🎉Sentence-Transformers v2.2.0 released:
💬 T5 added for computing embeddings
💾 Sentence-T5 and GTR models in PyTorch on @huggingface model hub
🔒 Loading private models from @huggingface hub
github.com/UKPLab/sentenc…
💬 T5 added for computing embeddings
💾 Sentence-T5 and GTR models in PyTorch on @huggingface model hub
🔒 Loading private models from @huggingface hub
github.com/UKPLab/sentenc…
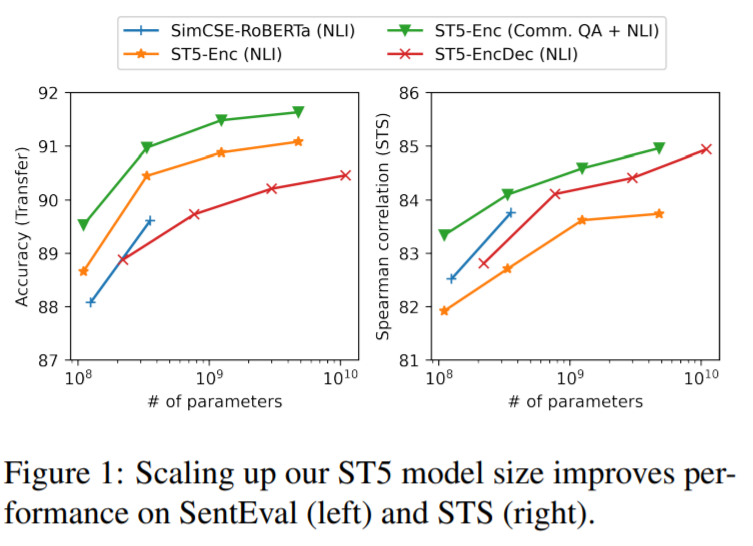
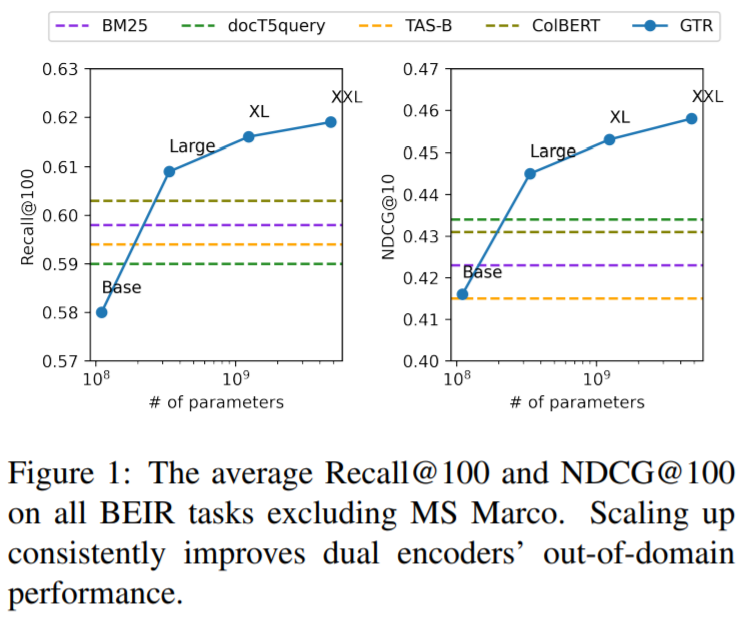
Sentence-T5 (arxiv.org/abs/2108.08877) and GTR (arxiv.org/abs/2112.07899) are two recent dense embedding models by @GoogleAI trained on 2B community Q&A pairs. I converted these models to PyTorch:
huggingface.co/sentence-trans…
huggingface.co/sentence-trans…
huggingface.co/sentence-trans…
huggingface.co/sentence-trans…
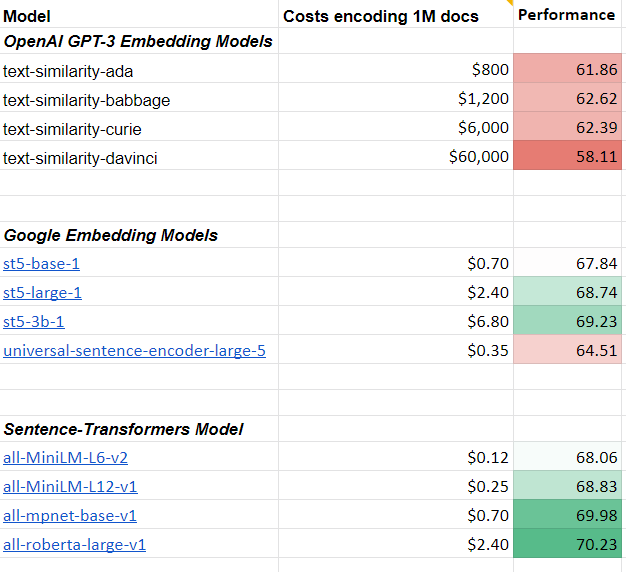
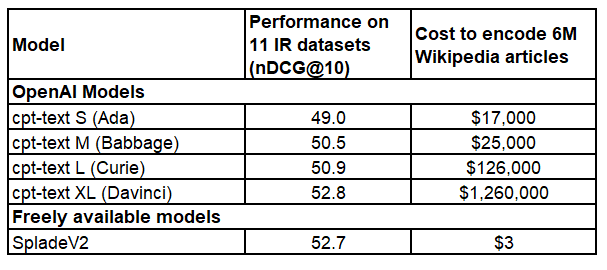
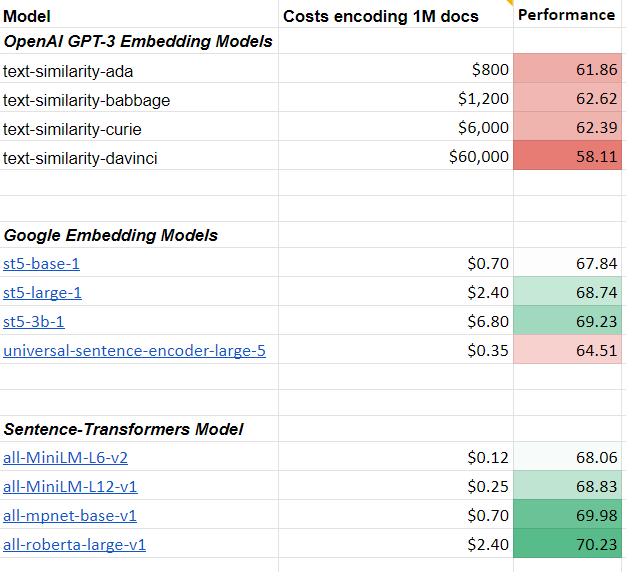
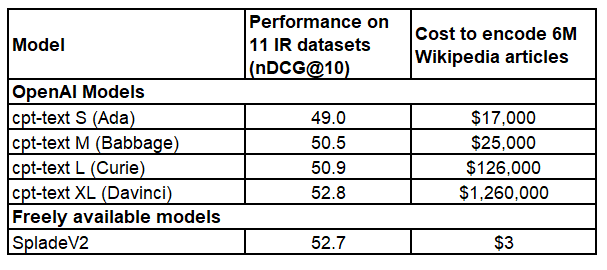
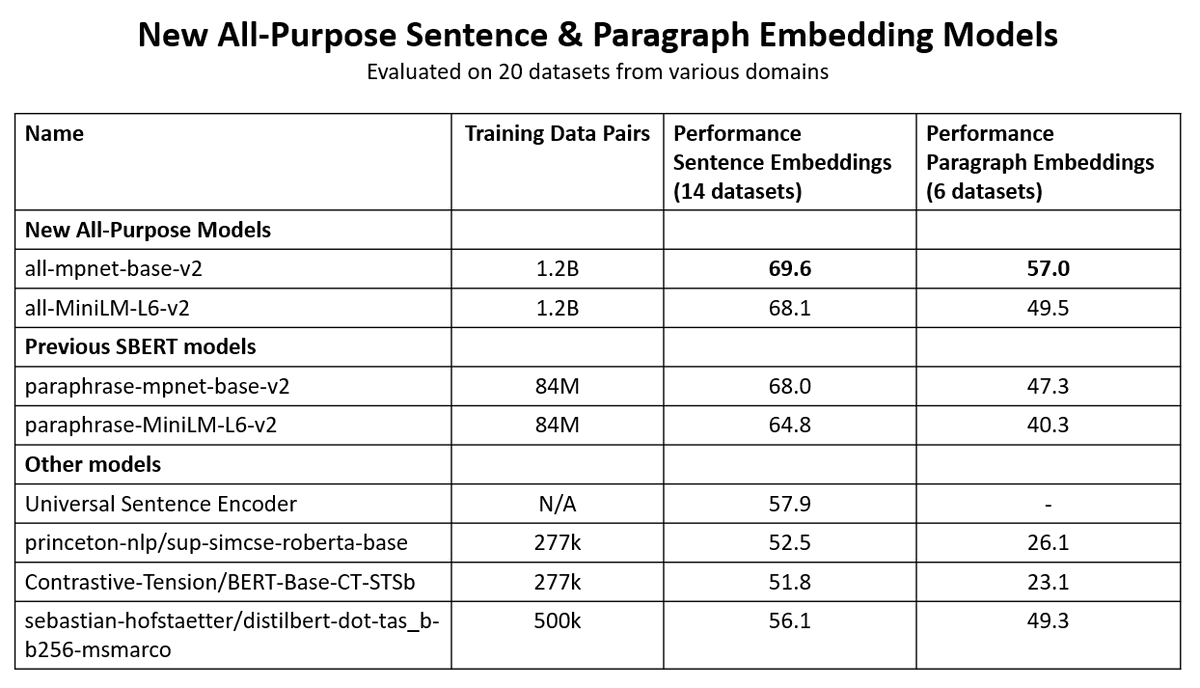
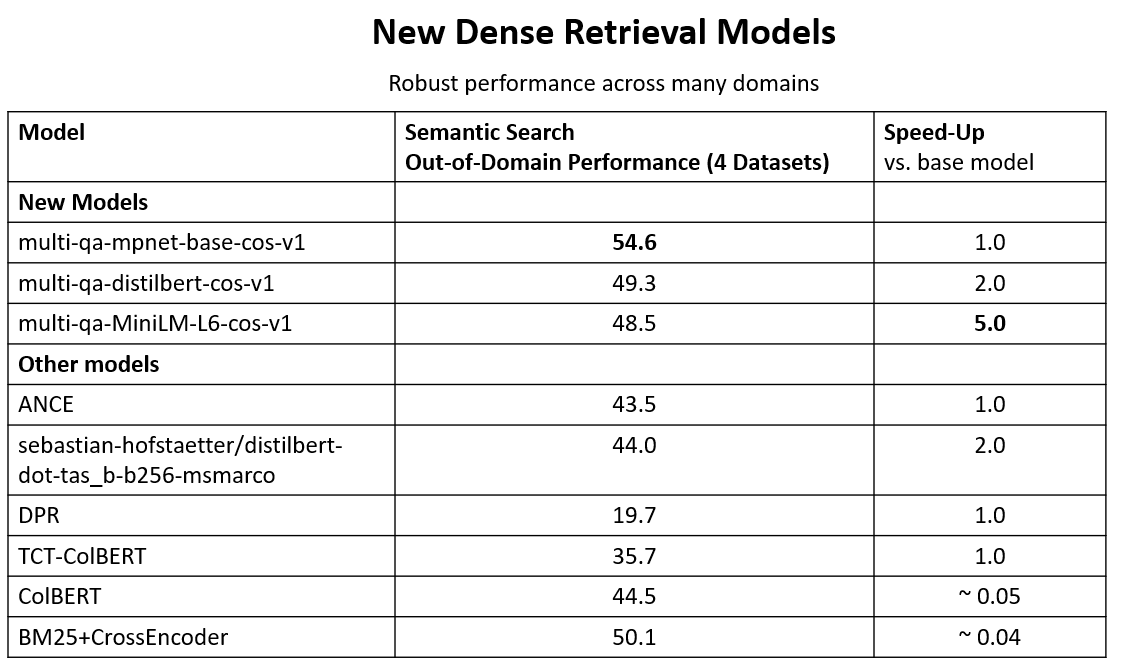
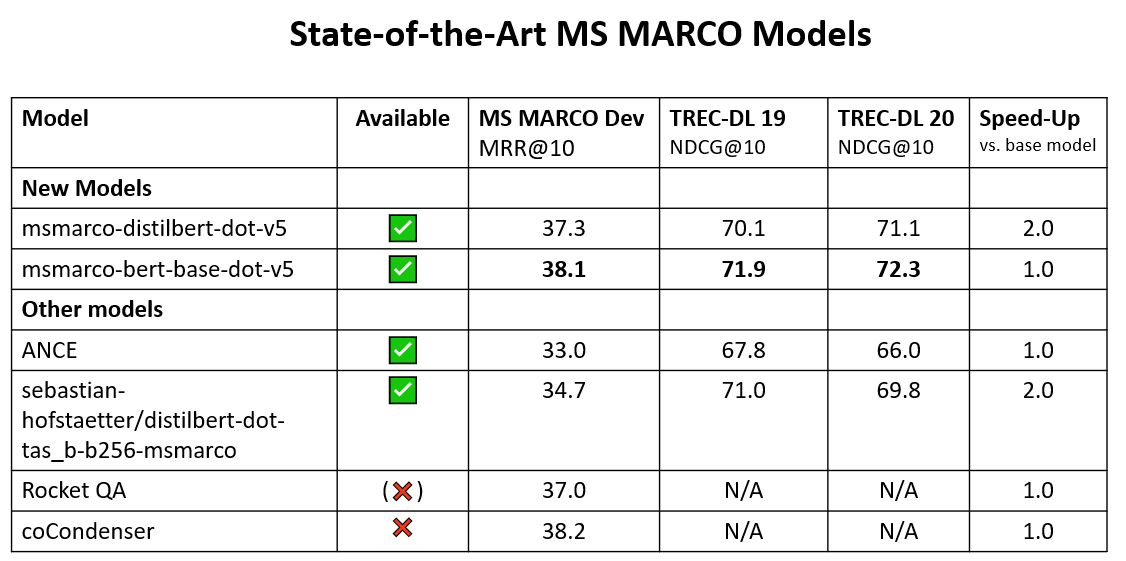
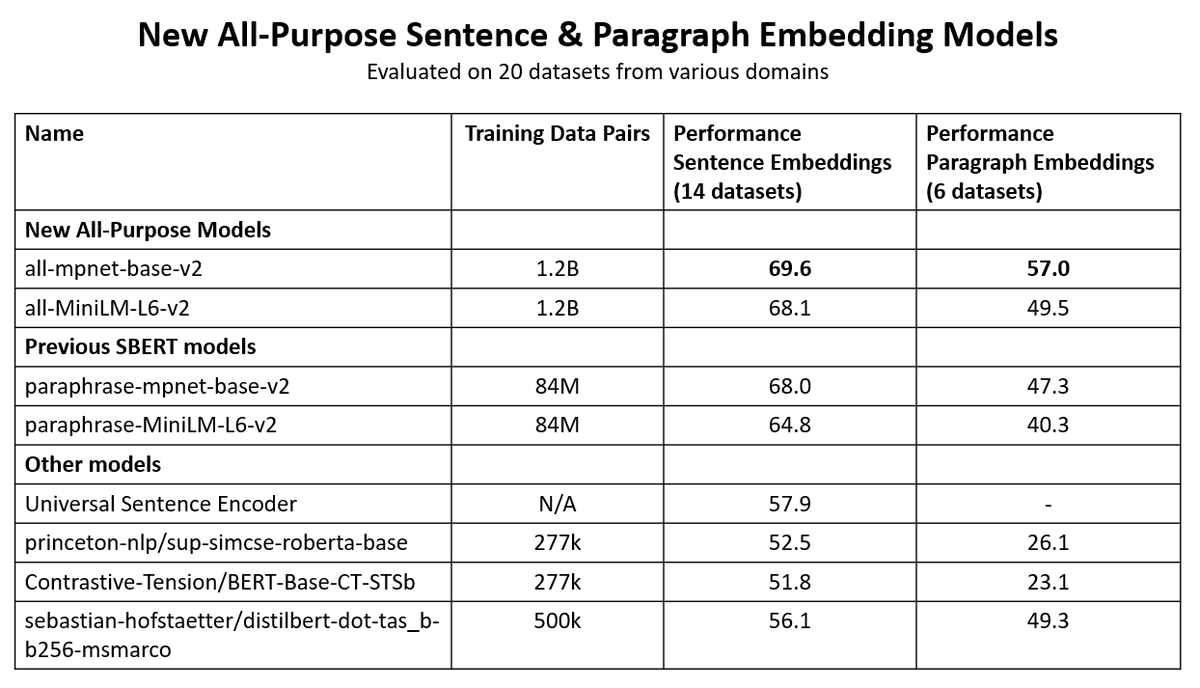
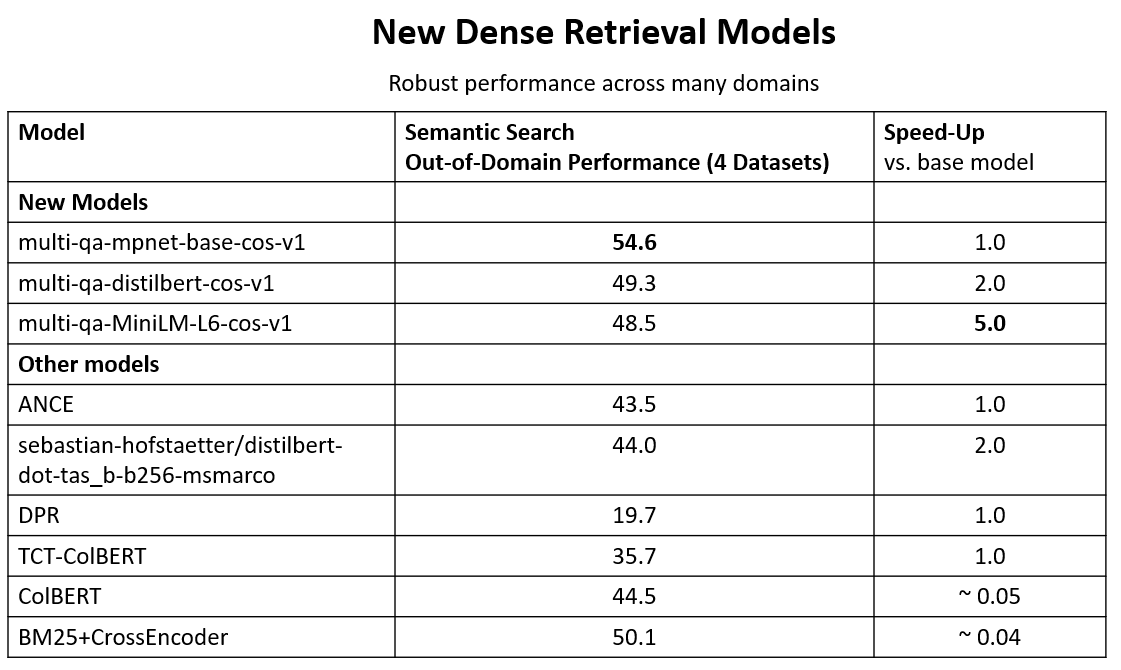
📈How well does sentence-T5 / GTR perform?
🥇On sentence tasks, the XXL models were able to set a new state-of-the-art. Sadly they are quite slow
🥈On semantic search tasks (given query, find relevant passages), better and faster models exist
🥇On sentence tasks, the XXL models were able to set a new state-of-the-art. Sadly they are quite slow
🥈On semantic search tasks (given query, find relevant passages), better and faster models exist
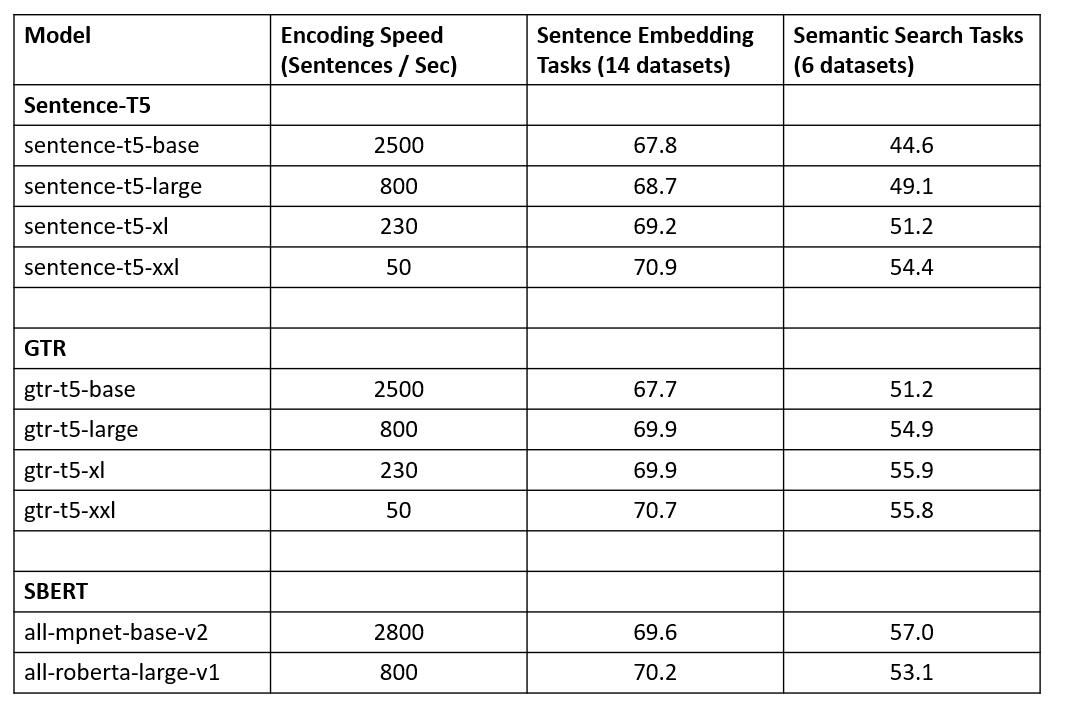
Sentence-T5 and GTR have been trained on:
📁large datasets (2B pairs)
🖥️A lot compute power (2048 batch size)
❓But how does T5 compare if training is comparable?
I testedT5-base & T5 v1.1.-base vs encoder-only models in a comparable setting (same training data & compute):
📁large datasets (2B pairs)
🖥️A lot compute power (2048 batch size)
❓But how does T5 compare if training is comparable?
I testedT5-base & T5 v1.1.-base vs encoder-only models in a comparable setting (same training data & compute):
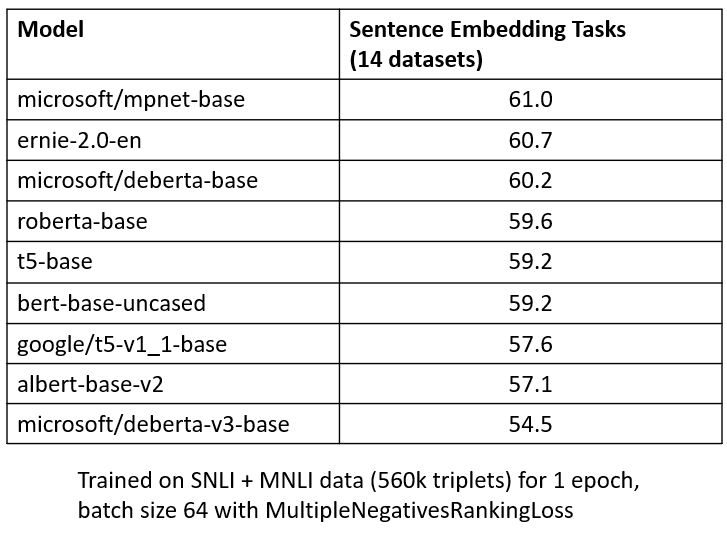
T5 encoders require quite many training steps before producing good text embeddings.
🐁 Small datasets: T5 is quite bad
🐕 Medium datasets: T5 catches up, but not as good as encoder-only models
🐘 Large datasets: Still unknown if T5 or mpnet-base is better
🐁 Small datasets: T5 is quite bad
🐕 Medium datasets: T5 catches up, but not as good as encoder-only models
🐘 Large datasets: Still unknown if T5 or mpnet-base is better
🔒Private models on @huggingface hub
🕵️Simply upload your sentence-transformer model to the HF hub and mark it private. Only you will have access to it.
Load your model with:
model = SentenceTransformer("your-username/your-model", use_auth_token=True)
🕵️Simply upload your sentence-transformer model to the HF hub and mark it private. Only you will have access to it.
Load your model with:
model = SentenceTransformer("your-username/your-model", use_auth_token=True)
• • •
Missing some Tweet in this thread? You can try to
force a refresh