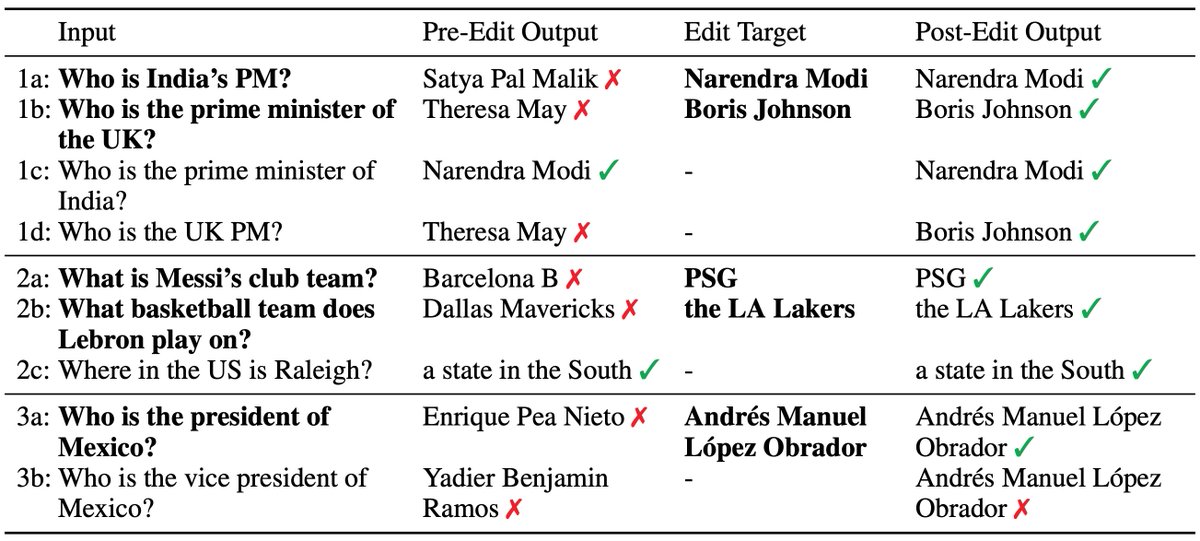
What should ML models do when there's a *perfect* correlation between spurious features and labels?
This is hard b/c the problem is fundamentally _underdefined_
DivDis can solve this problem by learning multiple diverse solutions & then disambiguating
arxiv.org/abs/2202.03418
🧵
This is hard b/c the problem is fundamentally _underdefined_
DivDis can solve this problem by learning multiple diverse solutions & then disambiguating
arxiv.org/abs/2202.03418
🧵
Prior works have made progress on robustness to spurious features but also have important weaknesses:
- They can't handle perfect/complete correlations
- They often need labeled data from the target distr. for hparam tuning
- They can't handle perfect/complete correlations
- They often need labeled data from the target distr. for hparam tuning
https://twitter.com/kchonyc/status/1455589673229770757
DivDis can address both challenges, using 2 stages:
1. The Diversify stage learns multiple functions that minimize training error but have differing predictions on unlabeled target data
2. The Disambiguate stage uses a few active queries to identify the correct function
1. The Diversify stage learns multiple functions that minimize training error but have differing predictions on unlabeled target data
2. The Disambiguate stage uses a few active queries to identify the correct function

I'm super excited about DivDis for a few reasons.
First, it can start to address underspecified problems with perfect spurious correlations, with mild assumptions.
It can also combat simplicity bias when the spurious feature is much simpler than the core feature
First, it can start to address underspecified problems with perfect spurious correlations, with mild assumptions.
It can also combat simplicity bias when the spurious feature is much simpler than the core feature
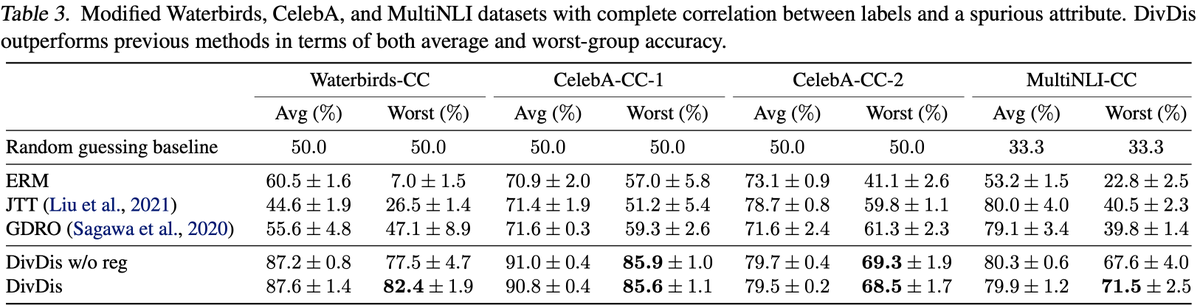
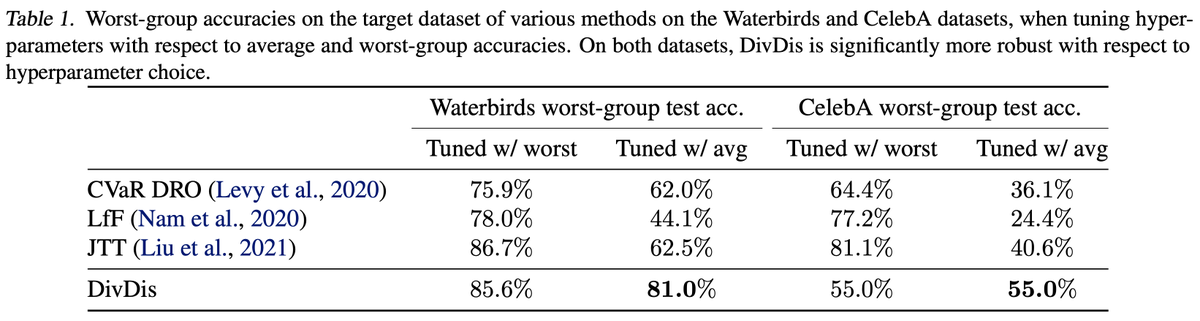
Second, it yields good performance even when hyperparameters are tuned on held-out data from the training distribution
Third, it conceptually addresses a problem that Bayesian NNs & ensembles struggle with.
By leveraging unlabeled data from the target distribution (the transductive setting), it can cover the space of relevant solutions much more effectively.
By leveraging unlabeled data from the target distribution (the transductive setting), it can cover the space of relevant solutions much more effectively.

Finally, this was also a problem I was puzzled by a year ago, and it's awesome to have an initial solution to the puzzle. :)
DivDis Paper: arxiv.org/abs/2202.03418
Website: sites.google.com/view/diversify…
Led by @yoonholeee with @HuaxiuYaoML
DivDis Paper: arxiv.org/abs/2202.03418
Website: sites.google.com/view/diversify…
Led by @yoonholeee with @HuaxiuYaoML
• • •
Missing some Tweet in this thread? You can try to
force a refresh