
Large language models (LLMs) often make mistakes that are difficult to correct.
We study the problem of quickly editing these models:
Paper: arxiv.org/abs/2110.11309
Code: github.com/eric-mitchell/…
w/ @_eric_mitchell_, C. Lin, @ABosselut, @chrmanning
thread 🧵👇
We study the problem of quickly editing these models:
Paper: arxiv.org/abs/2110.11309
Code: github.com/eric-mitchell/…
w/ @_eric_mitchell_, C. Lin, @ABosselut, @chrmanning
thread 🧵👇
We assume a pre-trained model & a dataset that covers many possible model edits
Then, we meta-train a model editor that predicts a model update that:
- edits the model
- otherwise keeps the model behavior the same
(2/4)
Then, we meta-train a model editor that predicts a model update that:
- edits the model
- otherwise keeps the model behavior the same
(2/4)

You can train model editors for massive models (e.g. GPT-J, T5-11B) in <1 day on a single GPU.
Edits with the resulting model editor are extremely fast, with edit success rate of 80-90%.
(3/4)
Edits with the resulting model editor are extremely fast, with edit success rate of 80-90%.
(3/4)
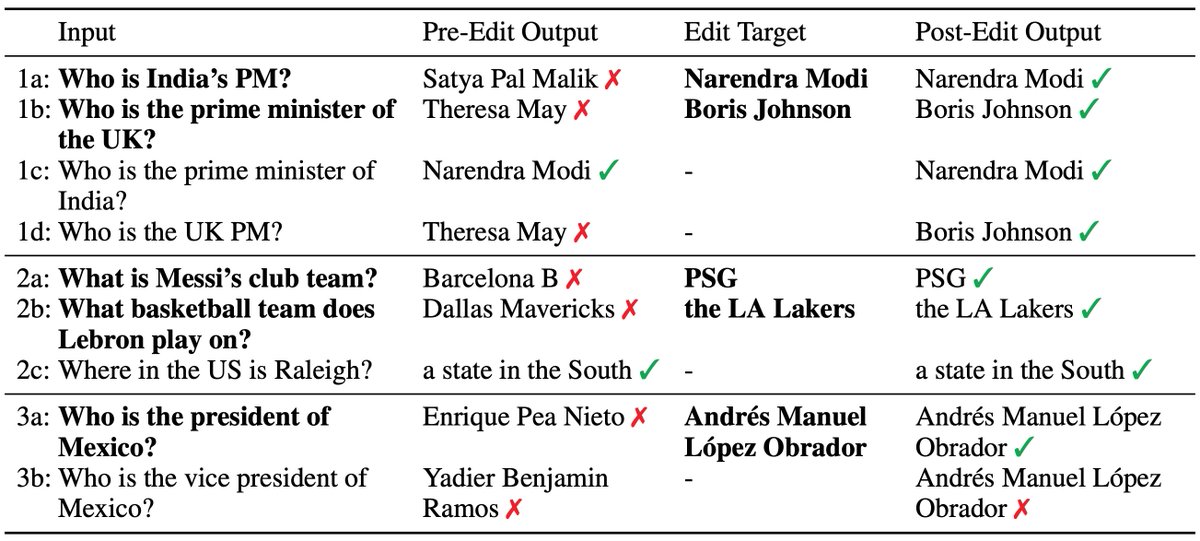

While I think that MEND makes significant progress on the problem of model editing, still lots of open challenges including:
- deeper edit generalization
- making many model edits
It was also a lot of fun to collaborate with @stanfordnlp!
(4/4)
- deeper edit generalization
- making many model edits
It was also a lot of fun to collaborate with @stanfordnlp!
(4/4)
• • •
Missing some Tweet in this thread? You can try to
force a refresh














