
Webinar on @ipums data @popdatatech @nhgis @ipumsi and I am probably forgetting their other accounts - human population data… 




… geographic data @dcvanriper …




#rstats backbone infrastructure of library(ipumsr)

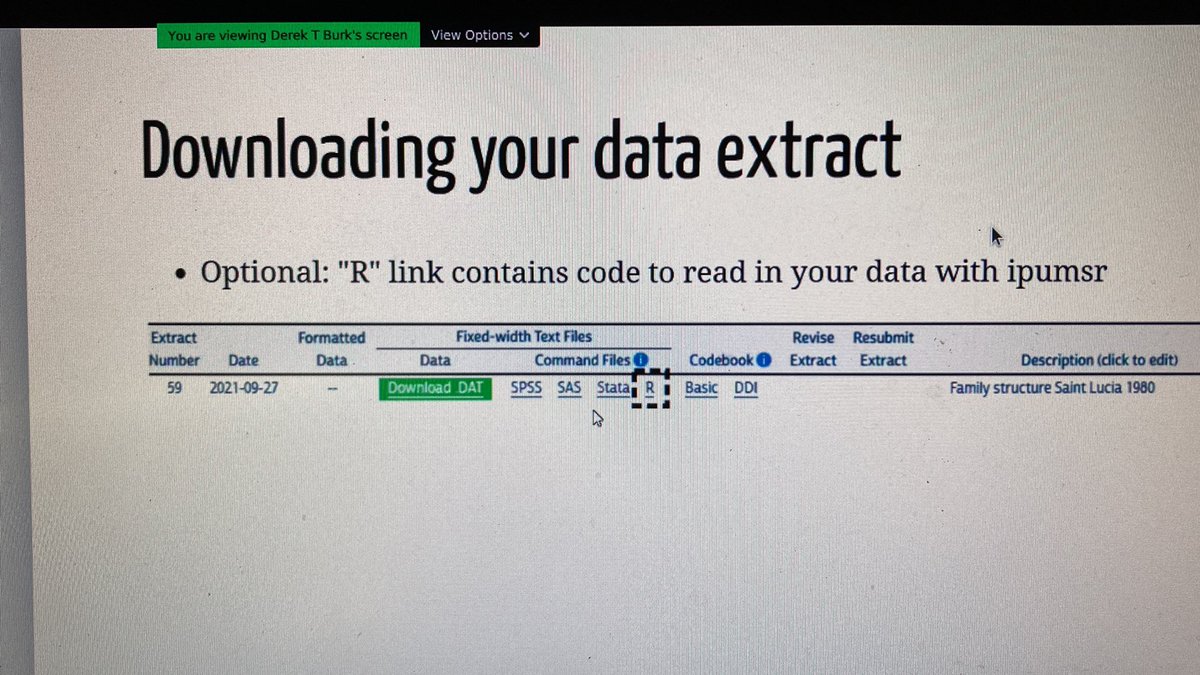

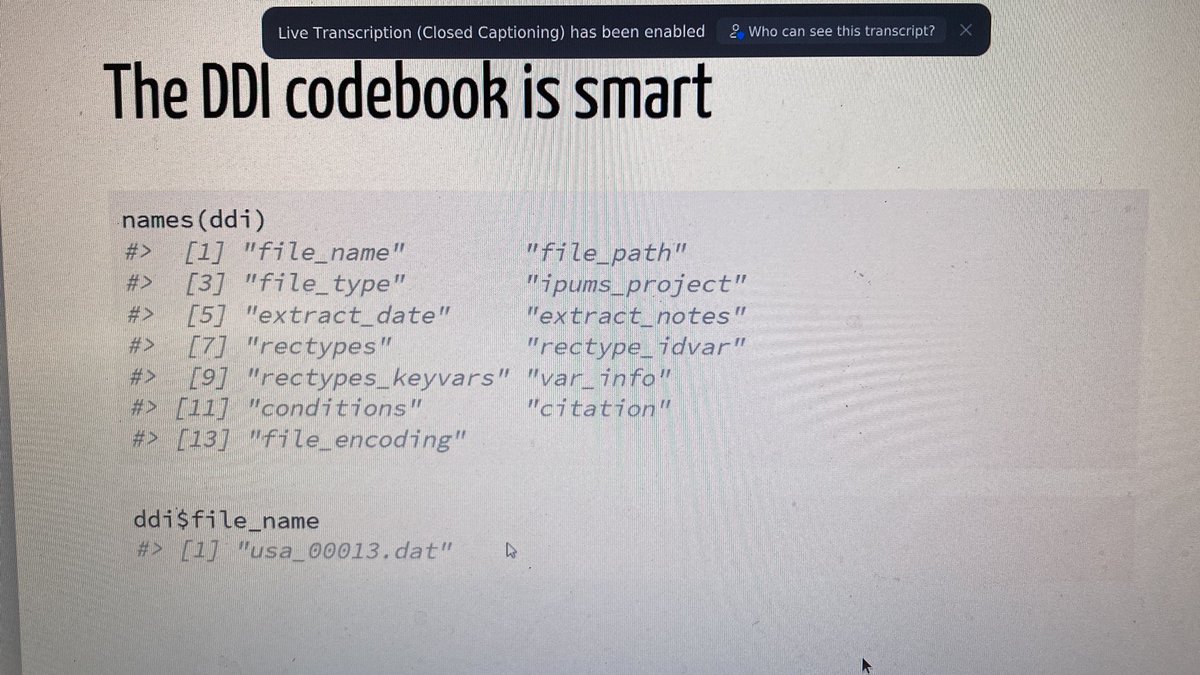
Some internal structure of the DDI codebook objects in ipumsr

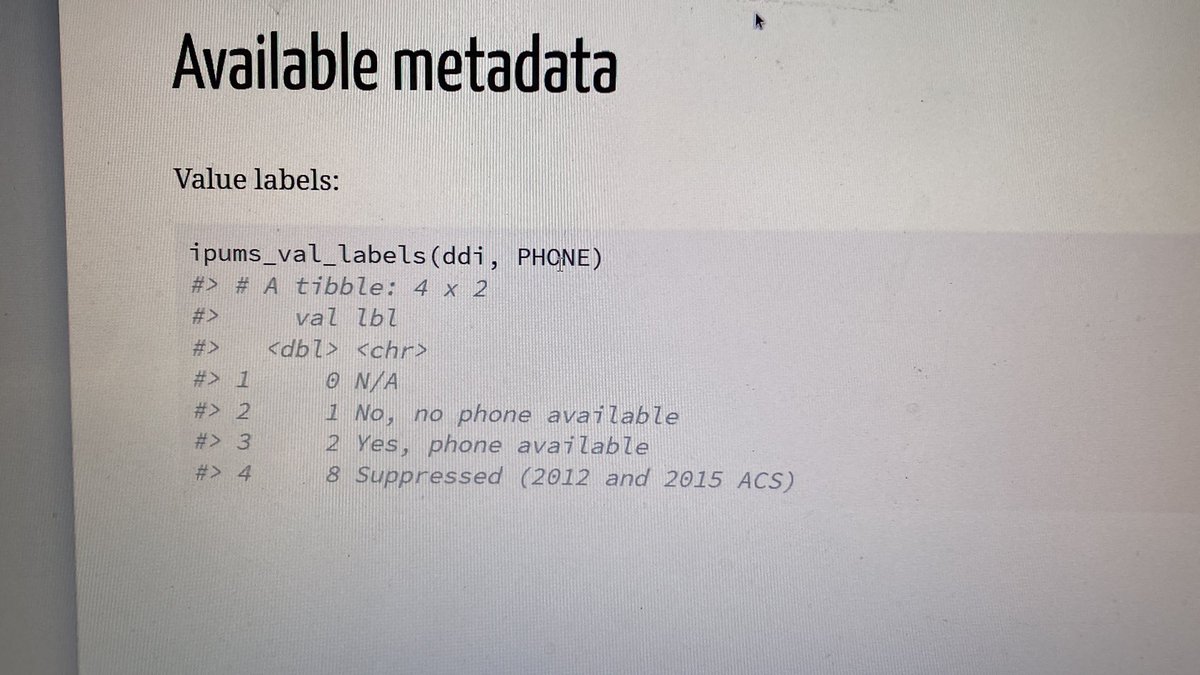
Variable names and labels and value labels are available

Your daily reminder that #rstats factor variables suck big time compared to Stata and SAS
I am not crying, you are crying
I am not crying, you are crying


Helper functions: replace missing values. These suck in #rstats compared to Stata and SAS, too: in the latter, you can have extended missing values .a:.z, and they all can be labelled with the reasons it is missing (not in pop, refused, not applicable, etc.)


Another helper: recode and label new values. Very helpful for hierarchical classification codes where you can divide by 10 or 100 to obtain the higher level / fewer digits code. Labels are copied from the lowest numbered original category - would need extra work down the line


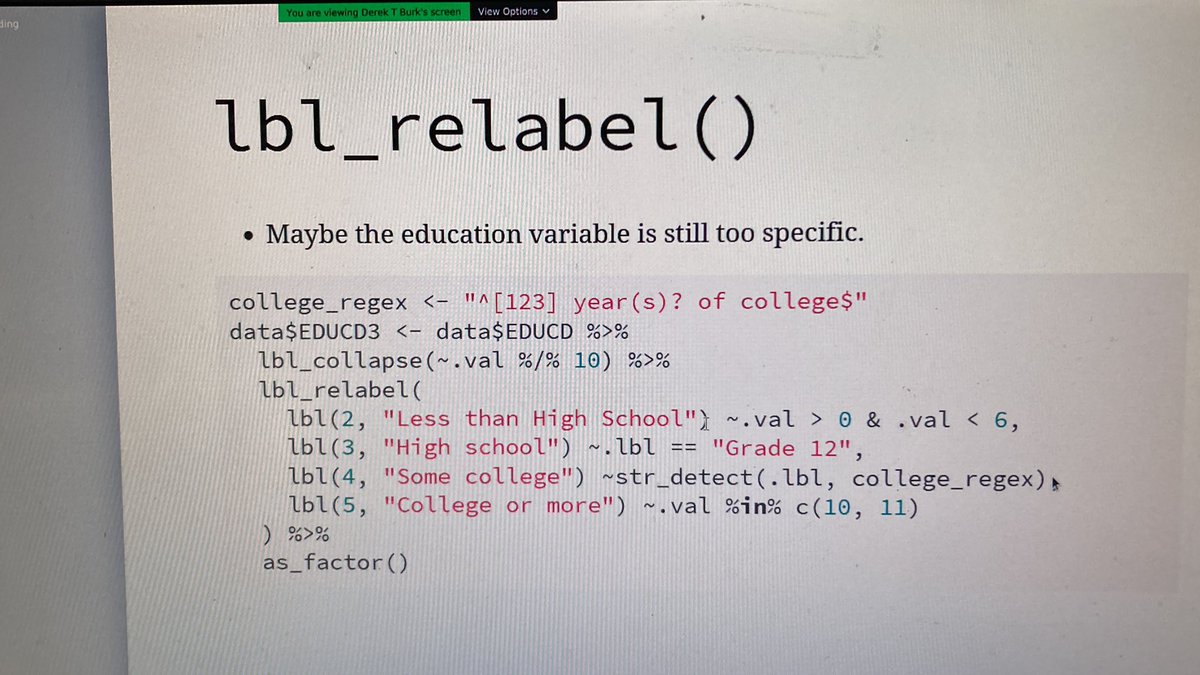
A more generic function for that is relabel.


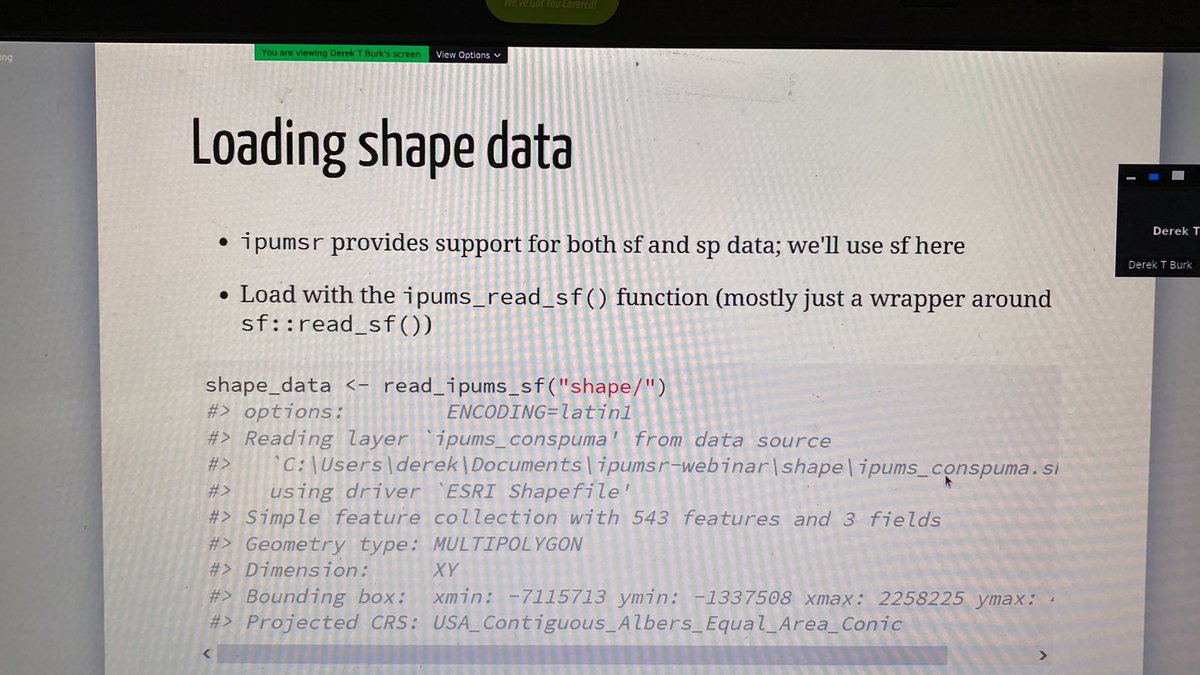

There are helper functions for the geo data management

Coming soon - @popdatatech API - ask to beta test. Sharing extract definitions is important for reproducibility!


Ceci n’est pas une pipe



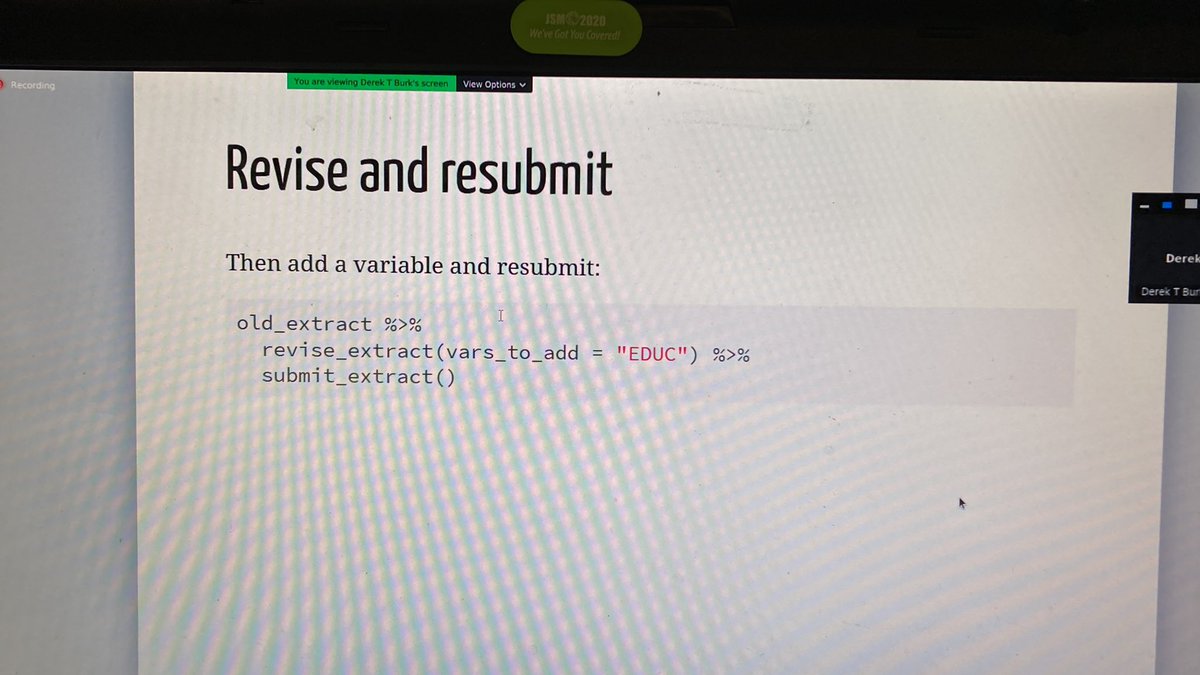
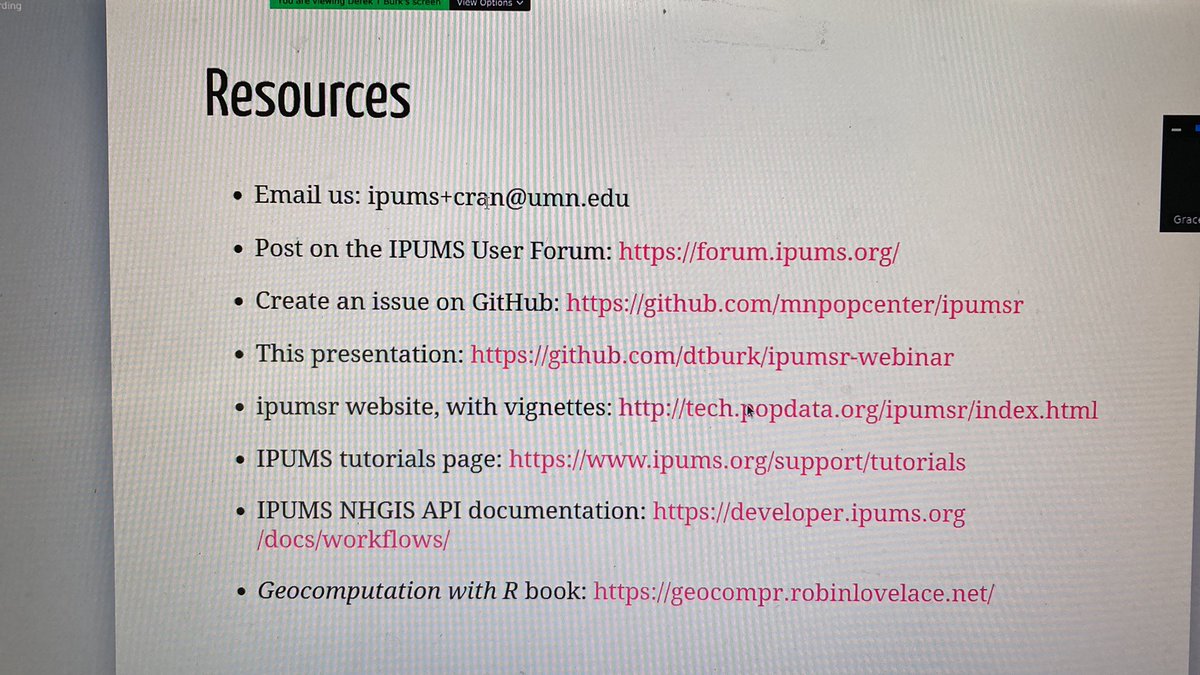
Everything you need to know about @ipums data and this presentation
@threadreaderapp unroll
All others: please retweet this last entry rather than the first ;)
All others: please retweet this last entry rather than the first ;)
• • •
Missing some Tweet in this thread? You can try to
force a refresh



