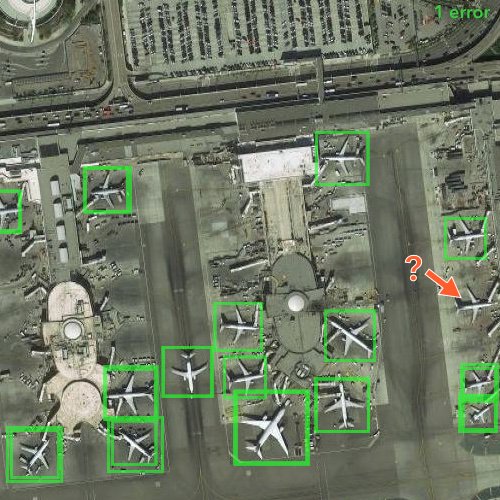
Here is Mask R-CNN, the most popular architecture used for object detection and segmentation. 

The conceptual principle of the R-CNN family is to use a two-step process for object detection:
1) a Region Proposal Network (RPN) identifies regions of interests(ROIs)
2) The ROIs are cut from the image and fed through a classifier.
1) a Region Proposal Network (RPN) identifies regions of interests(ROIs)
2) The ROIs are cut from the image and fed through a classifier.

In fact, the cutting is not done the original image but directly on the feature maps extracted from the backbone. Since the feature maps are much lower resolution than the image, the cropping requires some care: sub-pixel extraction and interpolation aka. "ROI alignment".

This makes Mask R-CNN effectively single-pass !
Extracted features are then used for classification and segmentation. To generate segmentation masks, the architecture uses "transpose convolutions", marked as "deconv." in the architecture diagram.
Extracted features are then used for classification and segmentation. To generate segmentation masks, the architecture uses "transpose convolutions", marked as "deconv." in the architecture diagram.

All illustrations from "Practical Machine Learning for Computer Vision" amazon.com/Practical-Mach… by @lak_gcp, @ryansgillard and myself.
• • •
Missing some Tweet in this thread? You can try to
force a refresh