Niiice! Hooking this up to CLIP as soon as the weights are released 🤞🤞😋
https://twitter.com/ak92501/status/1445872262771478529
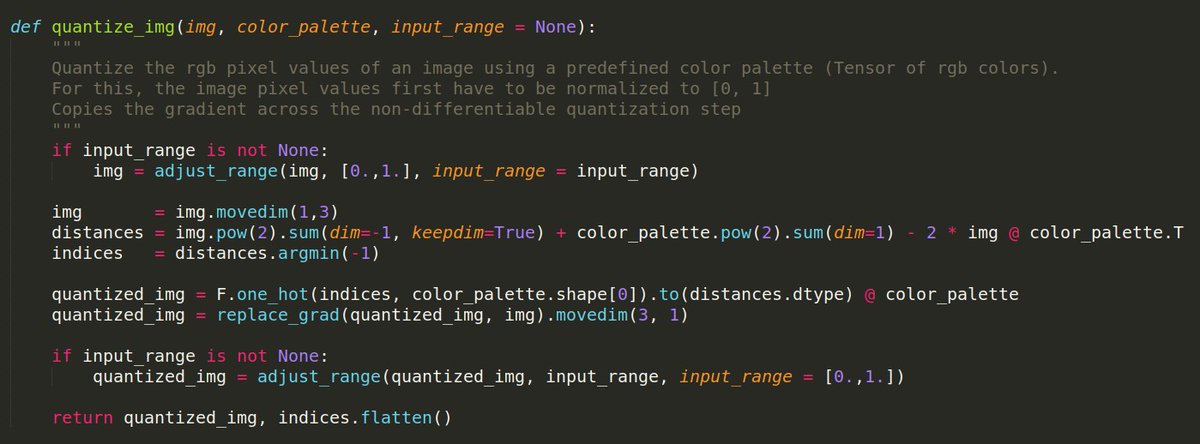
TLDR:
1. Replaces the CNN encoder and decoder with a vision transformer ‘ViT-VQGAN’, leading to significantly better speed-quality tradeoffs compared to CNN-VQGAN
1. Replaces the CNN encoder and decoder with a vision transformer ‘ViT-VQGAN’, leading to significantly better speed-quality tradeoffs compared to CNN-VQGAN
2. Vanilla VQVAE often learns rarily used / “dead” codebook vectors leading to wasted capacity. Here, they add a linear projection of the code vectors into a lower dimensional “lookup” space. This factorization of embedding / lookup consistently improves reconstruction quality.
3. Encoded latents + codebook vectors are L2 normalized, placing all of them on the unit sphere where the Euclidean distance between latent and codebook vector corresponds to their cosine similarity, further improving training stability and reconstruction quality.
• • •
Missing some Tweet in this thread? You can try to
force a refresh