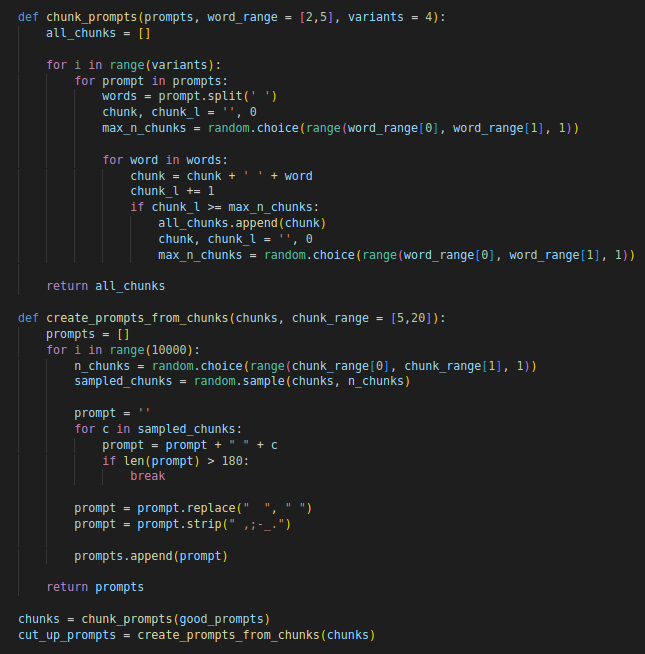
I discovered a bug in my own Diffusion + CLIP pipeline and suddenly the samples are unreal.. 🤯
Here's
"Just a liquid reality..."
#AIart #notdalle2 #Diffusion #clip
Here's
"Just a liquid reality..."
#AIart #notdalle2 #Diffusion #clip

"The magnificent portal of mother Gaia"

"Framing reality"

"Gathering at the great elder sphere"

"Why such a rush? It's all twisting and bending anyway"

"My hair is a living creature"

Caveat: all these pieces are the result of a tremendous amount (months) of code and parameter tuning, careful selection of initialization images, prompt engineering and cherry picking.
#dalle2 is incredible at compositionality and realism, but I haven't seen it do this yet👨🎨🧙♂️😋
#dalle2 is incredible at compositionality and realism, but I haven't seen it do this yet👨🎨🧙♂️😋
• • •
Missing some Tweet in this thread? You can try to
force a refresh