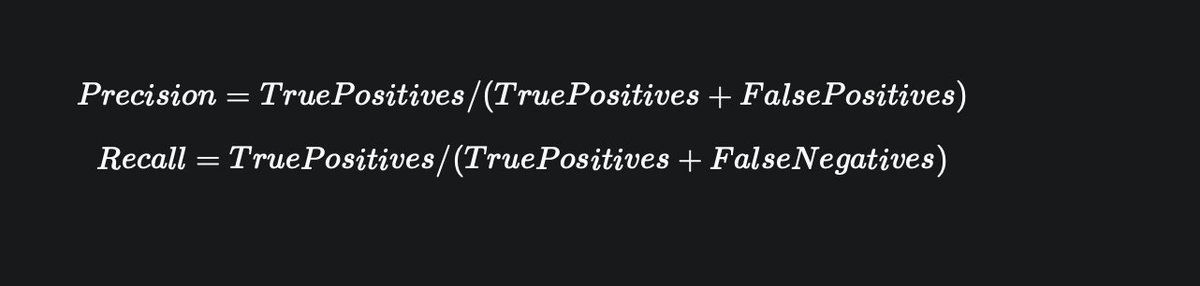Machine Learning weekly highlights 💡
◆3 threads from me
◆3 threads from others
◆2 news from the ML communities
◆3 threads from me
◆3 threads from others
◆2 news from the ML communities
3 POSTS FROM ME
This week, I explained Tom Mitchell's classical definition of machine learning, why it is hard to train neural networks, and talked about some recipes for training and debugging neuralnets.
This week, I explained Tom Mitchell's classical definition of machine learning, why it is hard to train neural networks, and talked about some recipes for training and debugging neuralnets.
Here is the meaning of Tom's definition of machine learning
https://twitter.com/Jeande_d/status/1455872282899877894?s=20
Here is the reason why it is hard to train neural networks
https://twitter.com/Jeande_d/status/1455486459876569091
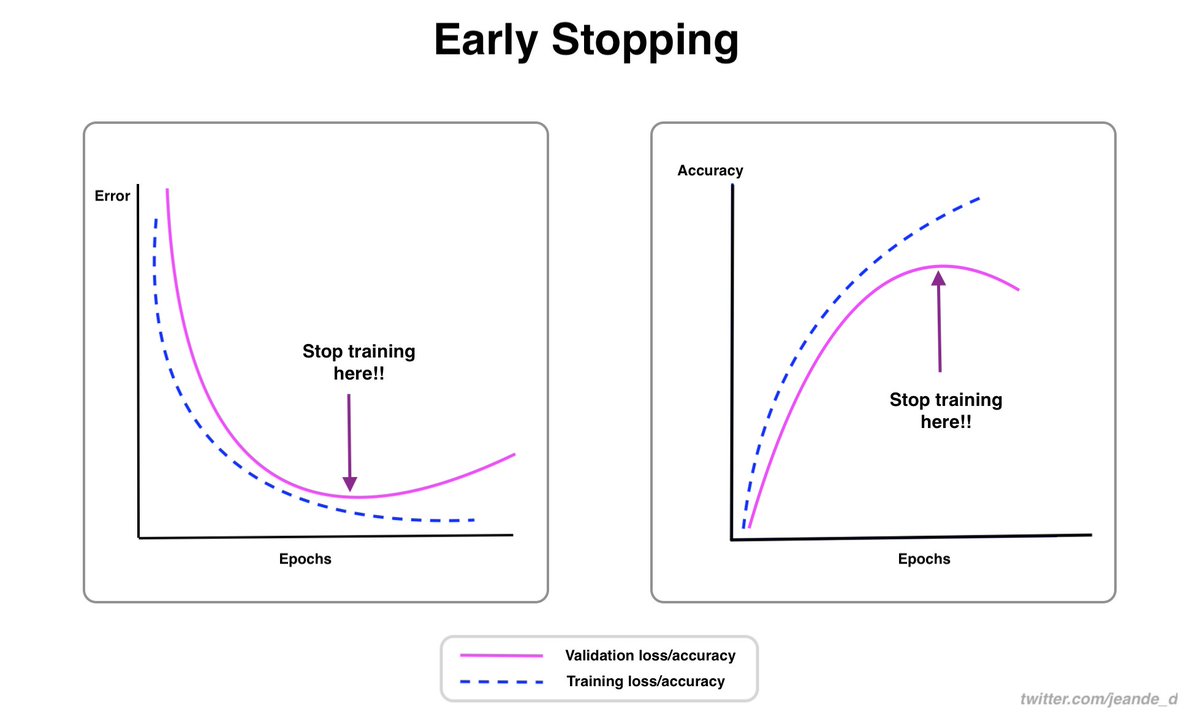
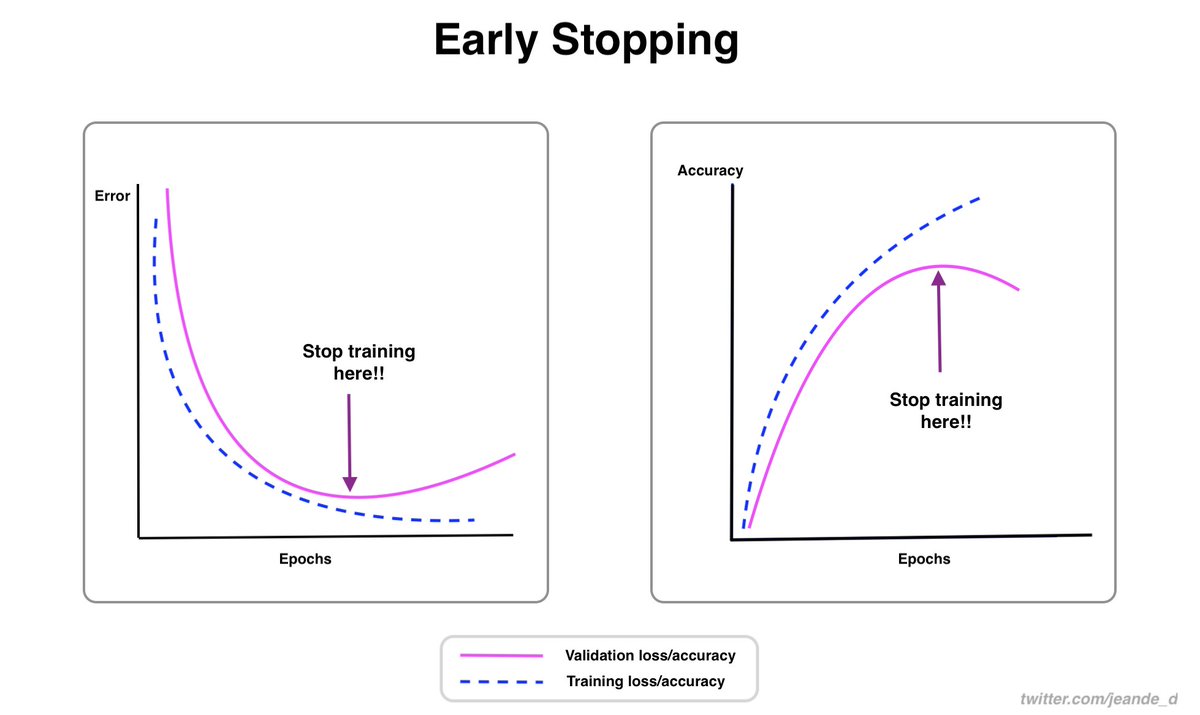
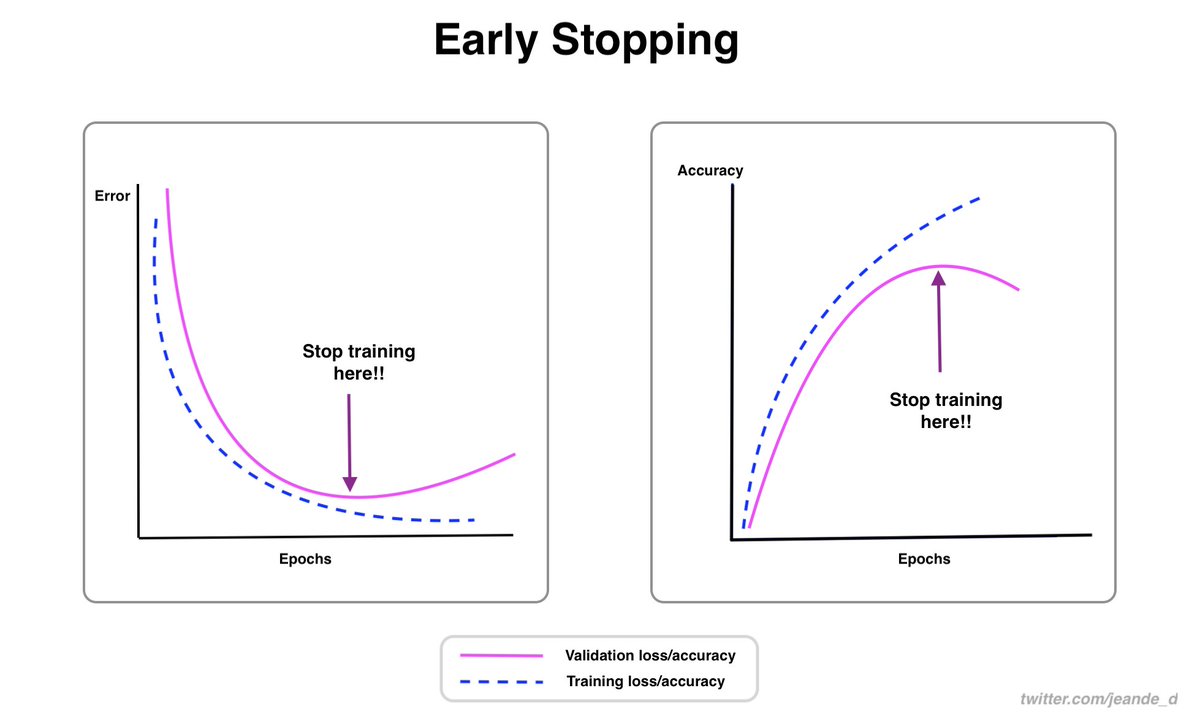
And here are recipes for training and debugging neural networks
https://twitter.com/Jeande_d/status/1456590365222260744?s=20
2 POSTS FROM OTHERS
@gusthema had a great thread about working with large files using Pandas 🐼
@gusthema had a great thread about working with large files using Pandas 🐼
https://twitter.com/gusthema/status/1456607188277936132?s=20
Another amazing thread that I came across was about creating arts with machine learning by @haltakov.
https://twitter.com/haltakov/status/1455982555610636291?s=20
Git is an important tool for machine learning engineers.
@JanaSunrise made a great thread about it.
@JanaSunrise made a great thread about it.
https://twitter.com/JanaSunrise/status/1456478904869277705?s=20
2 NEWS FROM THE ML COMMUNITY
TensorFlow 2.7 is now released. There are new updates and changes about tf.keras, TF Core API, TensorFlow Datasets, and TensorFlow Lite.
TF 2.7 also brings new debugging experiences. @fchollet had a great thread about it.
TensorFlow 2.7 is now released. There are new updates and changes about tf.keras, TF Core API, TensorFlow Datasets, and TensorFlow Lite.
TF 2.7 also brings new debugging experiences. @fchollet had a great thread about it.
https://twitter.com/fchollet/status/1456393128756191233?s=20
The last news from the community is from OpenAI. They trained a system to solve math problems.
Their system can "solve about 90% as many problems as real kids." They released the paper, some samples, and datasets.
More from @sama
Their system can "solve about 90% as many problems as real kids." They released the paper, some samples, and datasets.
More from @sama
https://twitter.com/sama/status/1454191236210839555?s=20
That's it from the machine learning community this week.
I plan to keep doing these weekly highlights and in the upcoming weeks, I will also add more news from other channels beyond Twitter.
I plan to keep doing these weekly highlights and in the upcoming weeks, I will also add more news from other channels beyond Twitter.
Thanks for reading!
Follow @Jeande_d for more machine learning content and you are welcome to share the news with other people who you think might benefit from it.
Until the next week, stay safe!
Follow @Jeande_d for more machine learning content and you are welcome to share the news with other people who you think might benefit from it.
Until the next week, stay safe!
• • •
Missing some Tweet in this thread? You can try to
force a refresh