Quick Thread : 5 Cool Advanced Pandas Techniques for Data Scientists
🧵👇🏻
#Python #DataScience #MachineLearning #DataScientist #Programming #Coding #100DaysofCode #hubofml #Pandas
🧵👇🏻
#Python #DataScience #MachineLearning #DataScientist #Programming #Coding #100DaysofCode #hubofml #Pandas
1. Split data using pandas
In the code below, we are splitting the data into a random sample of rows and removing them from the original data after dropping index values.
In the code below, we are splitting the data into a random sample of rows and removing them from the original data after dropping index values.

2. Binning Data
Binning is a technique to group/bin your data into multiple buckets which is very helpful if you dealing with continuous numeric data. In pandas you can bin the data using functions cut and cut. First check the shape of your data i.e no of rows and columns.
Binning is a technique to group/bin your data into multiple buckets which is very helpful if you dealing with continuous numeric data. In pandas you can bin the data using functions cut and cut. First check the shape of your data i.e no of rows and columns.

3. Slicing using loc and iloc functions
You can do position based and label based slicing using iloc and loc functions respectively.
You can do position based and label based slicing using iloc and loc functions respectively.

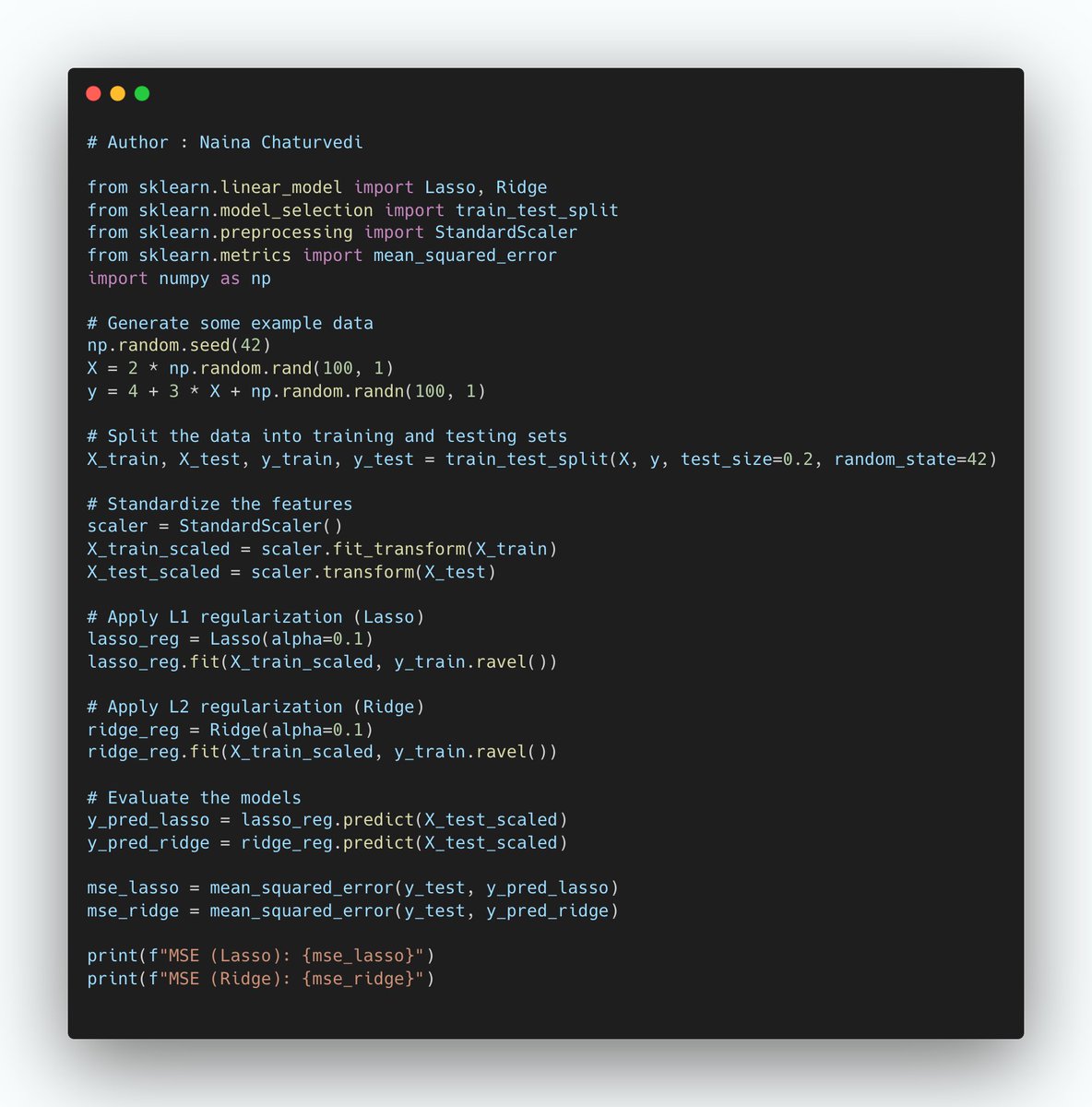
4. Mean Imputation and Interpolate method
Mean Imputation is a technique in which the missing value is replaced by the mean of available data in the chosen column.
Mean Imputation is a technique in which the missing value is replaced by the mean of available data in the chosen column.

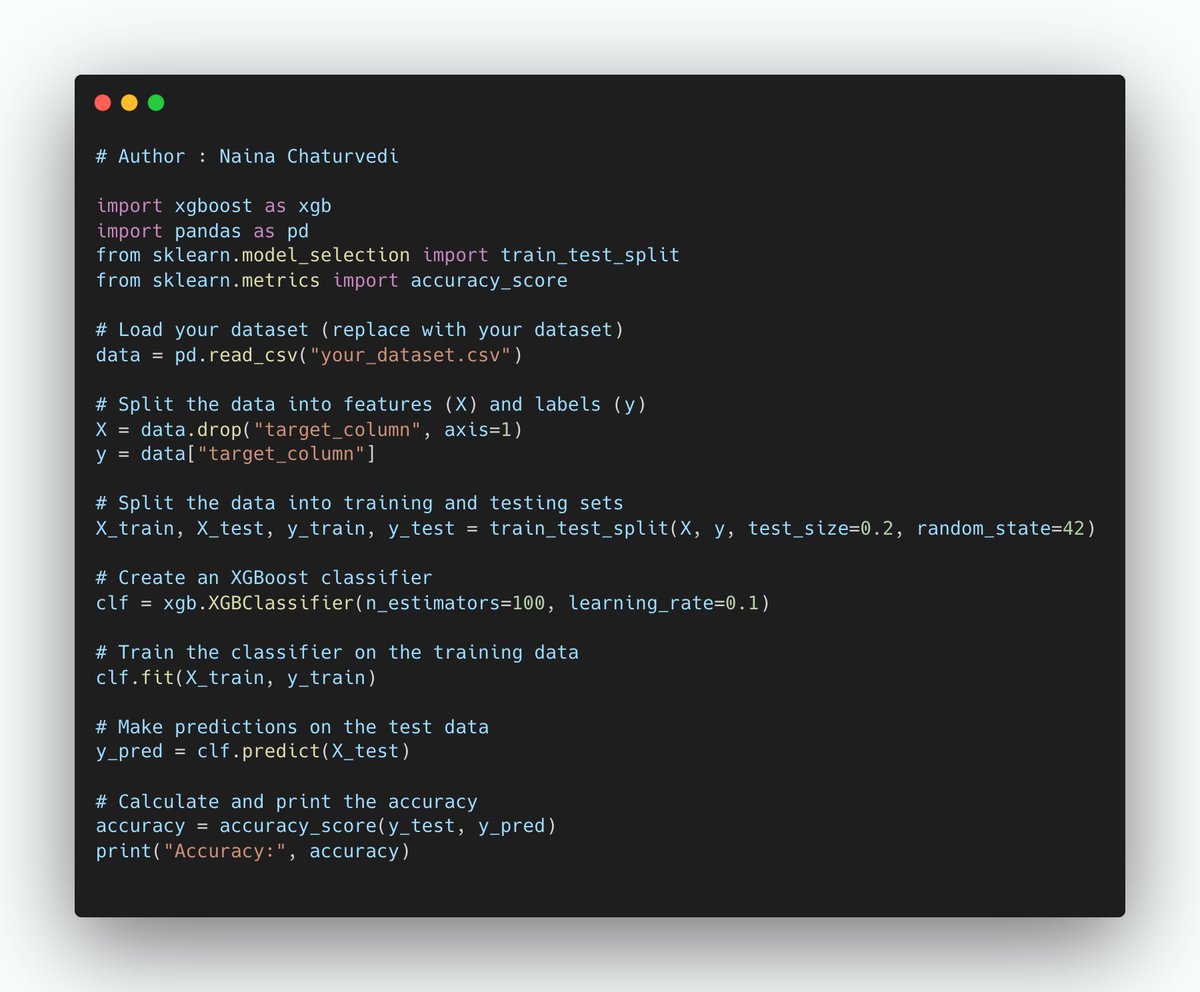
5. Combining Data using Concat and Join
Just like in numpy, pd.concat() function is used for concatenation of Series or DataFrame objects in pandas.
Just like in numpy, pd.concat() function is used for concatenation of Series or DataFrame objects in pandas.

6. Want to know more? Join us : 60 days of Data Science and Machine Learning
medium.com/coders-mojo/qu…
medium.com/coders-mojo/qu…
• • •
Missing some Tweet in this thread? You can try to
force a refresh