If anyone didn't get what I meant when I said @ykilcher chose to "kick the hornets nest" or if anyone was wondering about the cost of speaking out against unethical behaviour in #AI, here's a little summary of my recent twitter feed.
CW: transphobia

CW: transphobia
https://twitter.com/DrLaurenOR/status/1533556511913689088
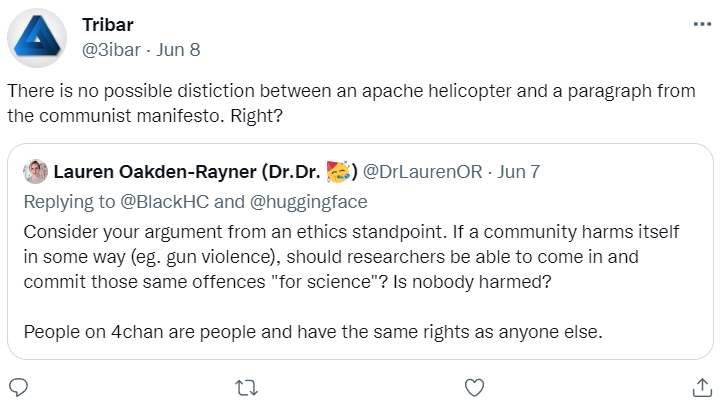


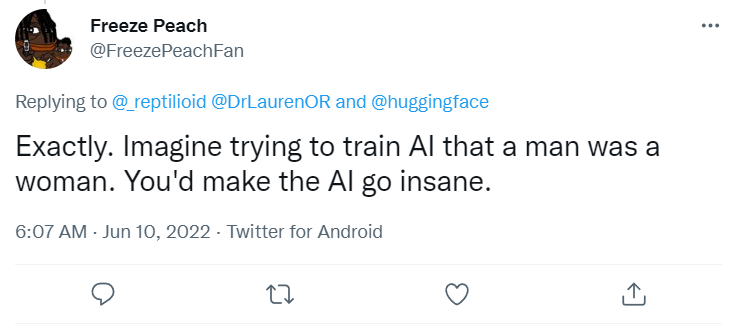
Here's some more. If anyone doesn't understand why all these statements are explicitly transphobic ... well, it is because you don't face it. These are all extremely hurtful.
That's enough, but I've skipped all the misogyny, racism, anti-semitism etc.
That's enough, but I've skipped all the misogyny, racism, anti-semitism etc.




This isn't isolated. Another commentator on this stunt has needed to take some time off Twitter due to the reaction.
I honestly spent several days deciding to post on this, because I knew what would happen. It was important, but there is always a cost.
I honestly spent several days deciding to post on this, because I knew what would happen. It was important, but there is always a cost.
https://twitter.com/_joaogui1/status/1534641891853082626
This behaviour and response was predictable. An unbroken causal chain from Yannic to me.
Which is perhaps unsurprising, given that he doesn't seem to think that hate-speech is harmful, that it is "just insults", and "something you simply don't like".
Which is perhaps unsurprising, given that he doesn't seem to think that hate-speech is harmful, that it is "just insults", and "something you simply don't like".
https://twitter.com/DrLaurenOR/status/1533920698414276608
All things an ethics board shouldn't have to consider, but might have needed to.
"You are trolling an extremely toxic community and are likely to get publicly criticised on ethical grounds. Have you considered the risk you may mobilise an army of bigots against your colleagues?"
"You are trolling an extremely toxic community and are likely to get publicly criticised on ethical grounds. Have you considered the risk you may mobilise an army of bigots against your colleagues?"
This tweet really resonated with me. It's always people from minoritised groups that need to perform "non-consensual maid-ery" and face the repercussions.
https://twitter.com/mmitchell_ai/status/1534606991347224577
• • •
Missing some Tweet in this thread? You can try to
force a refresh