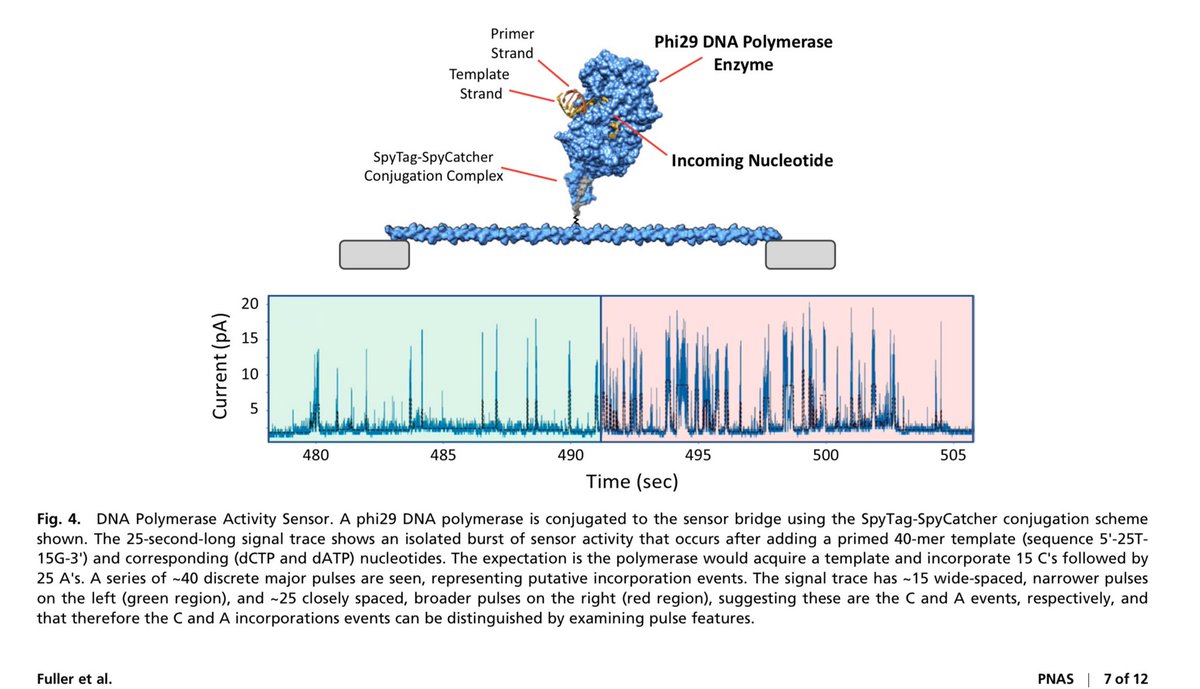
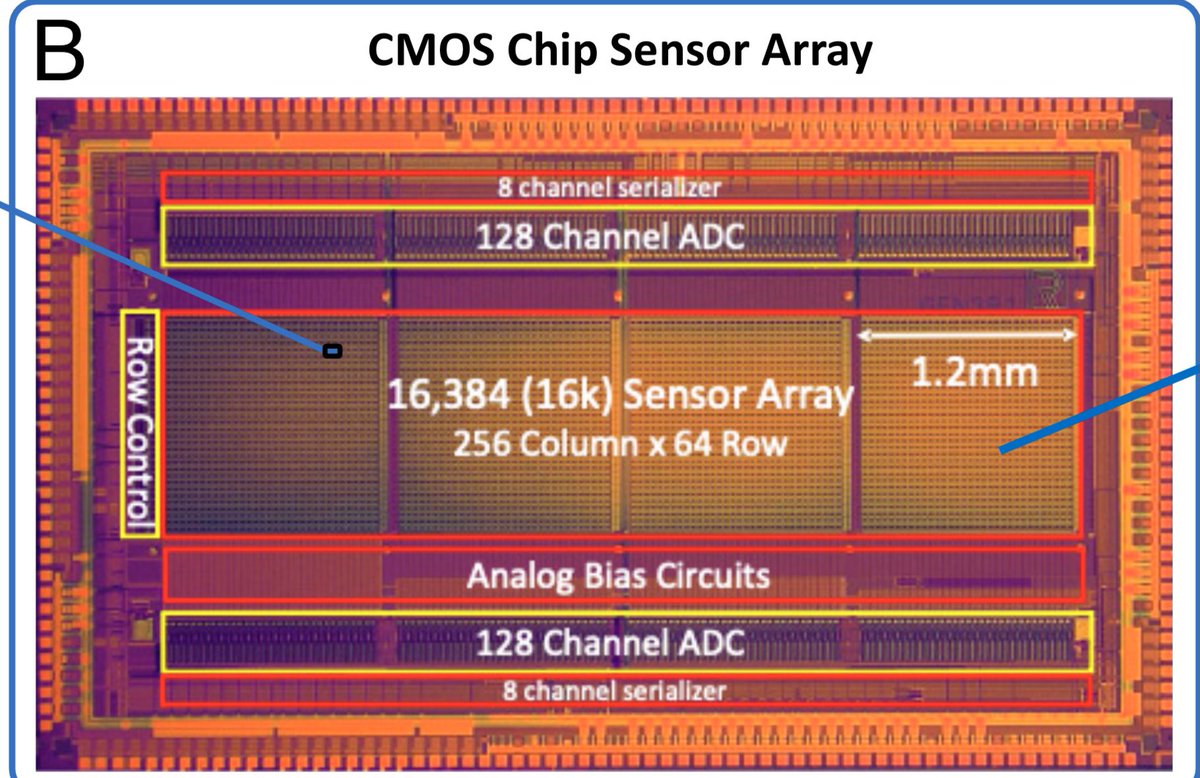
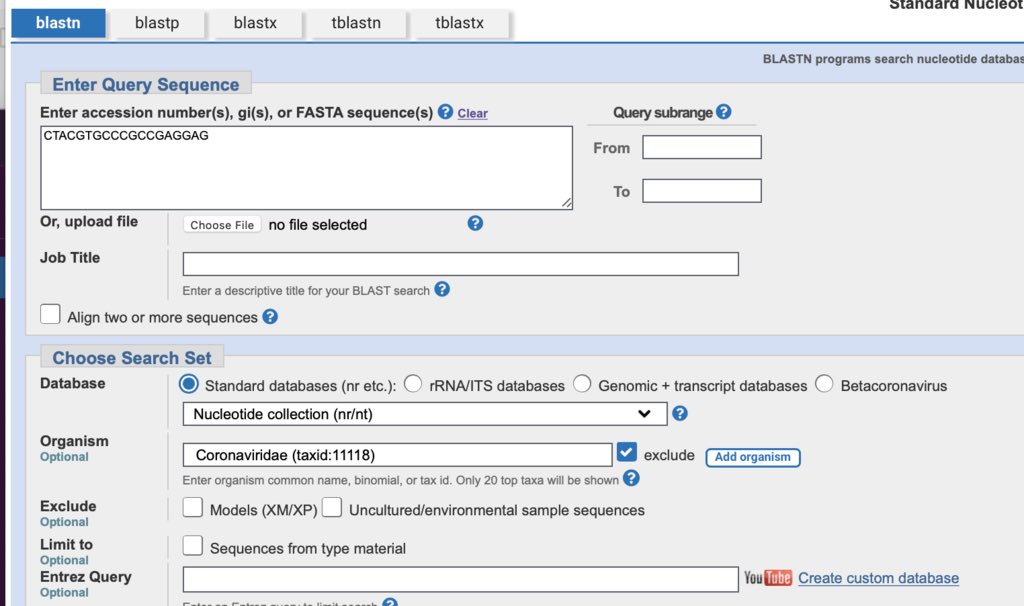
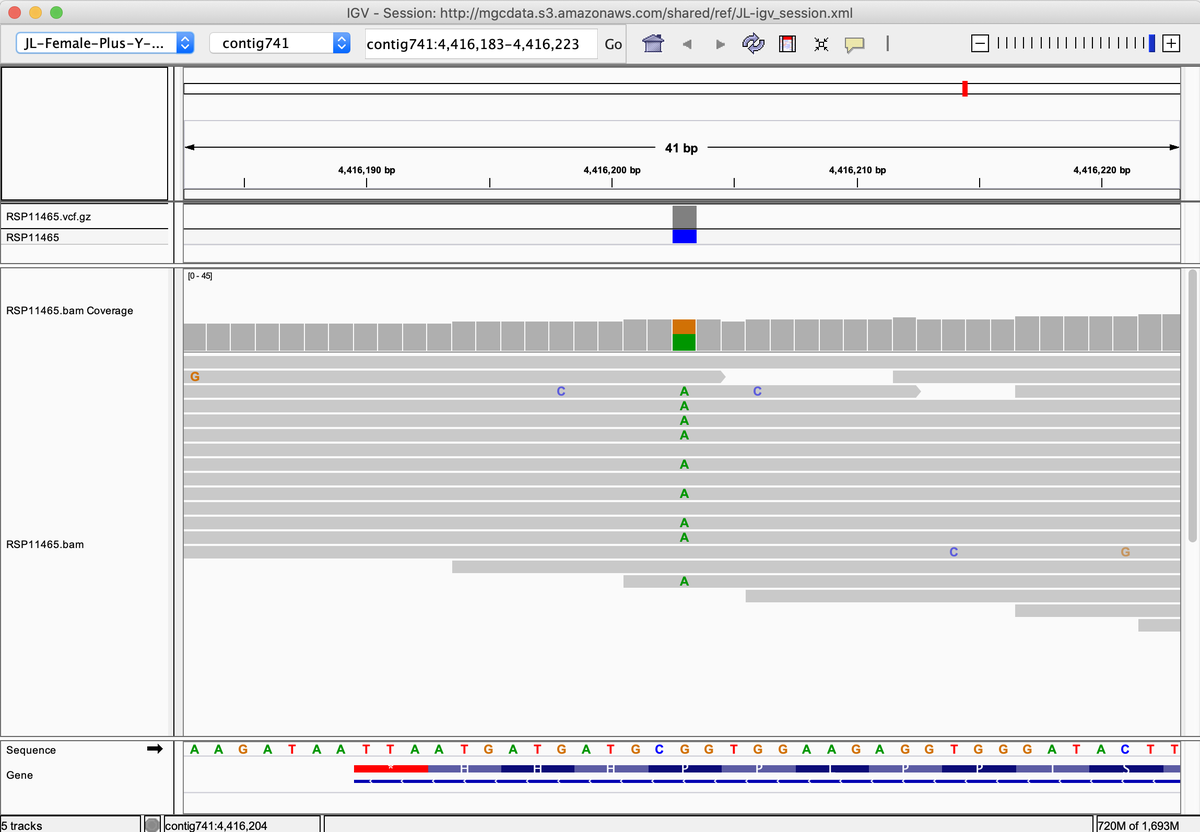
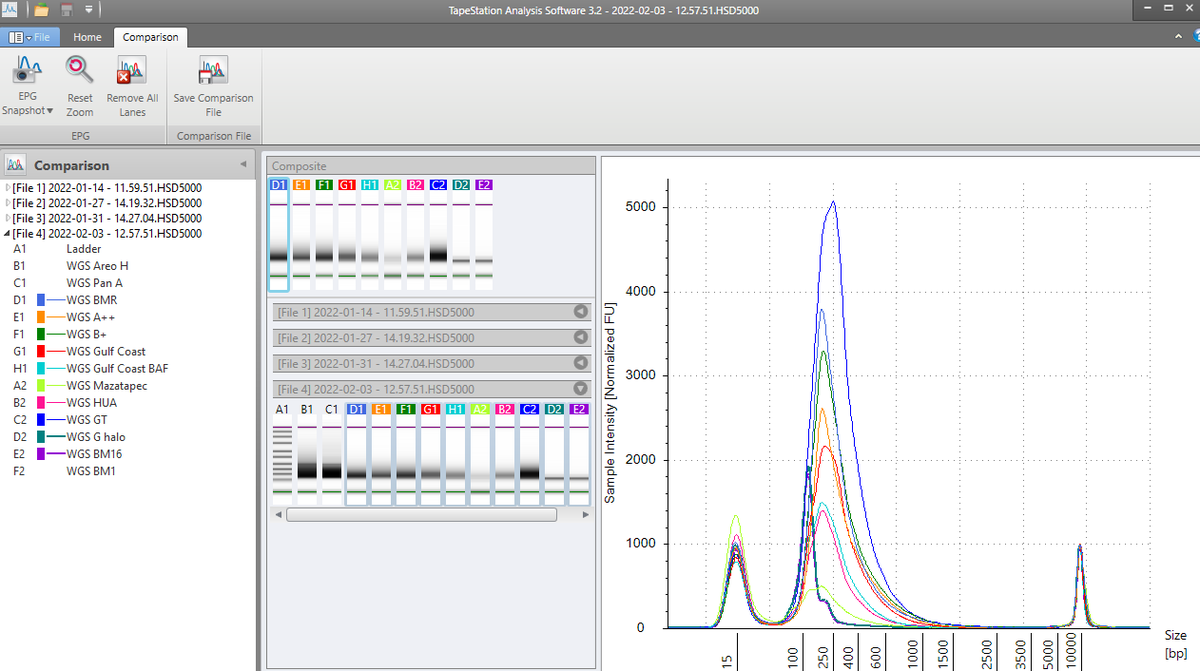
Psilocybe cubensis assembly in NCBI.
This couldn't be done without @PhaseGenomics or @PacBio
ncbi.nlm.nih.gov/Traces/wgs/JAF…
This couldn't be done without @PhaseGenomics or @PacBio
ncbi.nlm.nih.gov/Traces/wgs/JAF…

These HiC maps were performed on spores which express no controversial compounds.
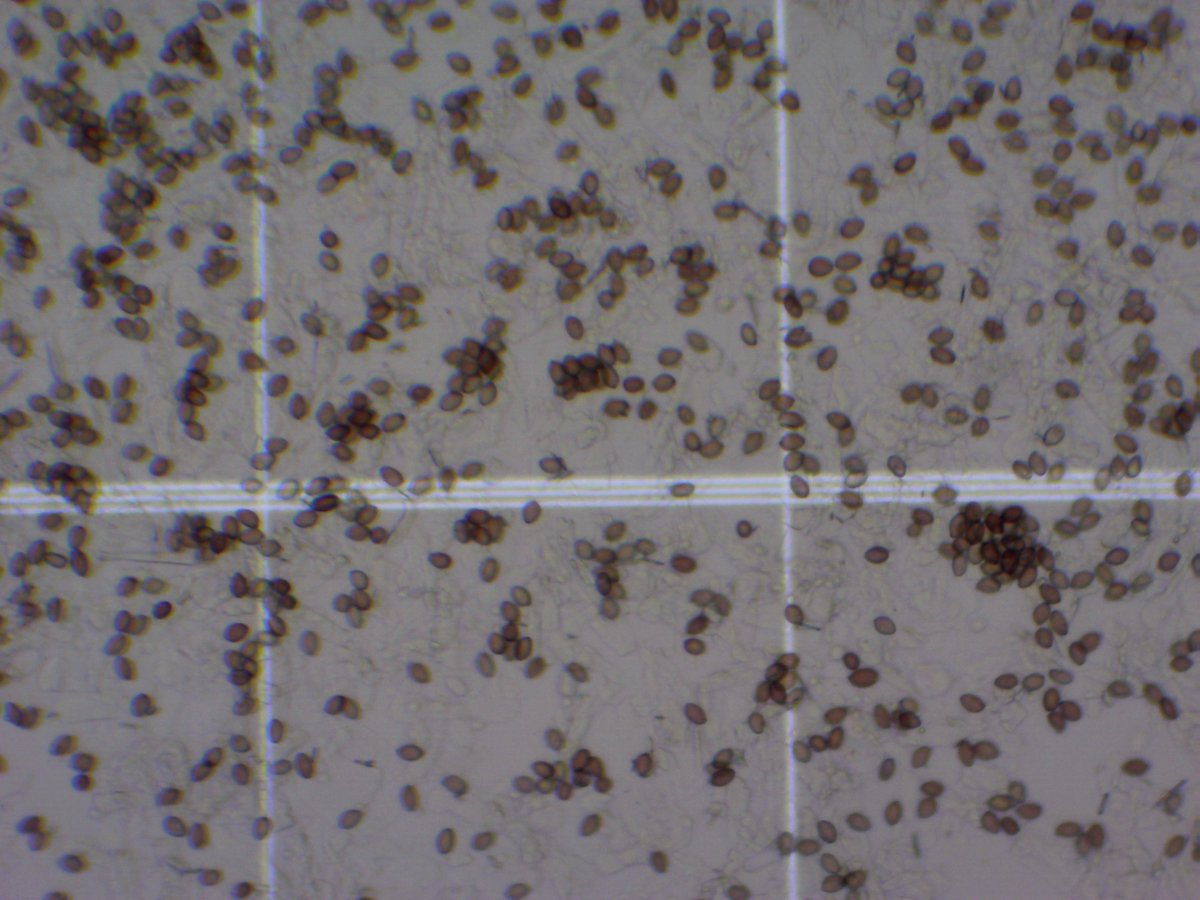
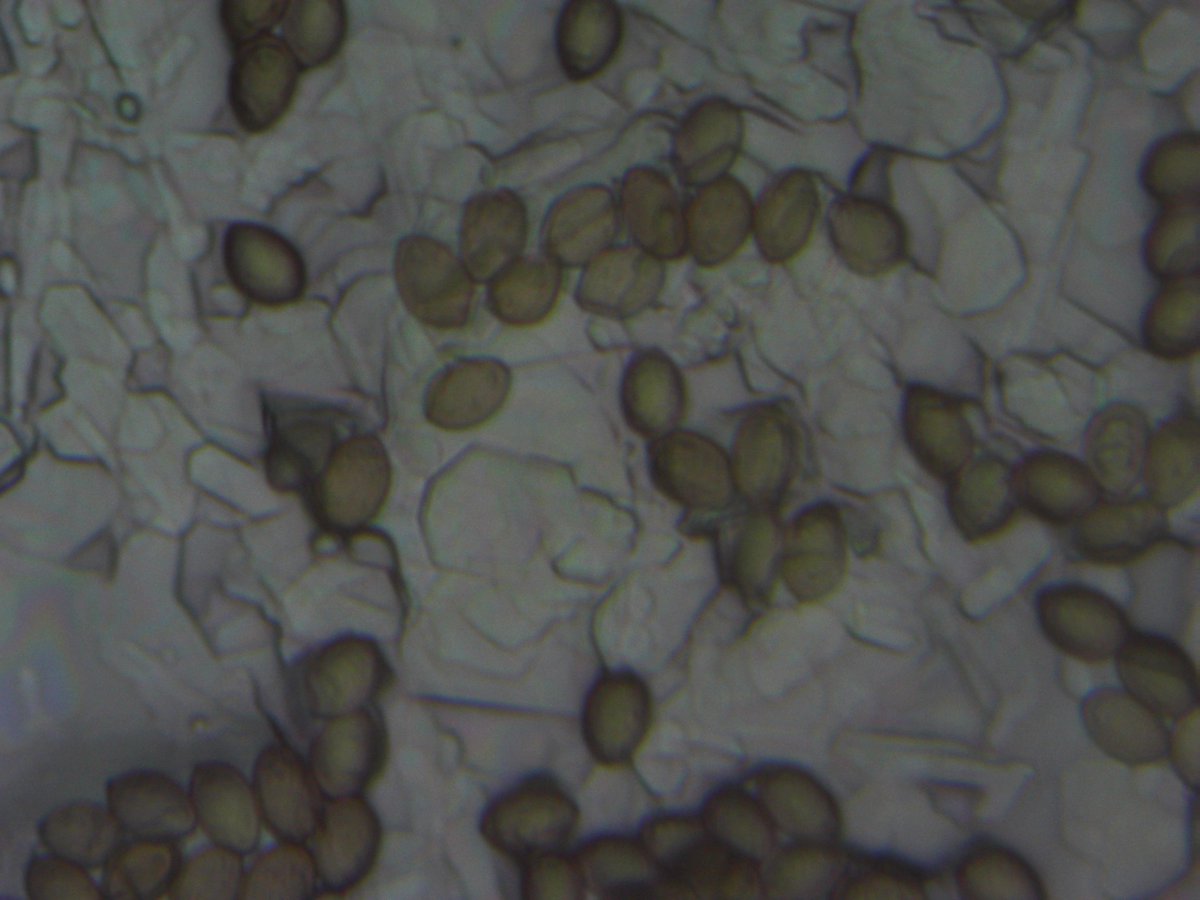
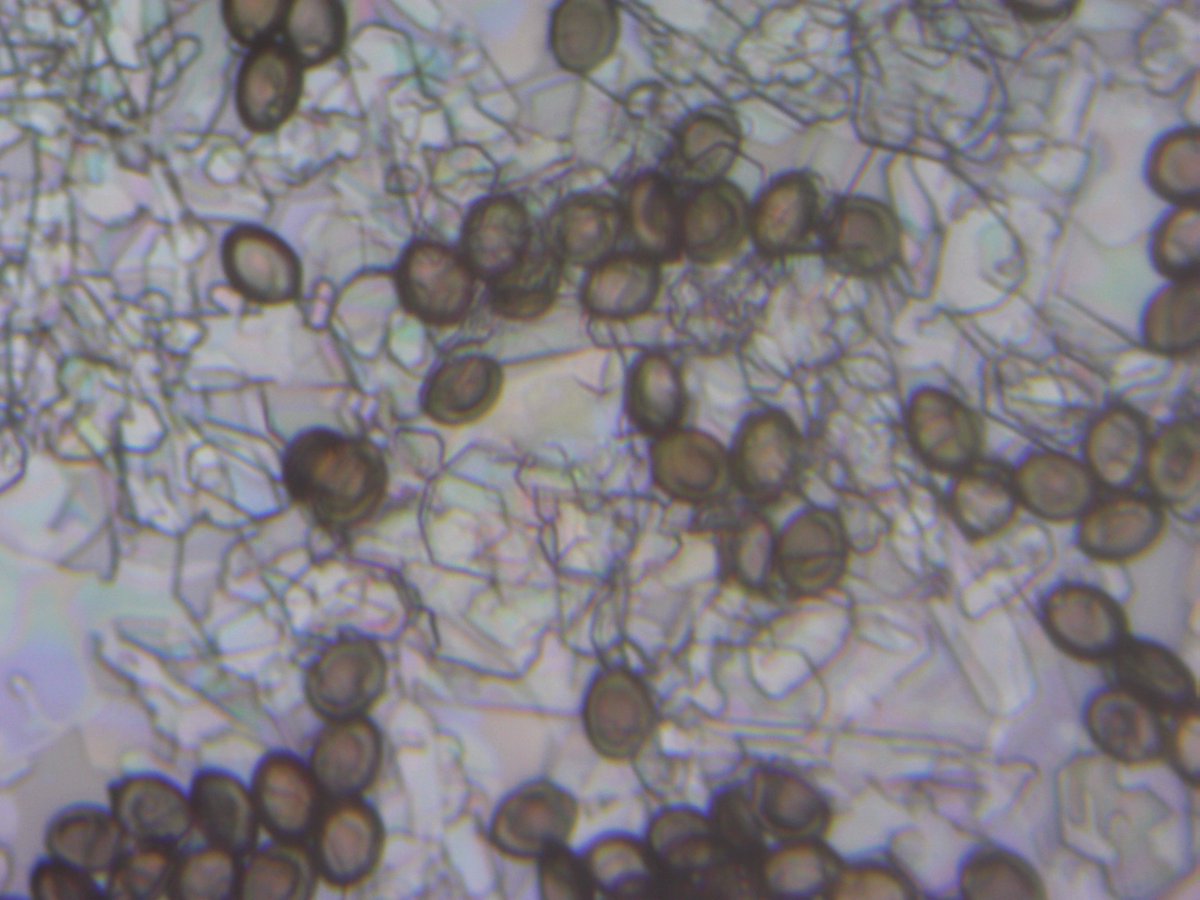
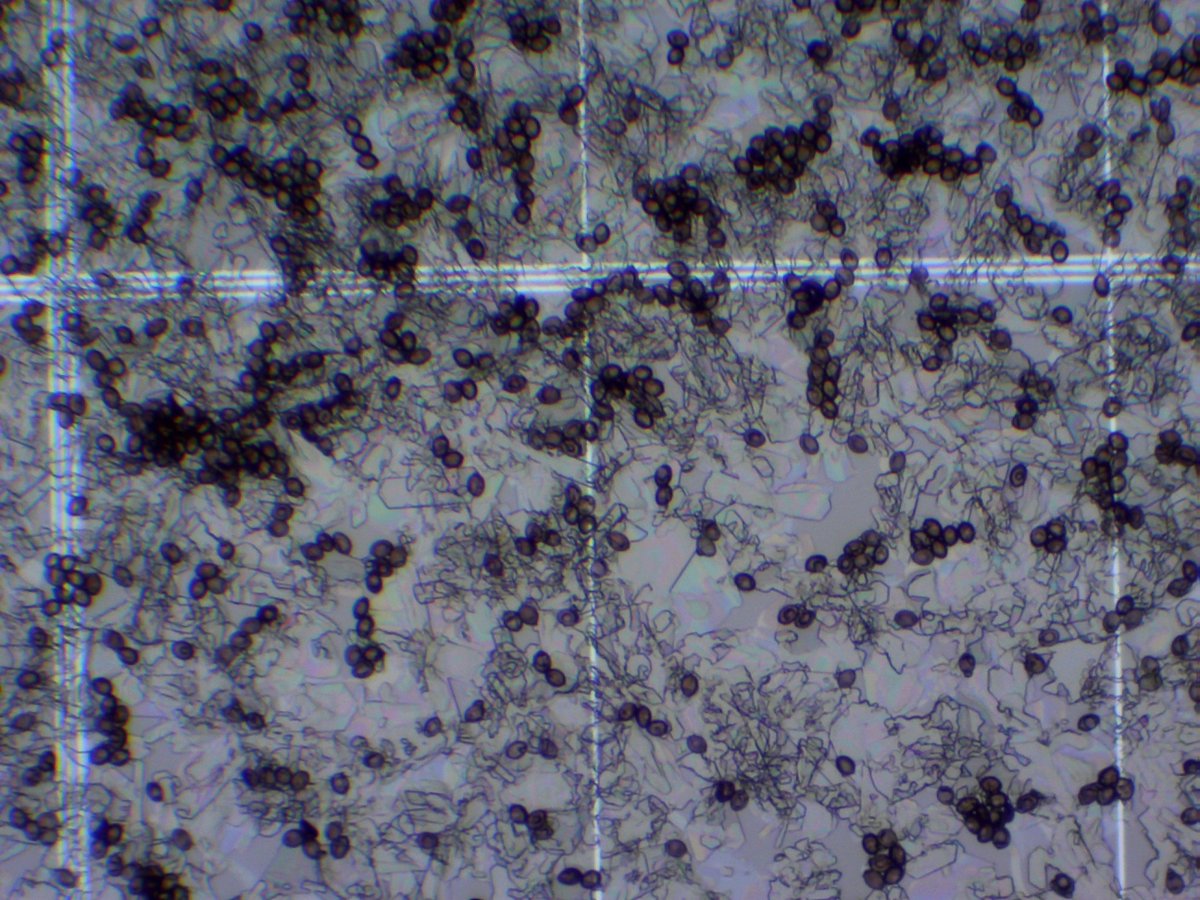
Illumina libraries are also generated with spore preps.
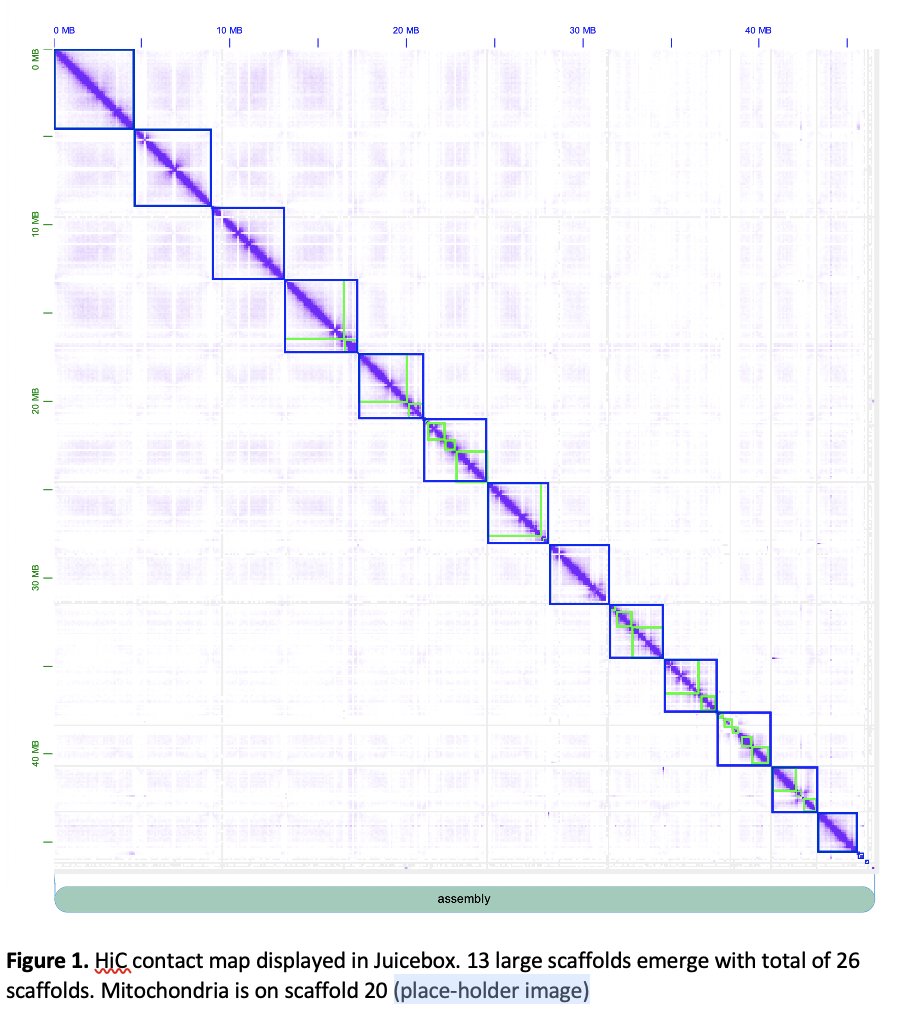
This is the HiC map that organized the 32 contigs of the 1st genome release into 13 chromosomes, Mito and a few small contigs.
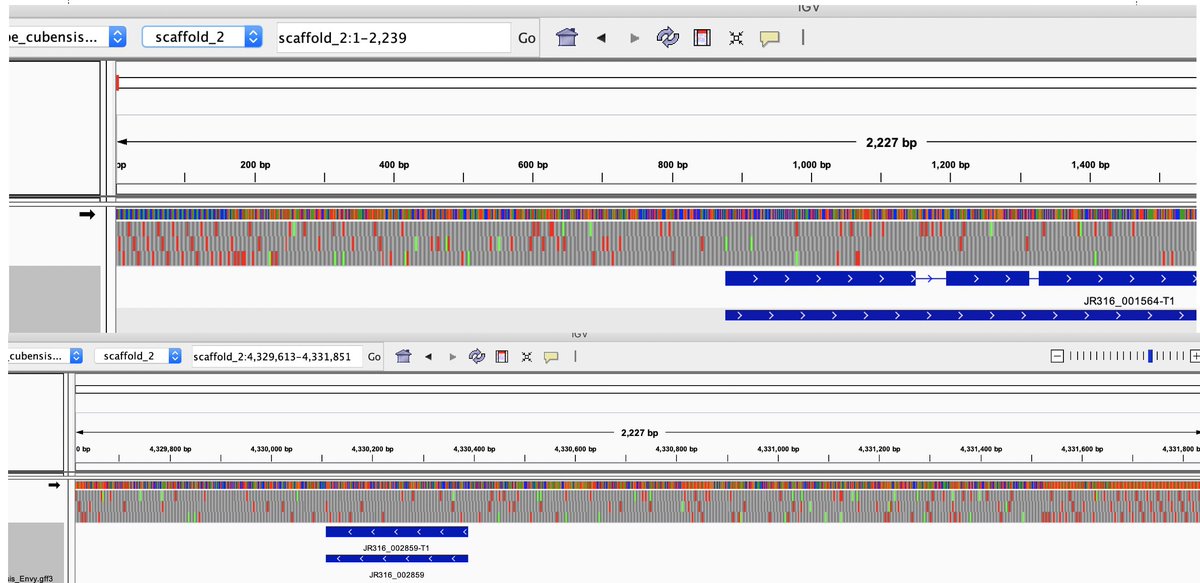
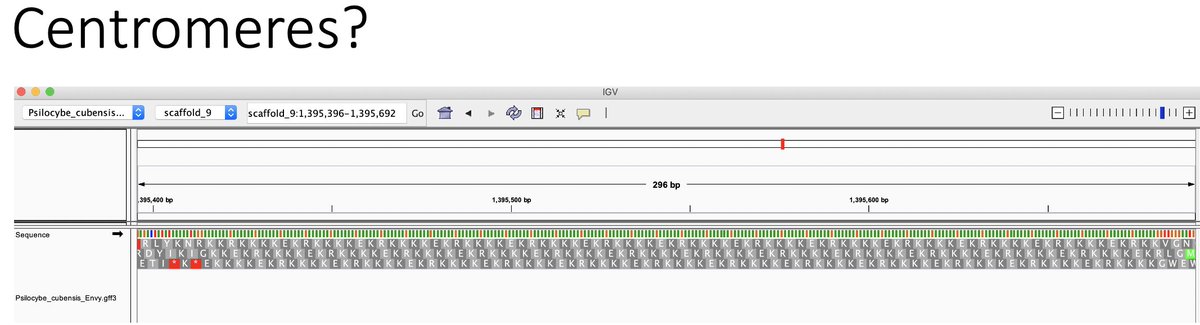
The HiFi data provides nice resolution over the Telomeres. These are some genes tucked right up next to these so getting them properly organized is important.
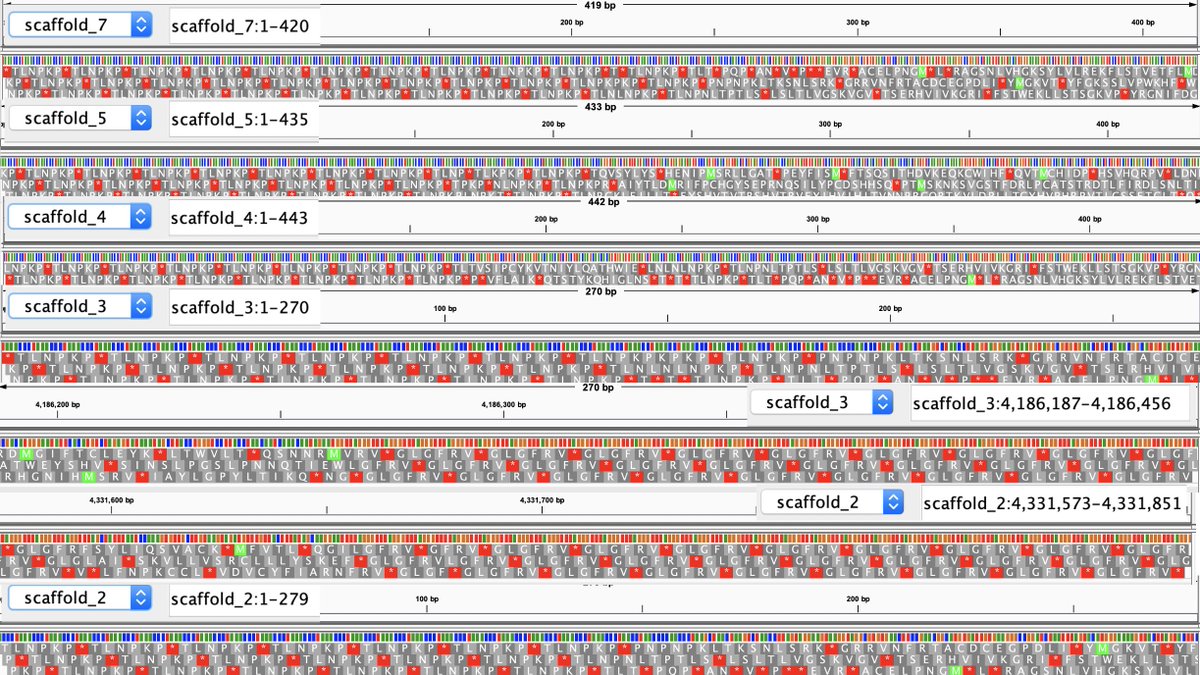
The HiFi data also helps to resolve repeat structures that are longer than the Illumina reads.
There are 81 more genomes that we put public in NCBI that were derived from Illumina sequencing spore preps.
There are 81 more genomes that we put public in NCBI that were derived from Illumina sequencing spore preps.
• • •
Missing some Tweet in this thread? You can try to
force a refresh