
What is Accuracy in Machine Learning? Why shouldn't you use accuracy as a Performance Parameter? Is there a drawback? 🤔
A beginner-friendly explanation! 🧵👇
A beginner-friendly explanation! 🧵👇

A compiled version of the thread: diveintodata.in/accuracy-perfo…
☑️ What are Performance Metrics?
To study the effectiveness of a product or device in any field, we use performance metrics. Additionally, we can use performance metrics to measure how a machine learning model performs. The performance metrics provide the results in numbers.
To study the effectiveness of a product or device in any field, we use performance metrics. Additionally, we can use performance metrics to measure how a machine learning model performs. The performance metrics provide the results in numbers.
Therefore, it becomes pretty easy to understand and evaluate the performance of most machine learning models.
Let's say I tell you that a movie is 3 on 5. You can directly understand that the film is okay and not great.
Let's say I tell you that a movie is 3 on 5. You can directly understand that the film is okay and not great.
Therefore, when someone QUANTIFIES or puts a number value to the performance of a device, product or machine learning model, you can quickly understand whether or not it performs well. In other words, you can evaluate the product quickly by seeing a number score.
☑️ ACCURACY
Accuracy is a performance metric. It is calculated as the number of correct predictions divided by the total number of predictions.
See the formula below:-
Accuracy is a performance metric. It is calculated as the number of correct predictions divided by the total number of predictions.
See the formula below:-
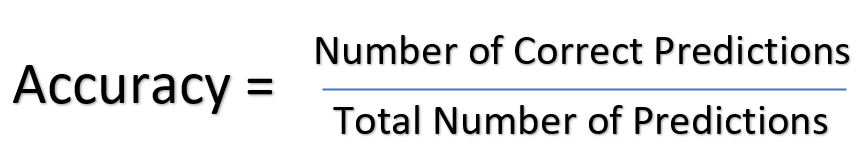
Let's say:-
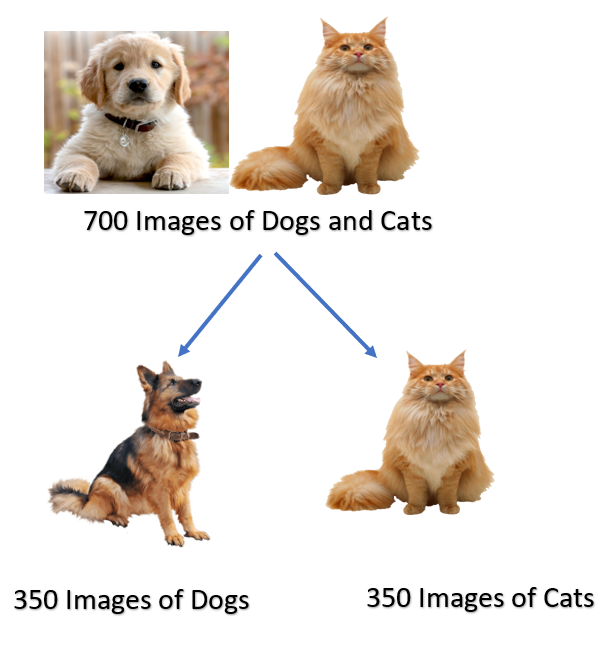
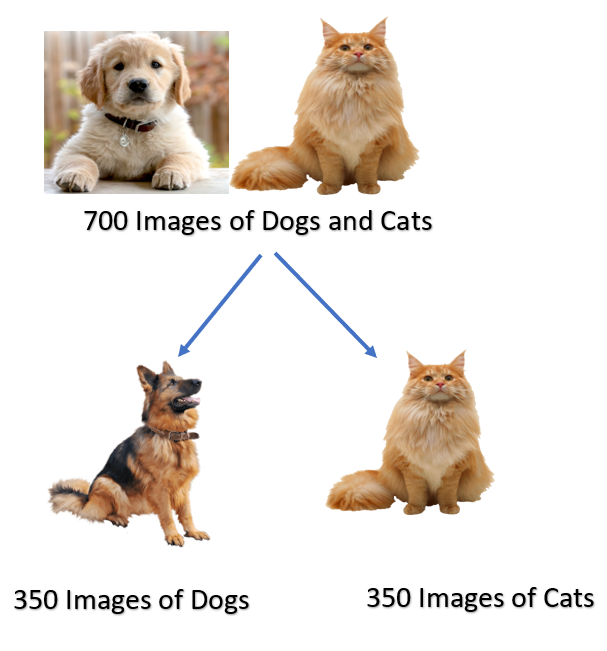
There are 700 images of dogs and cats.
Out of 700, 350 images are of dogs, and 350 images are of cats.
Out of 350 dog images, the model correctly identifies 320 images
Out of 350 cat images, the model correctly identifies 310 images
There are 700 images of dogs and cats.
Out of 700, 350 images are of dogs, and 350 images are of cats.
Out of 350 dog images, the model correctly identifies 320 images
Out of 350 cat images, the model correctly identifies 310 images
Therefore, the model correctly identifies 320 as dog images and 310 as cat images. Thus, the model correctly identifies 630 images.
Now, according to the formula, the accuracy of the model is 0.9 or 91%.
Now, according to the formula, the accuracy of the model is 0.9 or 91%.
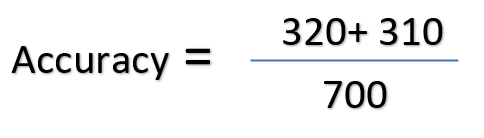
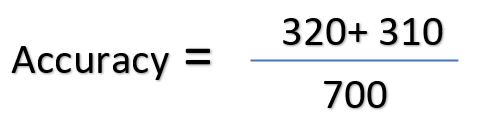
IMPORTANT OBSERVATION:-
The accuracy metric works best when the dataset is balanced. It is not reliable for an imbalanced dataset.
The accuracy metric works best when the dataset is balanced. It is not reliable for an imbalanced dataset.
☑️ Balanced vs Imbalanced Dataset
-> Balanced Dataset:-
The dataset is balanced when the target labels are nearly equal or equal in number in a classification problem. For example, out of the 700 images, if 350 are dog images and 350 are cat images, this is a balanced dataset.
-> Balanced Dataset:-
The dataset is balanced when the target labels are nearly equal or equal in number in a classification problem. For example, out of the 700 images, if 350 are dog images and 350 are cat images, this is a balanced dataset.
-> Imbalanced Dataset
We say the dataset is imbalanced when the target labels are not equal and incomparable in a classification problem.
In other words, when there are more number target labels of one class than the other.
We say the dataset is imbalanced when the target labels are not equal and incomparable in a classification problem.
In other words, when there are more number target labels of one class than the other.
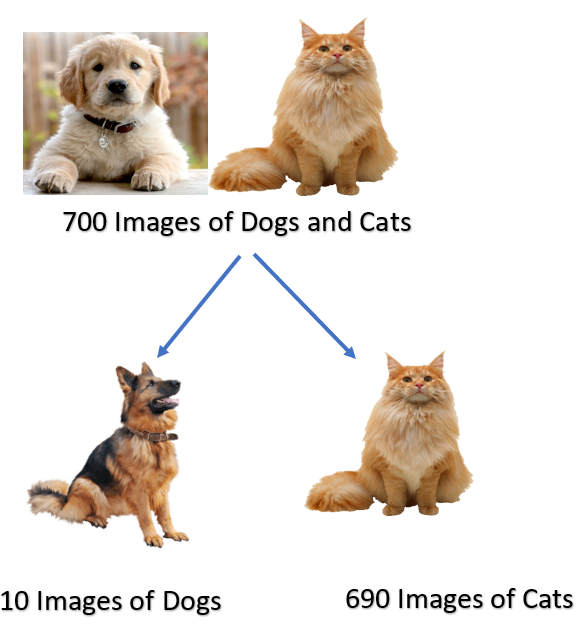
For example, out of 700 dogs and cats images, there are only 10 dog images and 690 cat images. This is an imbalanced dataset.
☑️ DRAWBACK - Why shouldn't you use accuracy as a performance metric?
Let us take the same example for the imbalanced dataset we took above. In which there are 700 images of dogs and cats. From the 700 images, there are 10 photos of dogs and 690 photos of cats.
Let us take the same example for the imbalanced dataset we took above. In which there are 700 images of dogs and cats. From the 700 images, there are 10 photos of dogs and 690 photos of cats.

Assume that our model correctly identifies 630 cat images. But, it fails to identify any dog images. Let us calculate the accuracy for this scenario.
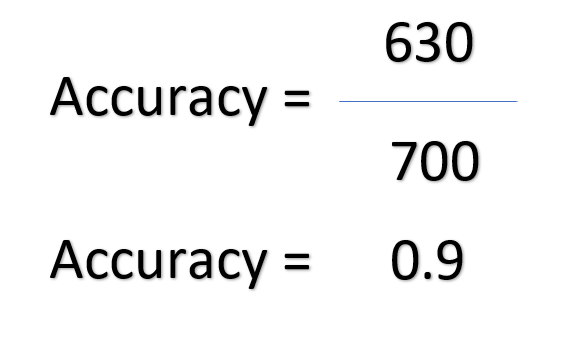
Wow! We still got the same accuracy. It is 90%.
But do you think it should be 90% when our model could not identify any dog image correctly? No, right?
Therefore, when the dataset is imbalanced or skewed, we must not use accuracy to determine our model's performance.
But do you think it should be 90% when our model could not identify any dog image correctly? No, right?
Therefore, when the dataset is imbalanced or skewed, we must not use accuracy to determine our model's performance.
• • •
Missing some Tweet in this thread? You can try to
force a refresh





