Note to self: don't use default matplotlib colormaps to make digital art🤦♂️😅
New samples from my 'color-quantized VQGAN' are looking great!
Here's "𝑨𝒄𝒄𝒐𝒓𝒅𝒊𝒏𝒈 𝒕𝒐 𝑾𝒊𝒕𝒕𝒈𝒆𝒏𝒔𝒕𝒆𝒊𝒏, 𝒂 𝒑𝒊𝒄𝒕𝒖𝒓𝒆 𝒊𝒔 𝒂 𝒎𝒐𝒅𝒆𝒍 𝒐𝒇 𝒓𝒆𝒂𝒍𝒊𝒕𝒚"
#clip #AIart
New samples from my 'color-quantized VQGAN' are looking great!
Here's "𝑨𝒄𝒄𝒐𝒓𝒅𝒊𝒏𝒈 𝒕𝒐 𝑾𝒊𝒕𝒕𝒈𝒆𝒏𝒔𝒕𝒆𝒊𝒏, 𝒂 𝒑𝒊𝒄𝒕𝒖𝒓𝒆 𝒊𝒔 𝒂 𝒎𝒐𝒅𝒆𝒍 𝒐𝒇 𝒓𝒆𝒂𝒍𝒊𝒕𝒚"
#clip #AIart
https://twitter.com/xsteenbrugge/status/1445327569847521281


"𝒎𝒚 𝒉𝒆𝒂𝒅 𝒊𝒔 𝒇𝒖𝒍𝒍 𝒐𝒇 𝒏𝒐𝒊𝒔𝒆"



"𝑵𝒊𝒈𝒉𝒕𝒎𝒂𝒓𝒆"

"𝑰𝒏𝒄𝒆𝒑𝒕𝒊𝒐𝒏"



"𝑮𝒐𝒍𝒅𝒆𝒏 𝒇𝒂𝒄𝒆𝒔"


For the collectors: I've minted some of these on my HEC: hicetnunc.xyz/xander
For the techies:
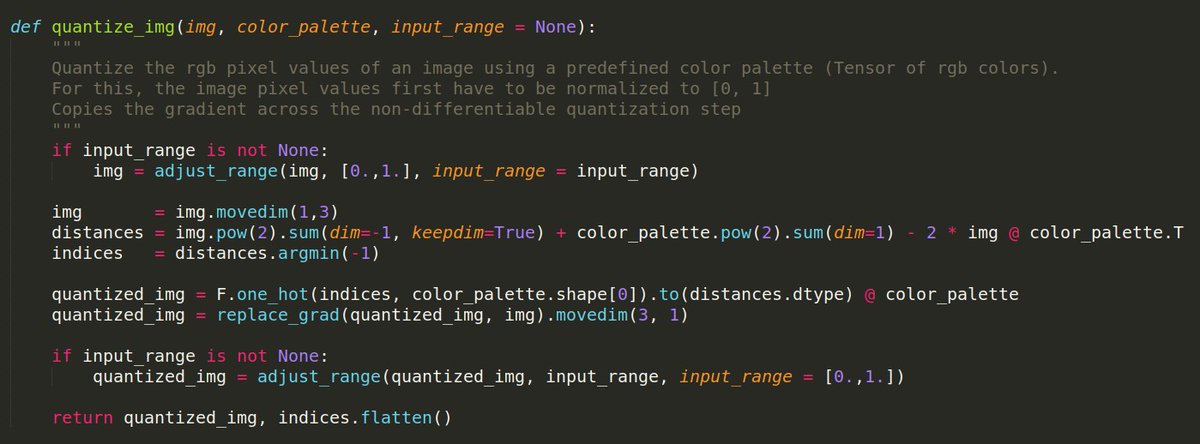
Turns out sending gradients straight through this rgb-quantization is not great for stability, so I'm also minimizing mean(quant_distances) to keep raw img close to quantized one!
For the techies:
Turns out sending gradients straight through this rgb-quantization is not great for stability, so I'm also minimizing mean(quant_distances) to keep raw img close to quantized one!


• • •
Missing some Tweet in this thread? You can try to
force a refresh