Building on parts 1 & 2 which explained multi-head attention and GPT, in part 3 of the Transformer Series we'll cover masked language models like BERT.
This thread → masked language models, diff between causal and bi-directional masked attention, finetuning, and code.
1/N
This thread → masked language models, diff between causal and bi-directional masked attention, finetuning, and code.
1/N

Since we'll be referencing multi-head attention and GPT, make sure to read parts 1 & 2 if you're unfamiliar with these concepts.
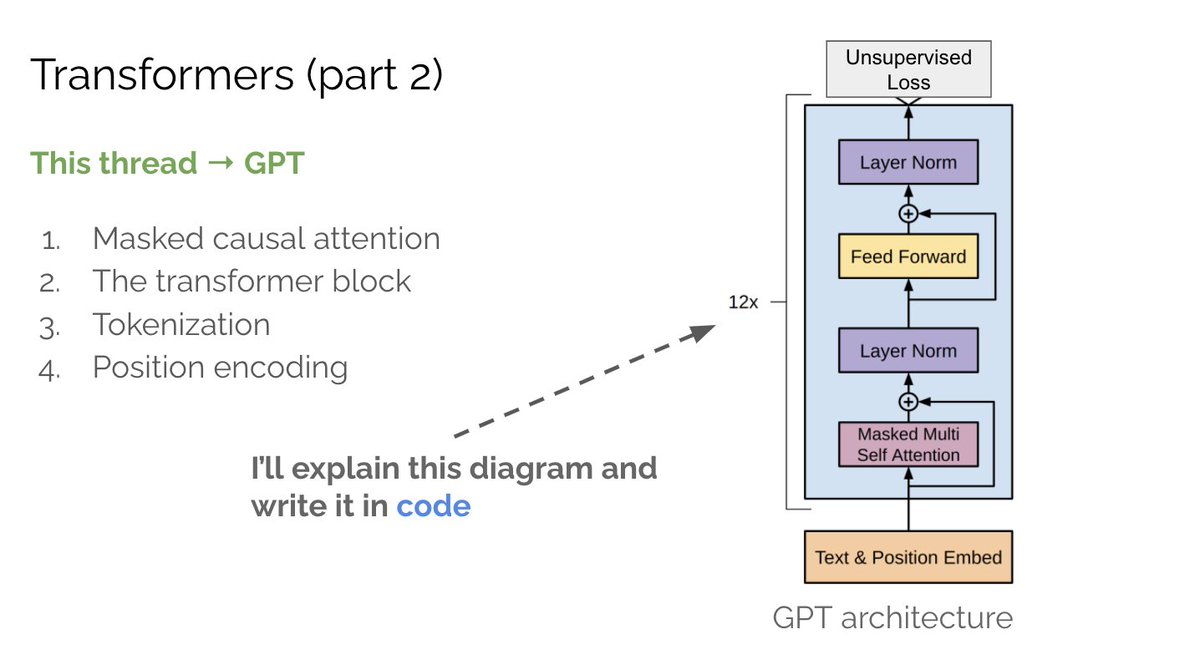
Part 2, GPT:
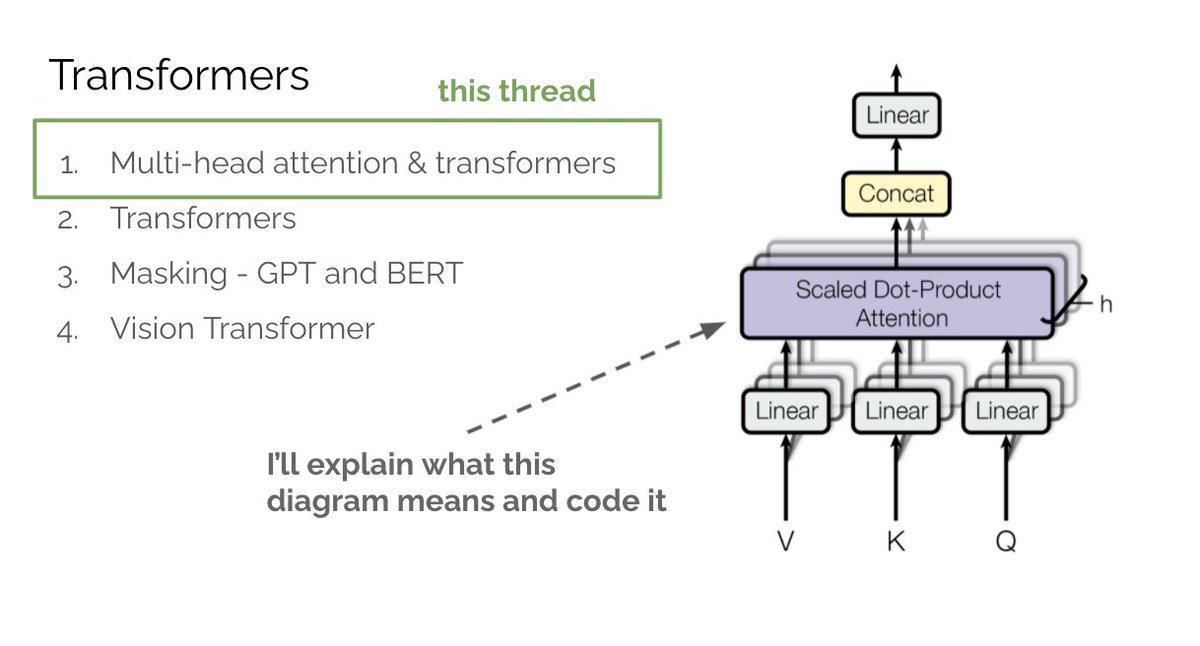
Part 1, Multi-head attention:
2/N
Part 2, GPT:
https://twitter.com/MishaLaskin/status/1481767733972901888
Part 1, Multi-head attention:
https://twitter.com/MishaLaskin/status/1479246928454037508
2/N
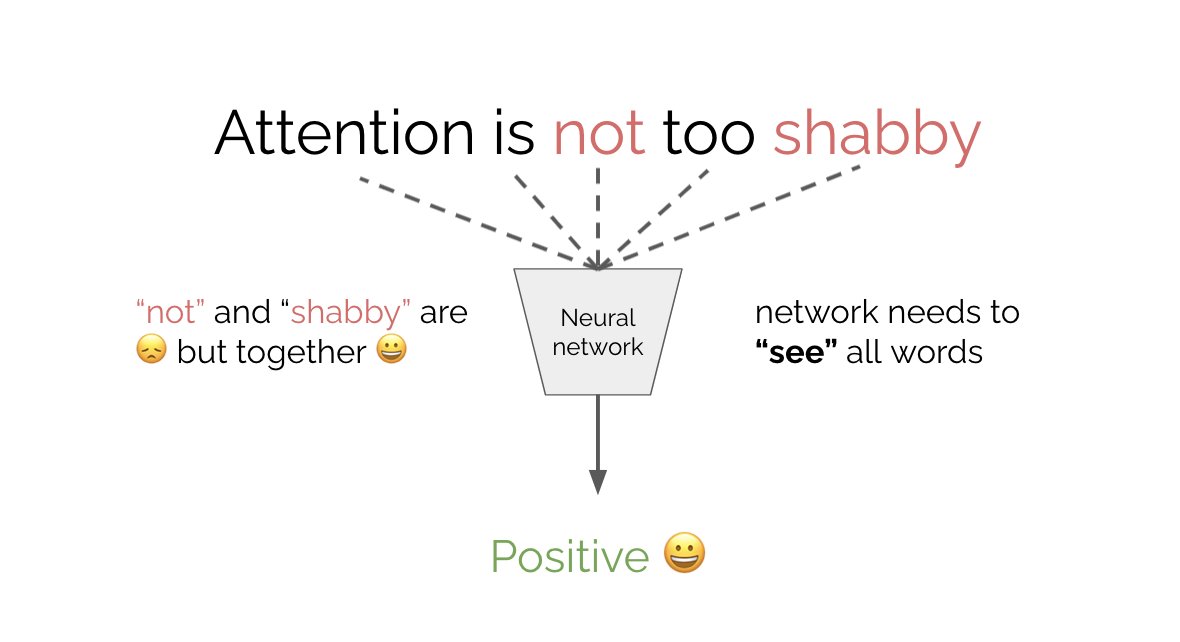
We saw with GPT that we can pre-train language models with a causal predict-the-future objective. Instead, BERT uses a fill-in-the-blank objective. It is called bi-directional because unlike GPT (which is causal) it sees both past and future tokens at once.
3/N
3/N
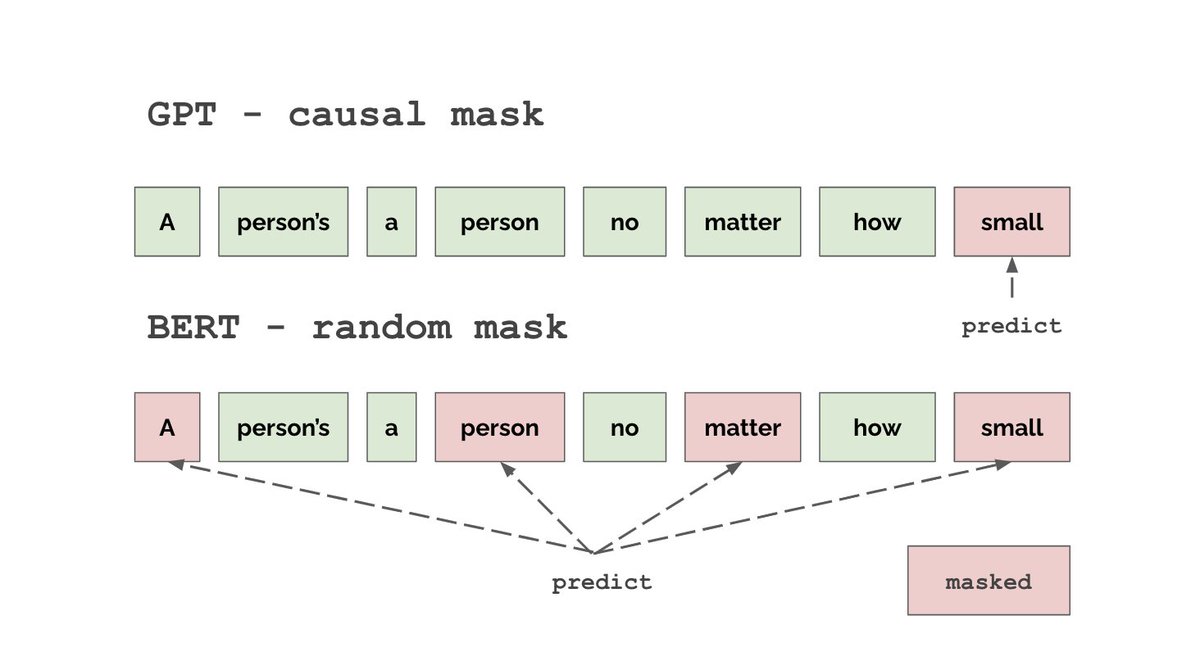
So how does BERT work? The architecture is outlined below. BERT works (almost) exactly like GPT except for two main differences: (A) instead of using a causal mask we use a random one (B) BERT prepends an additional [CLS] to each sequence. What is this new [CLS] token?
4/N
4/N
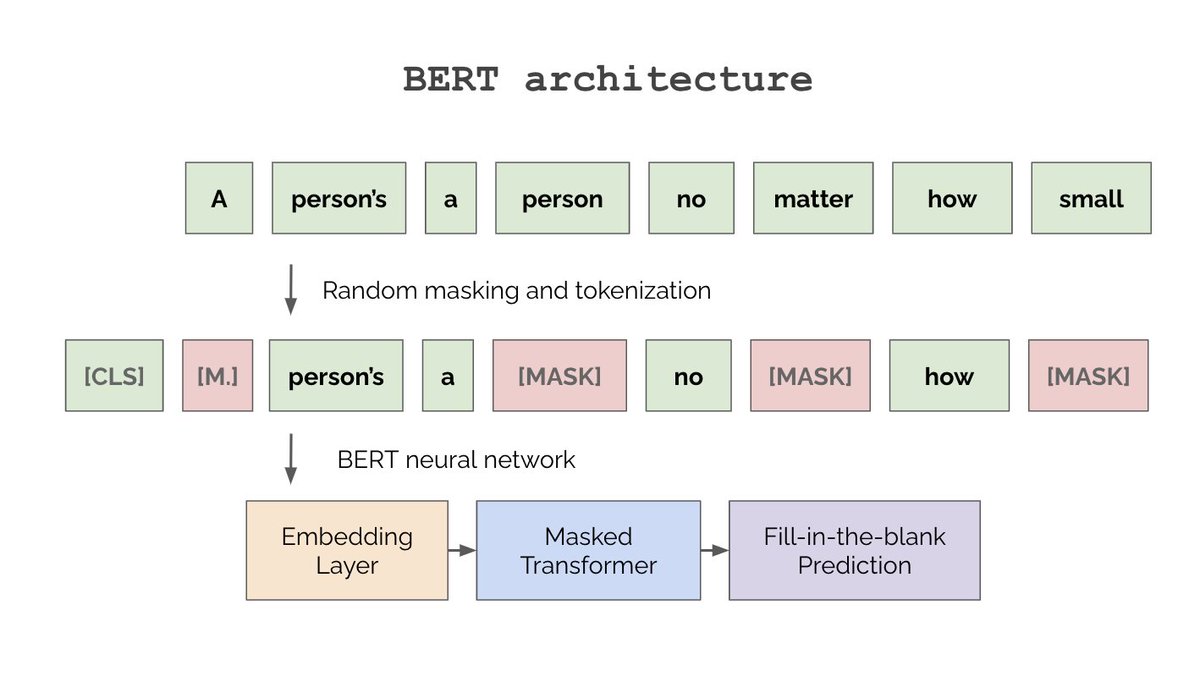
Suppose we want to use BERT for sentiment classification. Our transformer's outputs have shape (B, T, D). We want to compress this to (B, D) so each data pt has an aggregate representation that we can feed into a classifier. First guess - how about we average over the T dim?
5/N
5/N
This will work, but it assumes that all tokens are equally useful for classification. Isn't the whole point of attention to weigh tokens based on their relevance? What if we add a new token to the input that aggregates the other tokens with attention? That's the pt of [CLS].
6/N
6/N
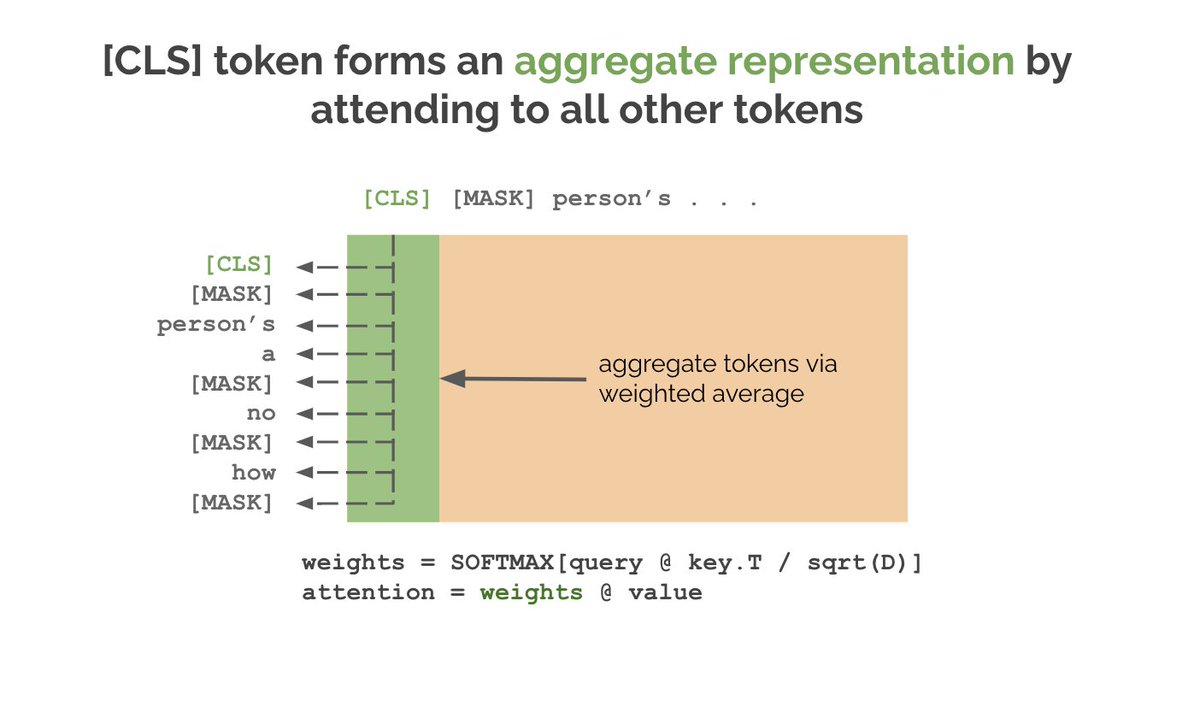
When we finetune BERT for classification (hence name of token), we use the final hidden state of the [CLS] token as the input to a classifier, which is just an MLP that projects the [CLS] hidden state with shape (B,D) to the number of classes with shape (B, num_classes).
7/N
7/N
Aside from [CLS] there are other special tokens in BERT - namely [MASK], which replaces masked tokens, and [SEP] which is a sentence separation token. Tokenization happens during data loading. Once we've tokenized, we fuse these and positional tokens like in the code below.
8/N
8/N

Now that we know how tokenization works, the BERT block and pre-training objectives are actually identical to GPT. The only diff is that BERT uses a random mask while GPT uses a causal one, but the code implementation is nearly identical for both.
8/N
8/N

For BERT, each time we pass in a batch of data for pre-training, we sample a new random mask. This can be done efficiently if the mask is created directly on the GPU. Here's what what mask creation and masked language modeling objective look like. Pretty straightforward!
9/N
9/N

Tl;dr BERT = GPT but with random masking and some special tokens (e.g. [CLS] token). It's remarkable that transformers are so simple and general-purpose.
Next time I'll show how transformers can be used in computer vision with the Vision Transformer (ViT) + MAE loss.
10/N END
Next time I'll show how transformers can be used in computer vision with the Vision Transformer (ViT) + MAE loss.
10/N END
• • •
Missing some Tweet in this thread? You can try to
force a refresh