
Big tech teams win because they have the best ML Ops. These teams
- Deploy models at 10x speed
- Spend more time on data science, less on engineering
- Reuse rather than rebuild features
How do they do it? An architecture called a Feature Store. Here's how it works
🧵 1/n
- Deploy models at 10x speed
- Spend more time on data science, less on engineering
- Reuse rather than rebuild features
How do they do it? An architecture called a Feature Store. Here's how it works
🧵 1/n

In almost every ML/data science project, your team will spend 90-95% of the time building data cleaning scripts and pipelines
Data scientists rarely get to put their skills to work because they spend most of their time outside of modeling
Data scientists rarely get to put their skills to work because they spend most of their time outside of modeling

Enter: The Feature Store
This specialized architecture has:
- Registry to lookup/reuse previously built features
- Feature lineages
- Batch+stream transformation pipelines
- Offline store for historical lookups (training)
- Online store for low-latency lookups (live inferences)
This specialized architecture has:
- Registry to lookup/reuse previously built features
- Feature lineages
- Batch+stream transformation pipelines
- Offline store for historical lookups (training)
- Online store for low-latency lookups (live inferences)

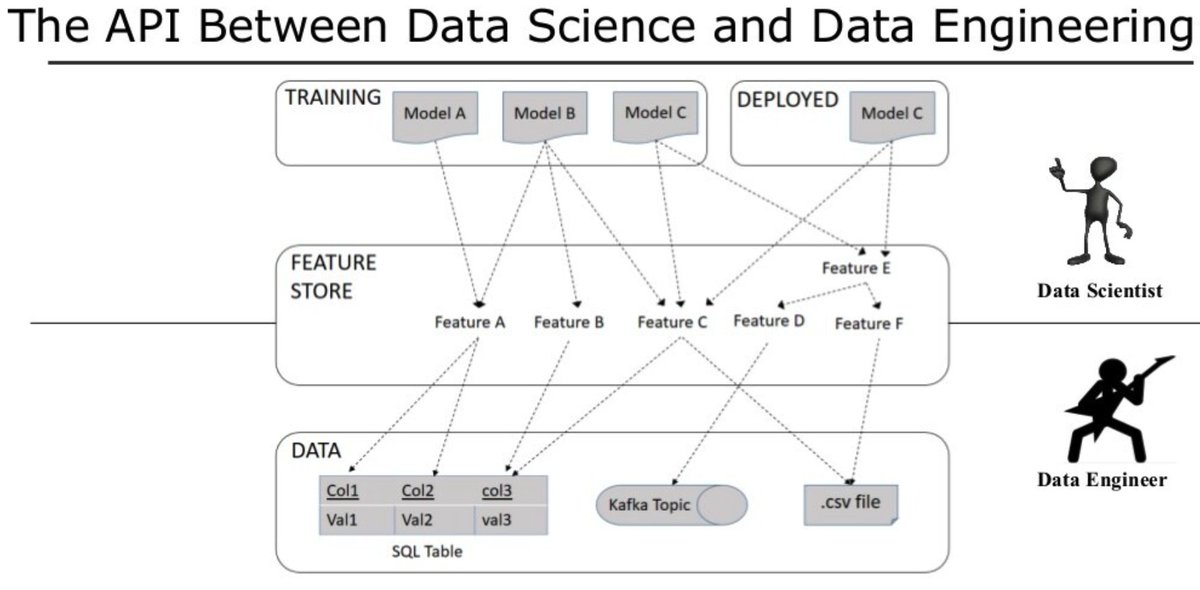
You can think of the feature store as a "Feature API" made just for data scientists.
Anyone with access can view, pull, and contribute features for their own models. Over time, the feature store will eliminate countless hours of redundant feature engineering work
Anyone with access can view, pull, and contribute features for their own models. Over time, the feature store will eliminate countless hours of redundant feature engineering work
MLOps done right can supercharge your company
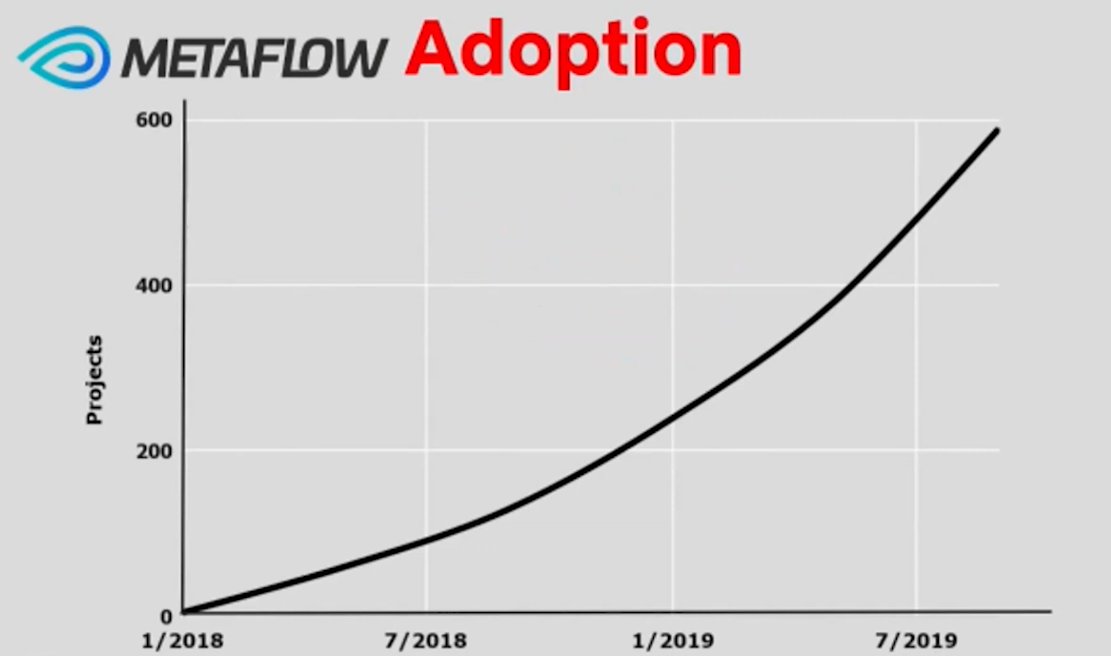
For example, the @NetflixEng team uses a ML architecture with FS-like capabilities called Metaflow. With Metaflow, data scientists can push models to production in 1 week or less on average
They have over 600+ models deployed today
For example, the @NetflixEng team uses a ML architecture with FS-like capabilities called Metaflow. With Metaflow, data scientists can push models to production in 1 week or less on average
They have over 600+ models deployed today

The feature store has 4 basic functionalities:
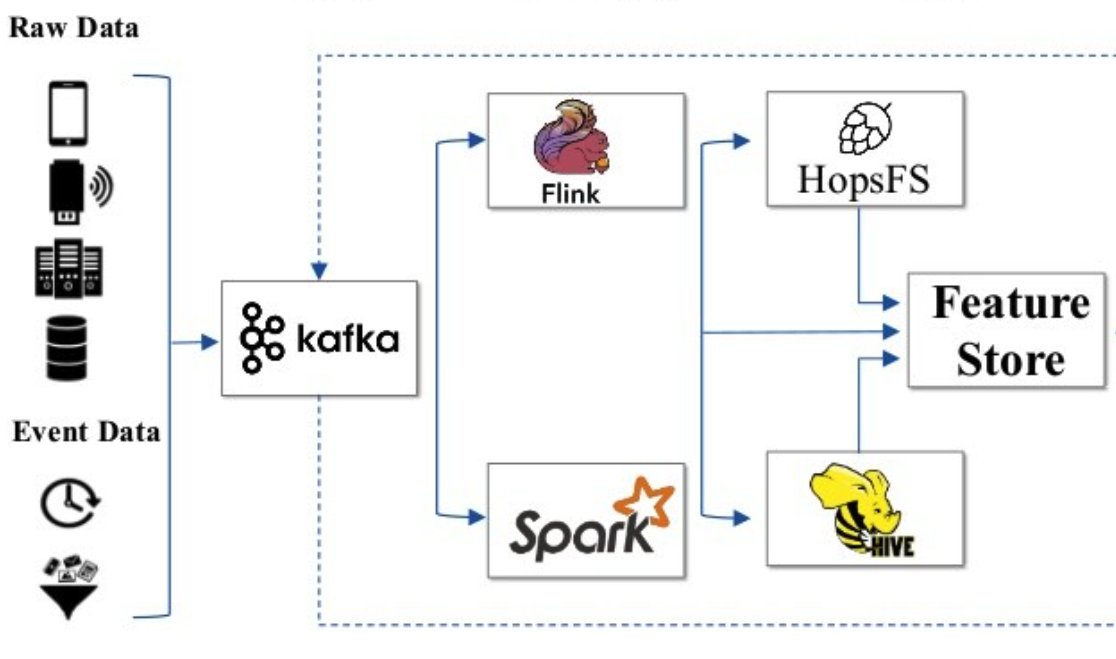
1. Feature Transform
This is the main tool for writing and saving features to your feature store. Typically, this takes the form of a job or service orchestration tool such as @ApacheAirflow
Basically: Read, Transform, Write
1. Feature Transform
This is the main tool for writing and saving features to your feature store. Typically, this takes the form of a job or service orchestration tool such as @ApacheAirflow
Basically: Read, Transform, Write
2. Feature Discovery
This is the hardest part to get right. If you want data scientists to reuse features, you need an intuitive UI that lets them search for them.
@databricks's feature registry has some basic components. But, there's ample room for opportunity for improvement
This is the hardest part to get right. If you want data scientists to reuse features, you need an intuitive UI that lets them search for them.
@databricks's feature registry has some basic components. But, there's ample room for opportunity for improvement

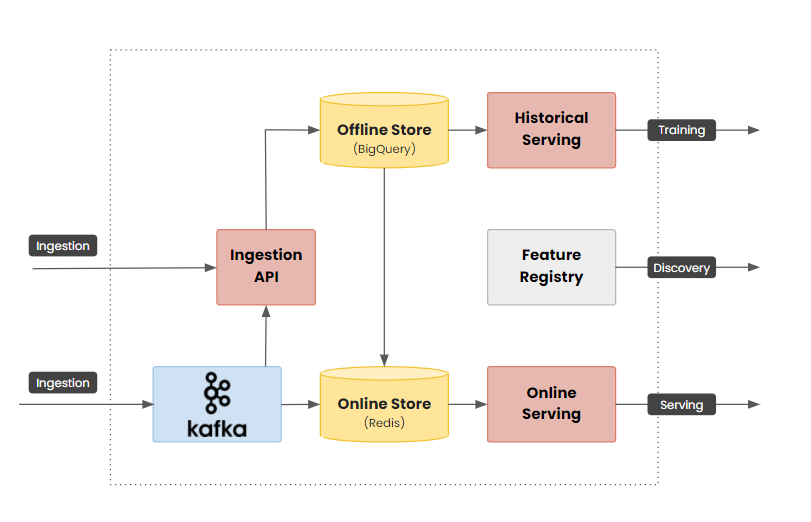
3. Feature Serving
The Offline Store is a historical data store feature discovery and model training
The idea behind the Online Store is rather than running feature transforms during inference (slow), you can pre-compute them and cache them in the online store for quick lookups
The Offline Store is a historical data store feature discovery and model training
The idea behind the Online Store is rather than running feature transforms during inference (slow), you can pre-compute them and cache them in the online store for quick lookups
Want to use a feature store yourself? You're in luck! There's a few open source options out there
1. @feast_dev is a fantastic open source feature store that plays nicely with both GCP and AWS
1. @feast_dev is a fantastic open source feature store that plays nicely with both GCP and AWS
https://twitter.com/willpienaar/status/1445406336452374544?s=20
2. @logicalclocks has an end-to-end ML pipeline with a feature store included called @hopsworks. Also open source
https://twitter.com/hopsworks/status/1362069397423206400?s=20
Here are what some (closed source) big players use:
@UberEng's Michaelangelo has an end-to-end feature engineering -> model training -> model deployment pipeline. Largely built around Spark's MLlib
@WixEng also has a nifty architecture that stores feature data with protobufs
@UberEng's Michaelangelo has an end-to-end feature engineering -> model training -> model deployment pipeline. Largely built around Spark's MLlib
@WixEng also has a nifty architecture that stores feature data with protobufs
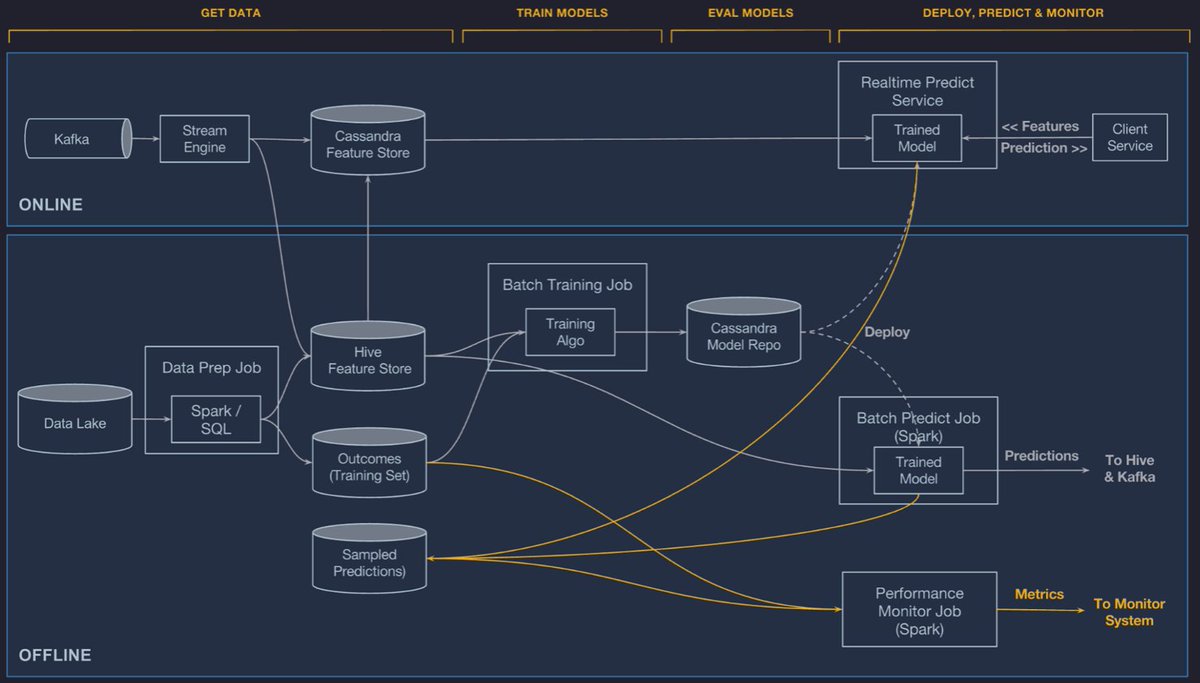
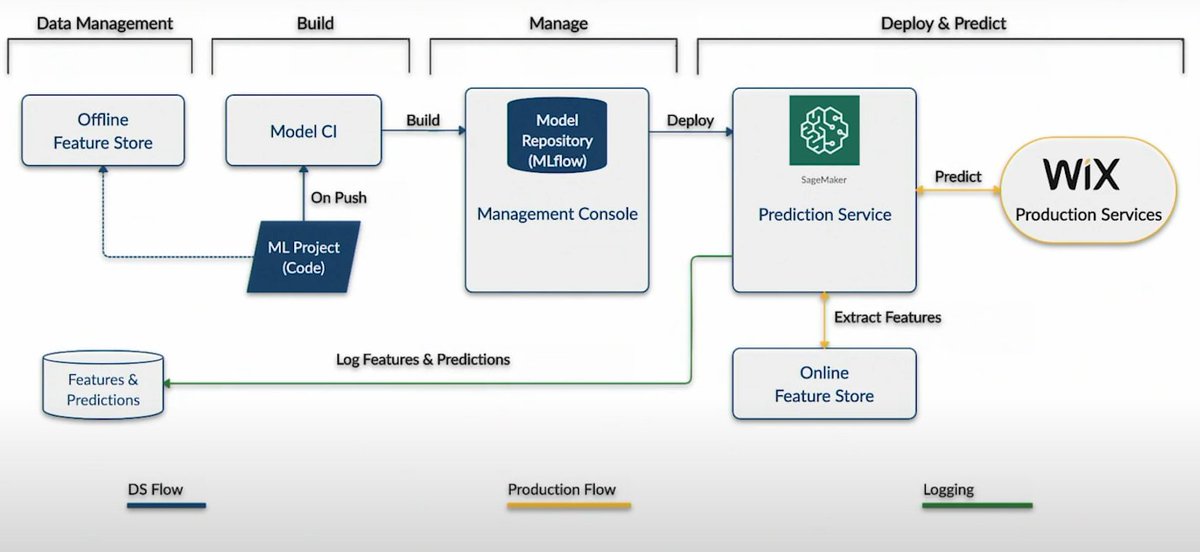
Want to buy instead of building your own? Here are some cool startups bringing feature stores to the market
1. @TectonAI - Staffed by some of the original Feast developers
2. @stream_sql - Founded by the minds behind Michaelangelo
3. @databricks - Feature store just left beta
1. @TectonAI - Staffed by some of the original Feast developers
2. @stream_sql - Founded by the minds behind Michaelangelo
3. @databricks - Feature store just left beta
And that's it :)
If you enjoyed it, I post threads like this on the regular. Also on topics ranging from AI for UI, fintech, crypto(skepticism), and data science
If you enjoyed it, I post threads like this on the regular. Also on topics ranging from AI for UI, fintech, crypto(skepticism), and data science
https://twitter.com/AlexReibman/status/1416193675957215234?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh




