#Medical #AI has the worst superpower... Racism
We've put out a preprint reporting concerning findings. AI can do something humans can't: recognise the self-reported race of patients on x-rays. This gives AI a path to produce health disparities.
1/8
lukeoakdenrayner.wordpress.com/2021/08/02/ai-…
We've put out a preprint reporting concerning findings. AI can do something humans can't: recognise the self-reported race of patients on x-rays. This gives AI a path to produce health disparities.
1/8
lukeoakdenrayner.wordpress.com/2021/08/02/ai-…
This is a big deal, so we wanted to do it right. We did dozens of experiments, replication at multiple labs, on numerous datasets and tasks.
We are releasing all the code, as well as new labels to identify racial identity for multiple public datasets.
2/8
We are releasing all the code, as well as new labels to identify racial identity for multiple public datasets.
2/8
Humans can't detect race better than chance, but AI performs absurdly well on the task. As you can see here, AUC scores are in the high 90s, and are maintained on external validation on completely distinct datasets and across multiple different imaging tasks.
3/8
3/8
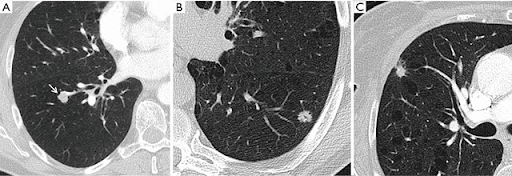
We performed many experiments to work out how it does this, but couldn't pin it down.
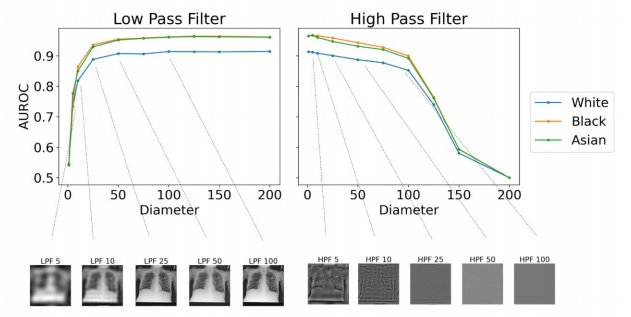
This is the most ridiculous figure I have ever seen. AI can detect race from images filtered so heavily they are just blank grey squares! (see the bottom right of the figure)
4/8
This is the most ridiculous figure I have ever seen. AI can detect race from images filtered so heavily they are just blank grey squares! (see the bottom right of the figure)
4/8
Here is the direct link to the paper, but in the first tweet of this thread is a link to my blog post which acts as a companion piece: I explain why we think this is bad and what we think needs to happen.
TL:DR below (this is text from the blog)
5/8
arxiv.org/abs/2107.10356
TL:DR below (this is text from the blog)
5/8
arxiv.org/abs/2107.10356

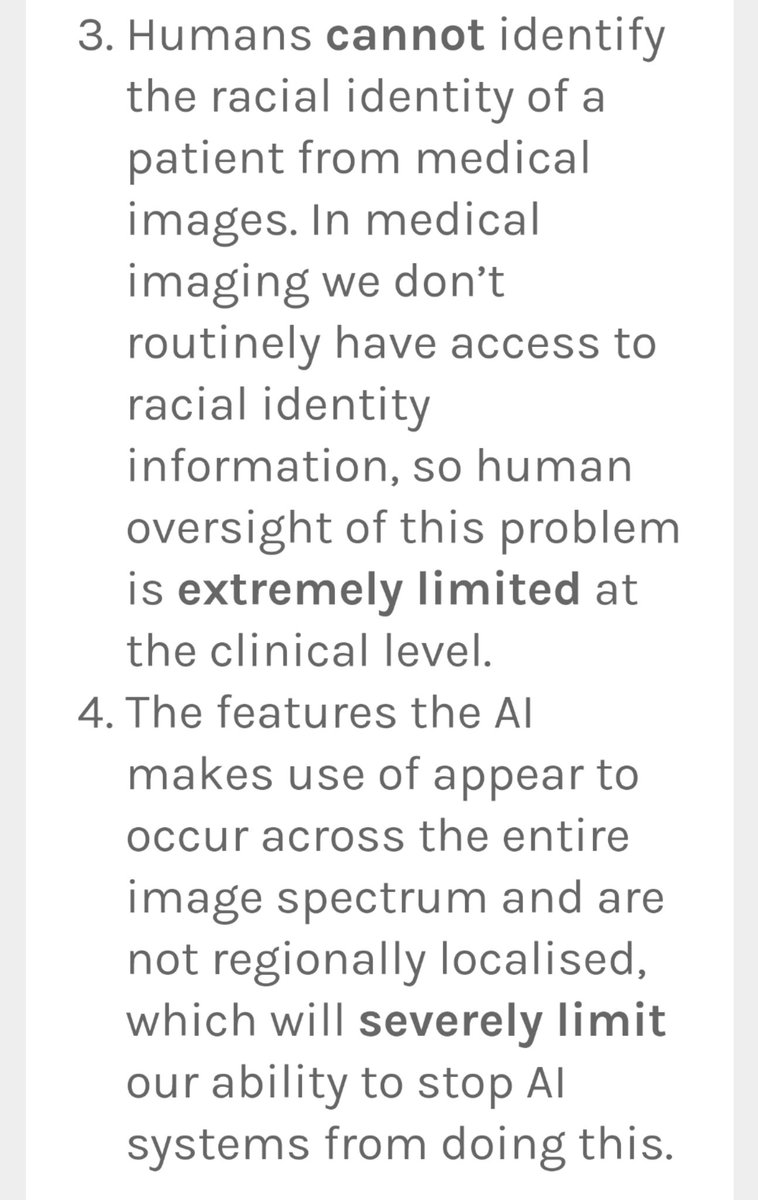
We are ringing alarm bells here. AI systems trained on standard medical datasets appear to learn to recognise race *by default* and we don't have the capabilities to detect the resulting bias in practice, or to mitigate it technologically.
6/8
6/8
With dozens of AI systems already on the market trained on data exactly like this, we are calling for urgent testing of performance across racial groups. We already know that medical practice is biased, but AI can embed health disparities at scale and cause serious harm.
7/8
7/8
Finally, this is a preprint, it hasn't been peer reviewed. We are looking for feedback, and suggestions for next steps. This work is important, but we don't know so much about what is happening here, and that isn't good enough. Anyone interested in helping out, let us know!
8/8
8/8
I want to acknowledge everyone but don't have Twitter handles for most (do y'all seriously not have them 😂😂).
PS This was a "flat" research collaboration without hierarchy, so authors are listed alphabetically. There is no first author or last author! Take that #Academia!
PS This was a "flat" research collaboration without hierarchy, so authors are listed alphabetically. There is no first author or last author! Take that #Academia!

Hi everyone. This thread has been swamped by racists. I'm probably gonna miss your replies, but I'll still be here in a few days when they move on or you can reach out through other channels.
We appreciate all the wonderful support we've received from the community 🤩
We appreciate all the wonderful support we've received from the community 🤩
• • •
Missing some Tweet in this thread? You can try to
force a refresh