa" samples, *as they are labelled & presented to consumers,* should display, on average, some kind of chemical difference...
14/
We took all the THC-dominant samples where the producer supplied a strain name, matched those to their most common commercial Indica/Hybrid/Sativa designation (using @Leafly), and looked at how well these labels map to the underlying terpene profiles...
15/
15/
If the Indica/Sativa labels mapped to distinct terpene profiles you'd expect to mostly see Indica dots (purple) on one side of the chart, Sativa dots (red) elsewhere, and Hybrid dots (green) in between.
16/
16/

That's NOT what we see... but if you squint, maybe there's a mostly red clump of dots near the top, in the cloud of dots on upper part of graph?
(I'll come back to this).
Basic observation: Indica/Hybrid/Sativa labels do not map to terpene variation very well overall.
17/
(I'll come back to this).
Basic observation: Indica/Hybrid/Sativa labels do not map to terpene variation very well overall.
17/

You can explain diversity in terpene profiles for THC-dominant #cannabis by just knowing the single most abundant terpene for each sample. That has a lot more explanatory power than Indica/Sativa.
18/
18/

We also used a clustering algorithm to look at the same data. This analysis allows to define in a more unbiased way how many distinct terpene chemotypes we see for commercial #cannabis in the US.
19/
19/

A: About three.
You can lump of split these further, but the three major terpene profiles we see can be described as:
1.) Very high myrcene with pinene
2.) High caryophyllene + limonene
3.) High terpinolene
Note, these are relative levels, not all-or-none differences.
/20
You can lump of split these further, but the three major terpene profiles we see can be described as:
1.) Very high myrcene with pinene
2.) High caryophyllene + limonene
3.) High terpinolene
Note, these are relative levels, not all-or-none differences.
/20

We see the same basic pattern across all six US states. So, it's not like the #cannabis in California is filled with a chemotype you never see in Michigan, or something like that.
The major terpene profiles we see among THC-dominant cannabis show up reliably across states.
/21
The major terpene profiles we see among THC-dominant cannabis show up reliably across states.
/21

We further quantified how well (or poorly) these different approaches to labelling samples capture the underlying chemistry.
Violin chart on the left shows that using "Commercial Category" (Indica/Sativa) to label samples does NOT tell you much about product chemistry.
/22
Violin chart on the left shows that using "Commercial Category" (Indica/Sativa) to label samples does NOT tell you much about product chemistry.
/22

We used used another visualization technique (UMAP) to represent the terpene profiles of our THC-dominant samples.
Dots are color-coded by which of the three main clustering we defined with our clustering algo. Notice that some clusters have more dots than others.
/23
Dots are color-coded by which of the three main clustering we defined with our clustering algo. Notice that some clusters have more dots than others.
/23

We can simply average all the profiles in each cluster to see what the relative ratios of major terpenes are for #cannabis samples in each cluster:
/24
/24



What about the strain names? First, we looked at the correlation between how many samples of lab data were attached to each strain name and how often the corresponding pages on @Leafly are viewed.
i.e. does consumer popularity correlate w/ number of products tested?
A: Yes
/25
i.e. does consumer popularity correlate w/ number of products tested?
A: Yes
/25

Next, took 10 most popular strain names, looked at similarity of terpene profiles across each producer that had several or more samples w/ that strain name.
Not going to fully unpack, but matrix shows how similar products are across producers across these strain names.
/26
Not going to fully unpack, but matrix shows how similar products are across producers across these strain names.
/26

So, we can measure how similar the profiles are for each product w/ a given strain name, across producers.
In other words, we might have 50 producers with "Original Glue" #cannabis samples. For each producer, we compare their Original Glue product to the other producers'.
/27
In other words, we might have 50 producers with "Original Glue" #cannabis samples. For each producer, we compare their Original Glue product to the other producers'.
/27
That gives us a set of numbers, each one telling us how similar two Original Glue products is. For each strain name we have a range of such similarity numbers (and an average for that strain name).
We do this for each strain name we have a good amount of data for:
/28
We do this for each strain name we have a good amount of data for:
/28

Key is where each blob is compared to dashed line, which is the number you get if you randomly shuffle all strain names across all products.
So: how consistent is each strain name, product-to-product, compared to what you'd see if everyone choose strain names randomly?
/29
So: how consistent is each strain name, product-to-product, compared to what you'd see if everyone choose strain names randomly?
/29

Many strain names are *more* similar than you'd expect from the random shuffle, a couple are *less* similar, and some show no more product-to-product similarity than you'd expect if people named their products at random.
/30
/30

This result may surprise some. I think many people expect that the strain names are totally haphazardly applied, and contain absolutely no information about the underlying product chemistry.
That does not appear to be true, at least for certain popular strain names.
/31
That does not appear to be true, at least for certain popular strain names.
/31

Important to recognize that even the strain names that display statistically significant product-to-product similarity, they still tend to display a quite a wide range.
/32
/32

If you randomly pick up two distinct #cannabis flower products that share the same strain name, the odds that they have the same basic chemotype depends heavily on which strain name they share.
/33
/33

Let's look at two concrete examples: Purple Punch displays relatively high product-to-product similarity, while Tangie does not.
Most (but not all) Purple Punch products fall into our "high caryophyllene-limonene" cluster, while Tangie is all over the place.
/34
Most (but not all) Purple Punch products fall into our "high caryophyllene-limonene" cluster, while Tangie is all over the place.
/34

Looking at the same comparison in a different way, we can highlight products attached to either Purple Punch or Tangie in the context of our UMAP visualization.
This is showing you where these products fall within the full landscape of terpene profiles we observe.
/35
This is showing you where these products fall within the full landscape of terpene profiles we observe.
/35

Purple Punch products (black triangles) are in the same basic neighborhood (similar chemotype).
To me, this is remarkable, b/c we're talking about products made by separate producers, who are often in separate US states.
In contrast, Tangie products are all over the map.
/36
To me, this is remarkable, b/c we're talking about products made by separate producers, who are often in separate US states.
In contrast, Tangie products are all over the map.
/36

Ok, let's go back to the Indica/Sativa thing. Previously we showed that Indica/Sativa labels do NOT do well at explaining overall variation in terpene profiles.
But... is there any over-representation of Indica vs. Sativa-associated strain names in *any* of the clusters?
/37
But... is there any over-representation of Indica vs. Sativa-associated strain names in *any* of the clusters?
/37
A: There is, in one place.
Our "high terpinolene" cluster contains an overrepresentation of samples with strain names associated with "Sativa" designations.
/38
Our "high terpinolene" cluster contains an overrepresentation of samples with strain names associated with "Sativa" designations.
/38

This is pulling out the potential pattern we had to squint to see earlier.
Going on a slight tangent, this pattern reminds me of something @trichomics and colleagues have seen before, analyzing genomic data.
Hmm...
journals.plos.org/plosone/articl…
/39
Going on a slight tangent, this pattern reminds me of something @trichomics and colleagues have seen before, analyzing genomic data.
Hmm...
journals.plos.org/plosone/articl…
/39


Anyways, what about strain names? Are any overrepresented in our clusters?
A: Yes
/40
A: Yes
/40

Ok, this is an obnoxiously long thread, so I will leave it there. We think these results help move our chemotaxonmic understanding of commercial #cannabis forward, and can inform the design of both animal and human studies.
/41
/41

If we want to test common claims about distinct psychoactive or medicinal effects common from different types of #cannabis, then we should design experiments that use chemical ratios similar to those observed in the cannabis people are using under 'ecological' conditions.
/42
/42

• • •
Missing some Tweet in this thread? You can try to
force a refresh