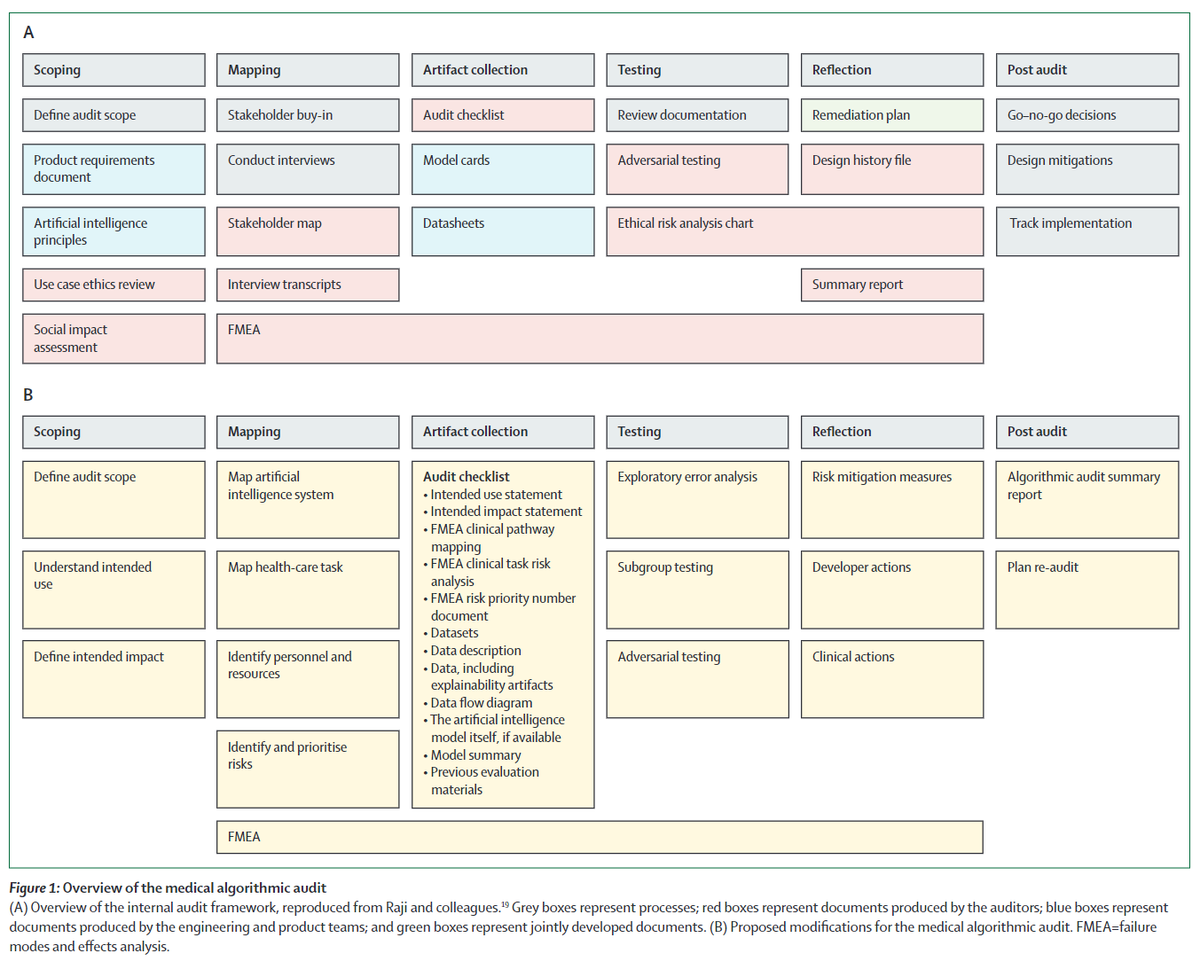
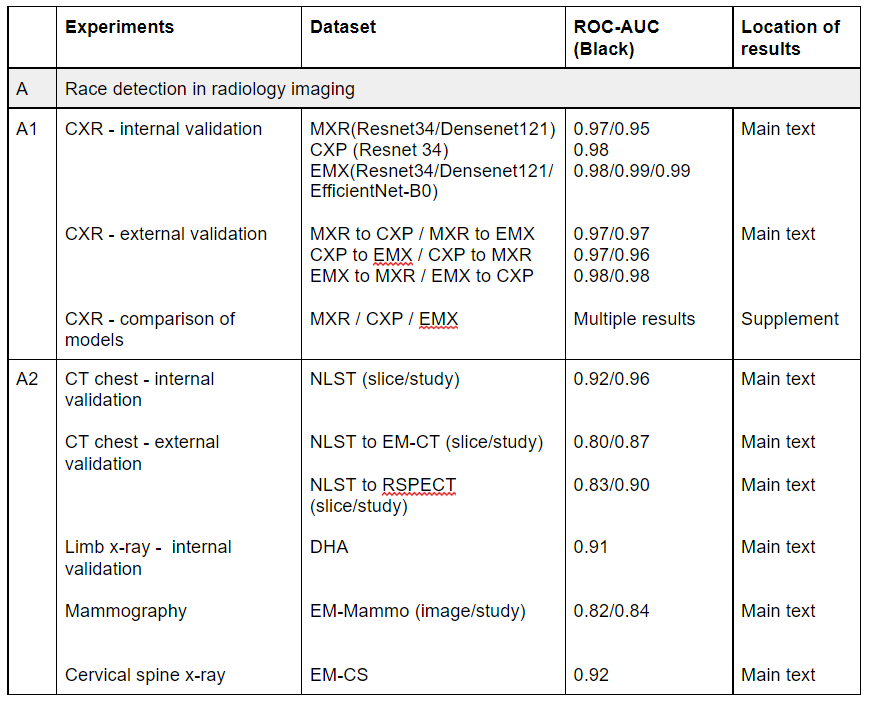
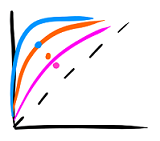
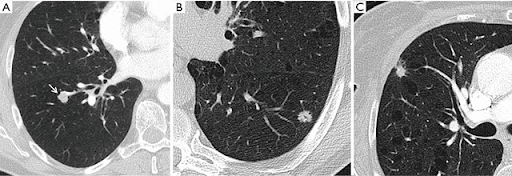
This week an #AI model was released on @huggingface that produces harmful + discriminatory text and has already posted over 30k vile comments online (says it's author).
This experiment would never pass a human research #ethics board. Here are my recommendations.
1/7
This experiment would never pass a human research #ethics board. Here are my recommendations.
1/7
https://twitter.com/ykilcher/status/1532751551869108227


@huggingface as the model custodian (an interesting new concept) should implement an #ethics review process to determine the harm hosted models may cause, and gate harmful models behind approval/usage agreements.
Medical research has functional models ie for data sharing.
2/7
Medical research has functional models ie for data sharing.
2/7

Open science and software are wonderful principles but must be balanced against potential harm. Medical research has a strong ethics culture bc we have an awful history of causing harm to people, usually from disempowered groups.
See en.wikipedia.org/wiki/Medical_e… for examples.
3/7
See en.wikipedia.org/wiki/Medical_e… for examples.
3/7
Finally I'd like to talk about @ykilcher's experiment here. He performed human experiments without informing users, without consent or oversight. This breaches every principle of human research ethics.
4/7
4/7
Imagine the ethics submission!
Plan: to see what happens, an AI bot will produce 30k discriminatory comments on a publicly accessible forum with many underage users and members of the groups targeted in the comments. We will not inform participants or obtain consent.
5/7
Plan: to see what happens, an AI bot will produce 30k discriminatory comments on a publicly accessible forum with many underage users and members of the groups targeted in the comments. We will not inform participants or obtain consent.
5/7
AI research has just as much capacity to cause harm as medical research, but unfortunately even small attempts to manage these risks (such as @NeurIPSConf #ethics code of conduct: openreview.net/forum?id=zVoy8…) are bitterly resisted by even the biggest names in AI research.
6/7
6/7
Twitter ate my original thread so I'm one tweet short and don't know what I missed. Sorry.
7/7
7/7
UPDATE: @huggingface has removed the model from public access and will implement a gating feature.
Furthermore they are doing for community feedback on an appropriate ethics review mechanism. This is really important so please engage with this.
Furthermore they are doing for community feedback on an appropriate ethics review mechanism. This is really important so please engage with this.
https://twitter.com/ClementDelangue/status/1533921438922682381?t=TUXjnC04wBKD6fyr3zIv4Q&s=19
@huggingface should implement gated access to prevent harmful misuse of this model and others like it. Open science and software are great principles, but must be balanced against the risk of real harm. Medical research has functional models for this ie for data sharing.
2/7
2/7
Furthermore, @huggingface (as the model custodian, which is an interesting new concept) should be responsible to assess which models pose a risk. An internal review board process should be set up, with model authors required to submit a summary of risk for their models.
3/7
3/7
Additionally, I want to discuss @ykilcher's choice to perform an experiment on human participants without #ethics board approval, consent, or even their knowledge. This breaches every principle of human research ethics.
This has implications for AI research as a field.
4/7
This has implications for AI research as a field.
4/7
Imagine the ethics proposal!
Plan: an AI bot which will post 30k+ discriminatory comments on a publically accessible forum often populated by underage users, including members of the marginalised groups the comments target. We will not inform them or ask for consent.
5/7
Plan: an AI bot which will post 30k+ discriminatory comments on a publically accessible forum often populated by underage users, including members of the marginalised groups the comments target. We will not inform them or ask for consent.
5/7
Medical research has strong ethics framework for a reason. We have a disgusting history of causing harm, particularly to disempowered people. See en.wikipedia.org/wiki/Medical_e… for examples.
AI has an equal capacity for harm, and this experiment was not uniquely harmful.
6/7
AI has an equal capacity for harm, and this experiment was not uniquely harmful.
6/7
AI research desperately needs a ethical code of conduct, but even small steps like those taken by @NeurIPSConf (openreview.net/forum?id=zVoy8…) are bitterly fought against, by some of the most prominent researchers in the field.
AI researchers, do better. Please.
7/7
AI researchers, do better. Please.
7/7
• • •
Missing some Tweet in this thread? You can try to
force a refresh