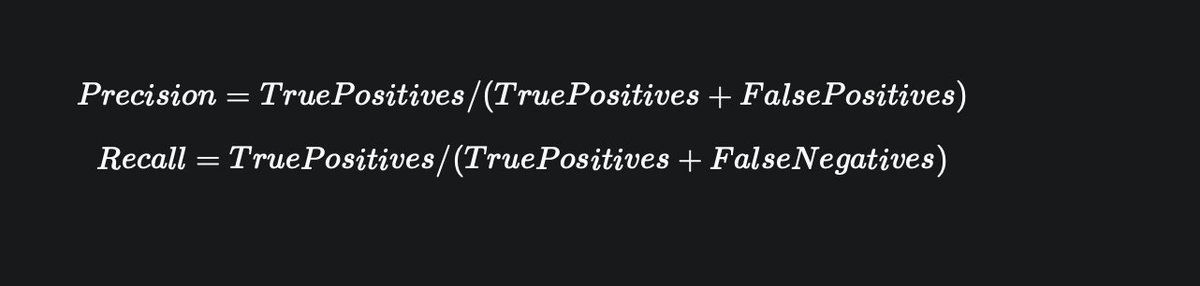The below illustration shows early stopping, one of the effective and simplest regularization techniques used in training neural networks.
A thread on the idea behind early stopping, why it works, and why you should always use it...🧵
A thread on the idea behind early stopping, why it works, and why you should always use it...🧵
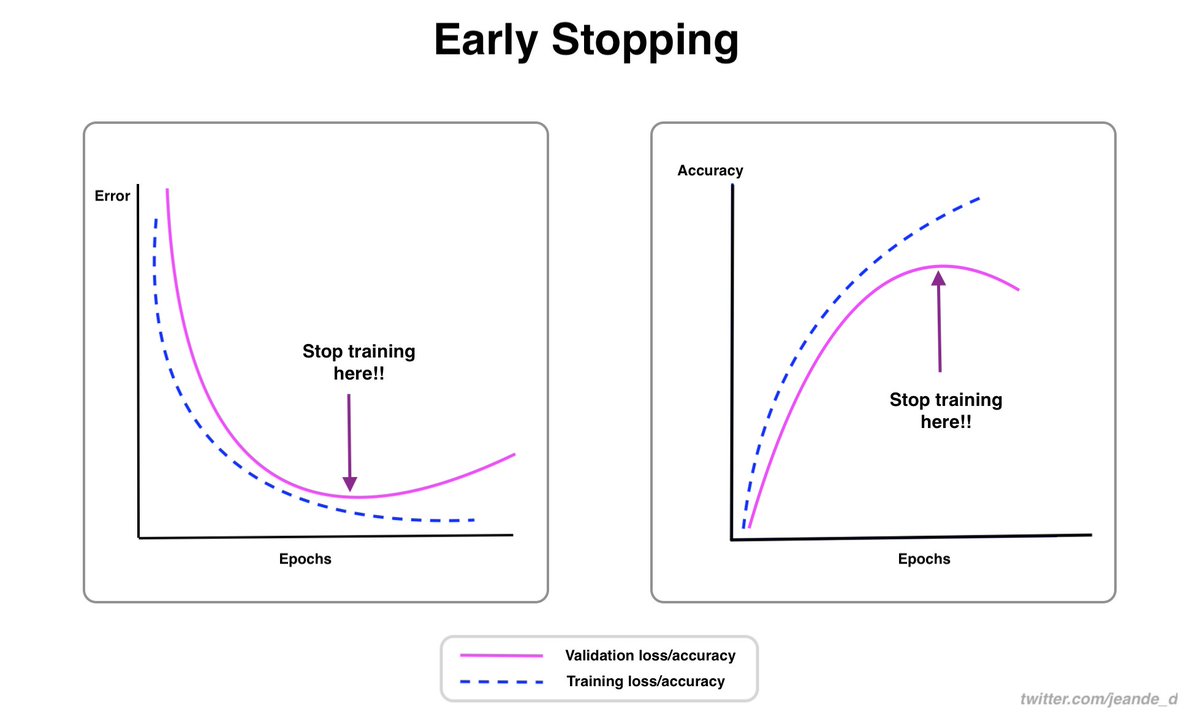
Usually, during training, the training loss will decrease gradually, and if everything goes well on the validation side, validation loss will decrease too.
When the validation loss hits the local minimum point, it will start to increase again. Which is a signal of overfitting.
When the validation loss hits the local minimum point, it will start to increase again. Which is a signal of overfitting.
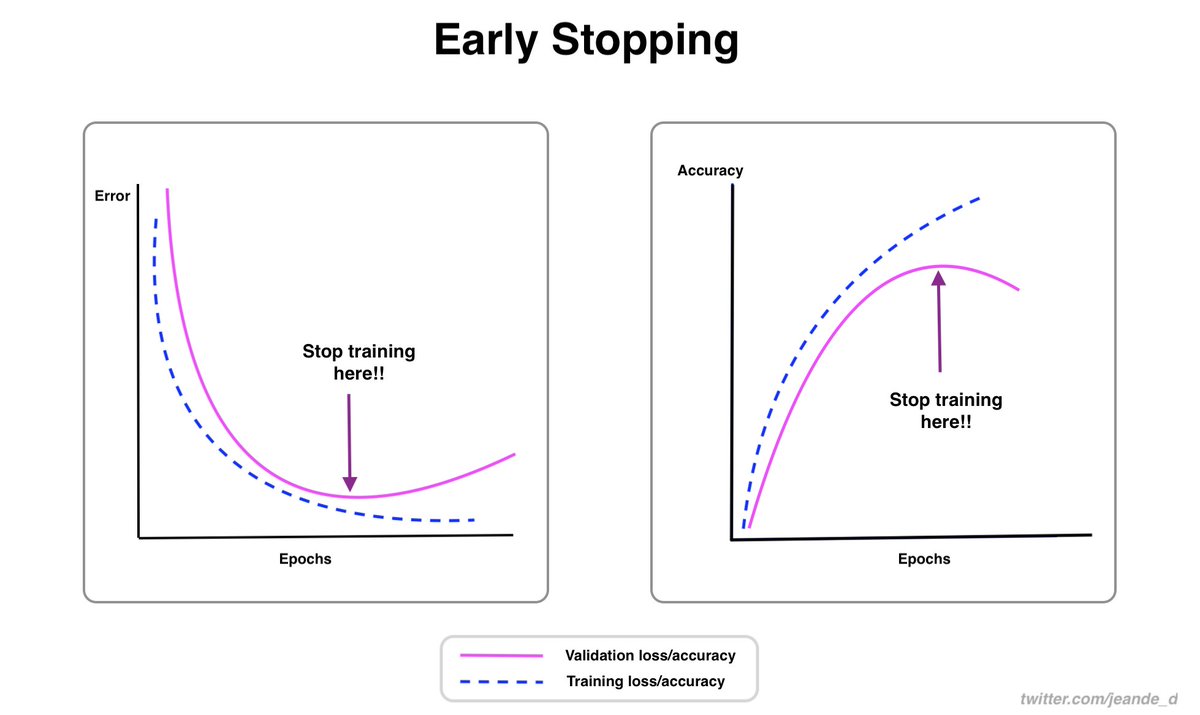
How can we stop the training just right before the validation loss rise again? Or before the validation accuracy starts decreasing?
That's the motivation for early stopping.
With early stopping, we can stop the training when there are no improvements in the validation metrics.
That's the motivation for early stopping.
With early stopping, we can stop the training when there are no improvements in the validation metrics.
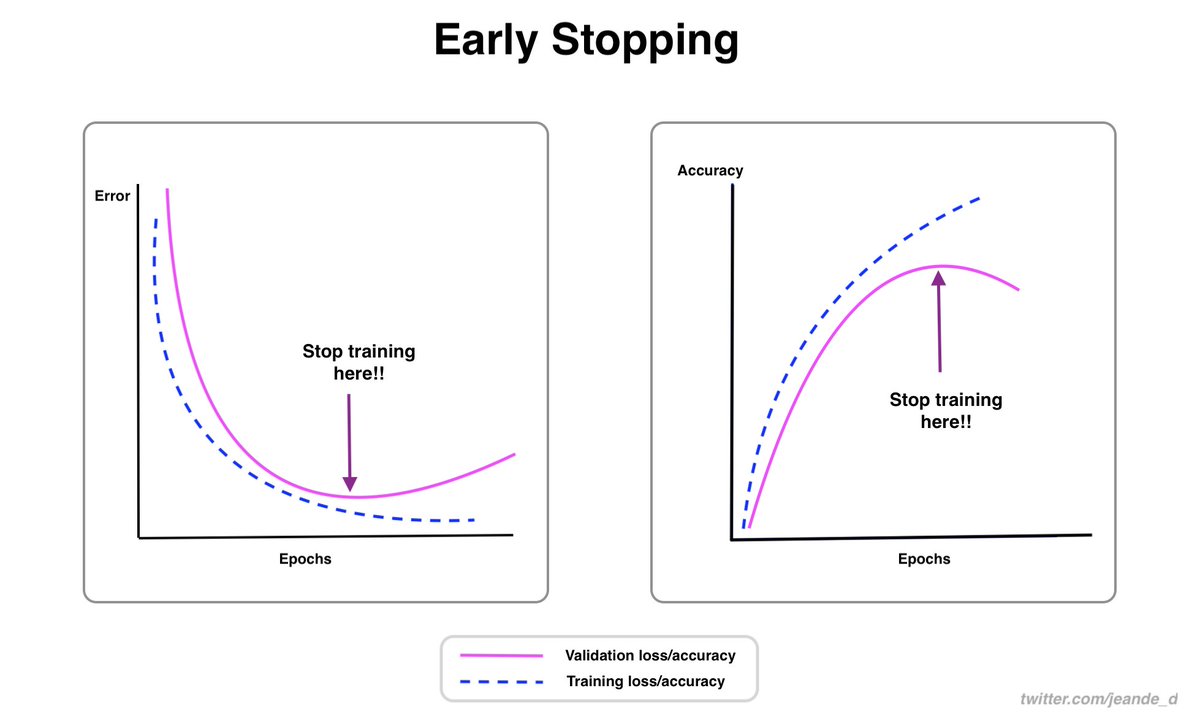
Another interesting thing about early stopping is that it can allow restoring the best model weights at the epoch/iteration where the validation loss was at the minimum point.
You should always consider using early stopping.
Think about this...When we specify the number of training epochs, we have no idea of the right number of epochs to train for. We don't know the specific epoch that will yield the lowest validation loss or highest accuracy.
Think about this...When we specify the number of training epochs, we have no idea of the right number of epochs to train for. We don't know the specific epoch that will yield the lowest validation loss or highest accuracy.
Early stopping can help stop the training as soon as there are no improvements in validation metrics, which can ultimately save time and computation power.
And thus, it is not merely for a better model generalization, but also for saving compute power and time.
And thus, it is not merely for a better model generalization, but also for saving compute power and time.
Many notable deep learning leads have positive views about early stopping. Almost no one downvote using it.
@geoffreyhinton once said that early stopping is a "beautiful free lunch"(Quoted from Hands-on ML with Scikit-Learn, Keras & TF, by @aureliengeron).
@geoffreyhinton once said that early stopping is a "beautiful free lunch"(Quoted from Hands-on ML with Scikit-Learn, Keras & TF, by @aureliengeron).
If you were training neural networks in 2015, you would have to implement early stopping from scratch.
But today, most deep learning frameworks such as TensorFlow and PyTorch provide its implementation.
They also provide other related callback functions for controlling training
But today, most deep learning frameworks such as TensorFlow and PyTorch provide its implementation.
They also provide other related callback functions for controlling training
Here is a link for early stopping and other callback functions in TensorFlow/Keras
keras.io/api/callbacks/
keras.io/api/callbacks/
There is only one downside of early stopping. You need to have validation data to use it.
But in the grand scheme of things, that is not a downside because you still want to have validation data for evaluating your model during the training process either way.
But in the grand scheme of things, that is not a downside because you still want to have validation data for evaluating your model during the training process either way.
This is the end of the thread that was about early stopping, why it's a helpful technique, and why you should always use it.
As a punchline, early stopping helps stop the training when there is no improvement in validation loss/accuracy.
As a punchline, early stopping helps stop the training when there is no improvement in validation loss/accuracy.
But there is one more thing:
You can get the practical implementation of early stopping and other ways to control training from this notebook, in section 3.7.
Run in @DeepnoteHQ
deepnote.com/project/machin….
You can get the practical implementation of early stopping and other ways to control training from this notebook, in section 3.7.
Run in @DeepnoteHQ
deepnote.com/project/machin….
Or check my machine learning complete repository for more practical implementations of most machine learning and deep learning techniques and algorithms.
github.com/Nyandwi/machin…
github.com/Nyandwi/machin…
Thanks for reading!
I am actively writing about machine learning ideas on Twitter. If you find any of the things I write helpful, retweet or share with your friends & communities.
Follow @Jeande_d for more ideas!
I am actively writing about machine learning ideas on Twitter. If you find any of the things I write helpful, retweet or share with your friends & communities.
Follow @Jeande_d for more ideas!
• • •
Missing some Tweet in this thread? You can try to
force a refresh