
The #NobelPrize in economics was just awarded to 3 top economists. #EconTwitter seems to be over it, but the data science/ML community is totally missing out!
Here's why Data Scientists should start paying attention and what they can take away 🧵
Here's why Data Scientists should start paying attention and what they can take away 🧵
The prize was awarded to David Card, @metrics52, and Guido Imbens for their monumental contributions to statistical methodology and causal inference.
They used and developed strategies that were a true paradigm shift bridging the gap between data and causation in economics
They used and developed strategies that were a true paradigm shift bridging the gap between data and causation in economics

One part of the prize went to David Card from UC Berkeley.
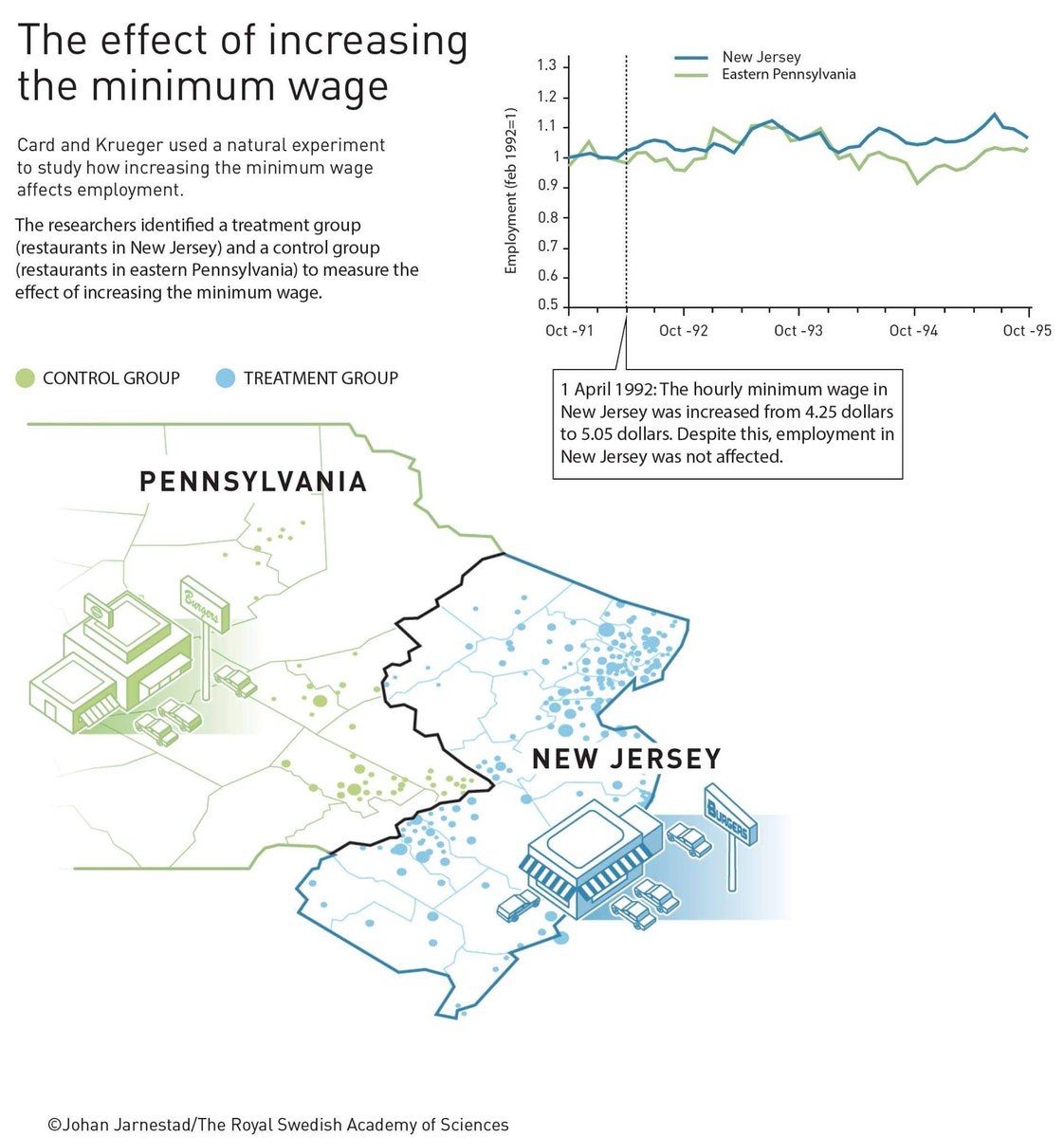
Card is most well-known for his famous minimum wage study that paradoxically revealed that an increase in the minimum wage did *not* reduce employment. How?
The study applied a strategy called Difference in Differences
Card is most well-known for his famous minimum wage study that paradoxically revealed that an increase in the minimum wage did *not* reduce employment. How?
The study applied a strategy called Difference in Differences

Difference in Differences (DiD) is an extremely powerful method that any data scientist should know.
DiD compares outcomes across *groups* and *times*, not just between treatment and control groups (see A/B tests)
i.e. How can we tell the employment trend wasn't just a fluke?
DiD compares outcomes across *groups* and *times*, not just between treatment and control groups (see A/B tests)
i.e. How can we tell the employment trend wasn't just a fluke?

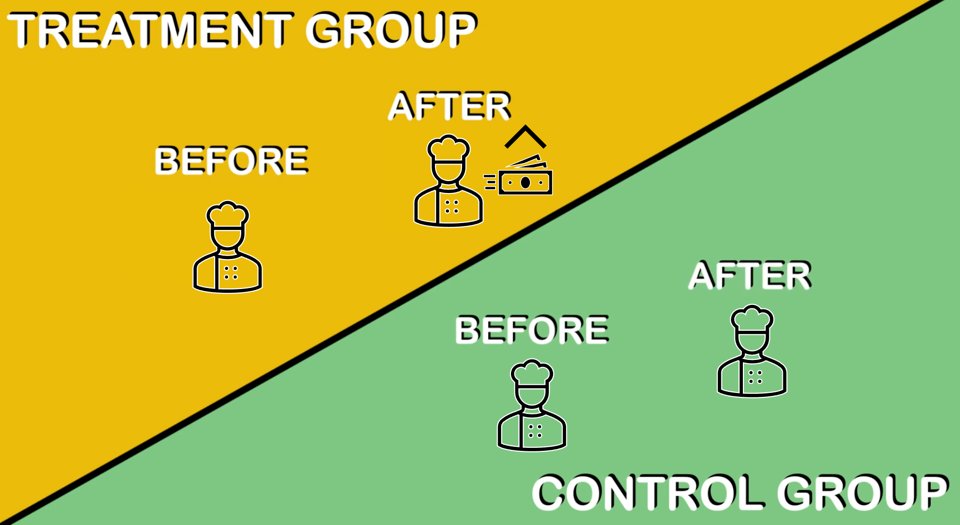
Card's experiment compared NJ and PA, two similar locales. NJ had a minimum wage increase but PA did not. This made 2 groups:
NJ: Treatment group (subject to min wage incr)
PA: Control group (no change in wage)
Then, they compared both group trends before and after
NJ: Treatment group (subject to min wage incr)
PA: Control group (no change in wage)
Then, they compared both group trends before and after
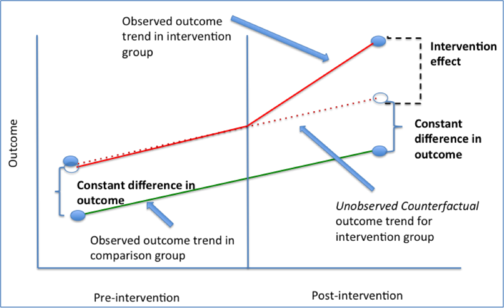
DiD assumes that both groups are subject to the same variables except for the treatment (min wage incr). We call these "Parallel Trends"
Then, we compare the difference between the groups after the treatment. The difference between the trends is called the Treatment Effect
Then, we compare the difference between the groups after the treatment. The difference between the trends is called the Treatment Effect
We call studies like this "quasi-experimental"
Although we measure the effect of a particular intervention against a control group, we don't use randomization to select the control group. (Card chose PA as a control)
If assignments are random, we call it a "natural experiment"
Although we measure the effect of a particular intervention against a control group, we don't use randomization to select the control group. (Card chose PA as a control)
If assignments are random, we call it a "natural experiment"
DiD seems like a pretty obvious way to run experiments. But for the longest time (pre-1990's) very few people used such thinking!
The results weren't so much as important as this novel use of rigorous experimental design.
The results weren't so much as important as this novel use of rigorous experimental design.
Side note: If you're interested in diving deeper into minimum wage, I highly recommend checking out @NeumarkDN's analysis on the subject. Much more nuance in this paper nber.org/papers/w18681
The other 2 recipients, Josh Angrist and Guido Imbens were chosen for their groundbreaking work on Instrumental Variables and, randomized trials, and natural experiments in economics.
But this thread is already a bit too long... Let me know if you want to see that breakdown too
But this thread is already a bit too long... Let me know if you want to see that breakdown too
And that's it (for now).
I make threads like this on the regular, covering topics from AI/ML, statistics, tech business breakdowns, and more.
As a quasi-experiment, I'll see how engagement with this thread compares with others I've made :)
I make threads like this on the regular, covering topics from AI/ML, statistics, tech business breakdowns, and more.
As a quasi-experiment, I'll see how engagement with this thread compares with others I've made :)
https://twitter.com/AlexReibman/status/1445835846884610052?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh





