
Real world data vs a randomized controlled trial for comparative effectiveness research.
If you change analytical methods of the real world data, can you generate any conclusion that you want?
Yes!
The randomized controlled trial remains the gold standard.
@ASTRO_org #ASTRO21
If you change analytical methods of the real world data, can you generate any conclusion that you want?
Yes!
The randomized controlled trial remains the gold standard.
@ASTRO_org #ASTRO21

Comparative effectiveness research evaluates the efficacy of one treatment relative to another, treatment A vs treatment B.
For example:
Radiation vs surgery for prostate cancer
Ivermectin vs placebo for COVID
Streptomycin for TB (1st RCT!, ncbi.nlm.nih.gov/pmc/articles/P…)
For example:
Radiation vs surgery for prostate cancer
Ivermectin vs placebo for COVID
Streptomycin for TB (1st RCT!, ncbi.nlm.nih.gov/pmc/articles/P…)
Since the 1970s, hospital databases have started to grow to allow for "real world data" analysis, using rudimentary methods like univariate and multivariate analysis
Since 2000s, the creation of large national databases allows for more complex statistics, eg, PSM.
Since 2000s, the creation of large national databases allows for more complex statistics, eg, PSM.

The premise of methods like PSM is that they "recapitulate a randomized controlled trial."
This is a misconception.
This is a misconception.

PSM helps to mitigate some selection bias, but it will never get you to the level of a randomized controlled trial.
@ASTRO_org @DrSpratticus
redjournal.org/article/S0360-…
@ASTRO_org @DrSpratticus
redjournal.org/article/S0360-…




You wind up with 1000s of retrospective "real world data" comparative effectiveness studies that have no concordance with the RCT.
@DrSpratticus @DrPayalSoni @holly7holly @rtdess
ascopubs.org/doi/full/10.12…
@DrSpratticus @DrPayalSoni @holly7holly @rtdess
ascopubs.org/doi/full/10.12…

Nonetheless, so many physicians still think we can keep using retrospective comparative effectiveness research in place of randomized trials.
https://twitter.com/DrSpratticus/status/1452336550394703884
A randomized controlled trial allows for a few important quality control measures:
(1) it sets a start time, t = 0.
(2) it controls for known confounders.
(3) it controls for unknown confounders.
(1) it sets a start time, t = 0.
(2) it controls for known confounders.
(3) it controls for unknown confounders.
(1) t=0.
Without randomization, you introduce "immortal time," where patients by definition cannot have an event.
bmj.com/content/340/bm…
pubmed.ncbi.nlm.nih.gov/22342097/
@HenryParkMD
So, you need to adjust for this, with something like left truncation or landmark analysis.
Without randomization, you introduce "immortal time," where patients by definition cannot have an event.
bmj.com/content/340/bm…
pubmed.ncbi.nlm.nih.gov/22342097/
@HenryParkMD
So, you need to adjust for this, with something like left truncation or landmark analysis.

(2) controlling for known confounders.
You might adjust for race, age, gender, etc but there is no rule that says you have to control any/all of them.
So, there are combinations of covariates that may be in a model. This is "vibration of effects."
ncbi.nlm.nih.gov/pmc/articles/P…
You might adjust for race, age, gender, etc but there is no rule that says you have to control any/all of them.
So, there are combinations of covariates that may be in a model. This is "vibration of effects."
ncbi.nlm.nih.gov/pmc/articles/P…
(3) controlling for unknown confounders.
SEER/NCDB have none of these:
mutations
patient support from family/friends
which physicians patient spoke to before getting tx
performance status
There are millions of other confounders that are auto equalized when you randomize.
SEER/NCDB have none of these:
mutations
patient support from family/friends
which physicians patient spoke to before getting tx
performance status
There are millions of other confounders that are auto equalized when you randomize.
So, we chose a common question under investigation in all of oncology:
"For newly diagnosed M1 patients, does definitive treatment of the primary improve survival?"
We chose breast, prostate, lung, since there are published RCTs for these sites.
"For newly diagnosed M1 patients, does definitive treatment of the primary improve survival?"
We chose breast, prostate, lung, since there are published RCTs for these sites.
Here are 1000s of studies plotted for prostate cancer.
No PSM
No mitigation for immortal time bias.
Each dot is a "publishable" study.
All of the studies have an HR << 1, with p value << 0.05 (we had to log scale them bc the p values were so small)
No PSM
No mitigation for immortal time bias.
Each dot is a "publishable" study.
All of the studies have an HR << 1, with p value << 0.05 (we had to log scale them bc the p values were so small)

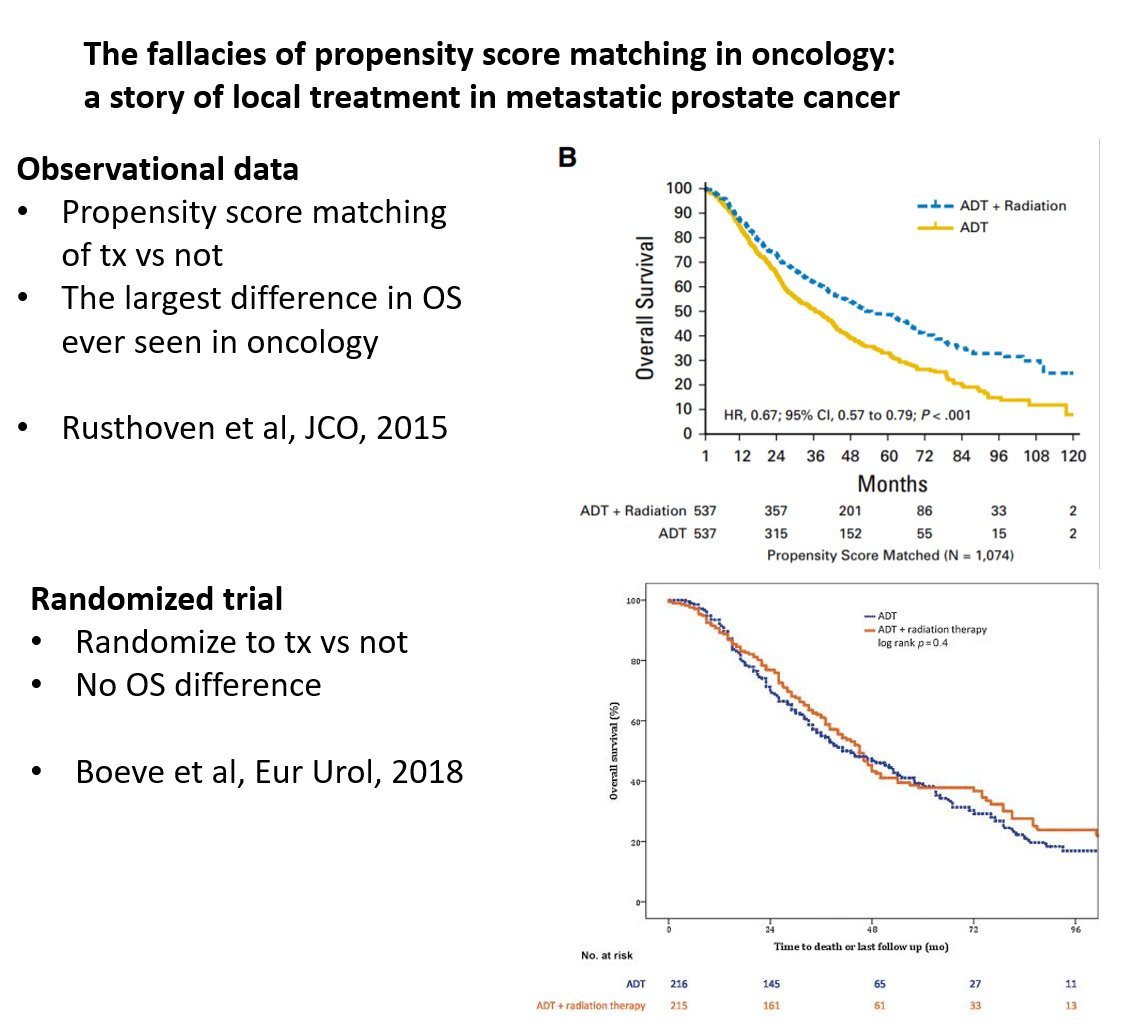
Here is an example of a published study, with PSM.
HR still << 1, favoring treating the prostate.
pubmed.ncbi.nlm.nih.gov/27325855/
But the RCT didn't agree.
@DrSpratticus
HR still << 1, favoring treating the prostate.
pubmed.ncbi.nlm.nih.gov/27325855/
But the RCT didn't agree.
@DrSpratticus
If you start to apply more methods, then the HR starts to approach 1, and p values become > 0.05.
With our methods, we can generate any answer you want.
A is better than B (HR < 1, p < 0.05)
B is better than A (HR > 1, p < 0.05)
A = B (p > 0.05)
With our methods, we can generate any answer you want.
A is better than B (HR < 1, p < 0.05)
B is better than A (HR > 1, p < 0.05)
A = B (p > 0.05)

Here is an example with extreme HRs >> 1 and p <<0.005, for breast cancer.
Any of these studies would have suggested that local therapy for M1 breast cancer results in worse survival.
Any of these studies would have suggested that local therapy for M1 breast cancer results in worse survival.

One of the issues with real world data / retrospective CER is that investigators truly believe in their therapy, and it usually treatment intensification.
There is subsequent publication bias:
1000s of studies will favor doing tx.
Few will favor not doing it.
There is subsequent publication bias:
1000s of studies will favor doing tx.
Few will favor not doing it.
Hence, we see studies favoring multi modality therapy (vs organ preservation) that show supposed improvement in survival.
If investigators keep publishing these retrospective CER studies, patients are harmed by overtreatment.
@DrSpratticus
If investigators keep publishing these retrospective CER studies, patients are harmed by overtreatment.
@DrSpratticus
https://twitter.com/nicholaszaorsky/status/1204505104562491392
We never got to answer the question:
"In the setting of newly diagnosed M1 disease, does local control improve survival?"
Look out for upcoming work from @jryckman3 @Dr_TVThomasMD @EricLehrer @wedney2017 and an international team of experts :-)
"In the setting of newly diagnosed M1 disease, does local control improve survival?"
Look out for upcoming work from @jryckman3 @Dr_TVThomasMD @EricLehrer @wedney2017 and an international team of experts :-)
I don't understand people who say these retrospective CER studies are "hypothesis-generating."
The hypothesis has not been addressed by the study. We know as much before the study as we do after.
However, zealots of treatment A or B will use the study to support their dogma.
The hypothesis has not been addressed by the study. We know as much before the study as we do after.
However, zealots of treatment A or B will use the study to support their dogma.

Some people say "you wouldn't do a randomized trial of parachutes vs not."
Parachutes have a 99.99+% absolute survival benefit.
The vast majority of treatments we have in medicine have no benefit. Rarely, they improve QOL. More rarely, survival. The benefits are usually marginal.
Parachutes have a 99.99+% absolute survival benefit.
The vast majority of treatments we have in medicine have no benefit. Rarely, they improve QOL. More rarely, survival. The benefits are usually marginal.

• • •
Missing some Tweet in this thread? You can try to
force a refresh

















